


4 月 29 日写 SmartPerfetto 开源介绍时,重点还是“在 Perfetto UI 里放一个能查 SQL、跑 Skill、生成报告的 AI Assistant”。两周后的仓库状态已经变了不少:功能从单条 trace 的问答,扩到了分析结果复用、多 trace 横向比较、Claude/OpenAI 双 runtime、SQL guardrail、证据来源索引、免安装包、渲染管线教学和更完整的 Provider 诊断。
本文基于 2026 年 5 月 17 日的 SmartPerfetto 当前仓库状态,补一篇新的功能说明。读者看完应该能知道三件事:这两周新增了什么、现在完整功能边界在哪里、报 bug 时该提供哪些信息。
项目地址:
- SmartPerfetto 主仓库:https://github.com/Gracker/SmartPerfetto
- 上一篇开源介绍:https://www.androidperformance.com/2026/04/29/SmartPerfetto-Open-Source-Perfetto-AI-Assistant/
两周内变化最大的地方
上篇文章里写到的几个数字已经过时。那时仓库里是 165 个 YAML Skill、12 个场景策略;当前仓库状态下,backend/skills/ 已经有 220 个 *.skill.yaml,去掉 _template 后是 216 个功能性 Skill 文件,backend/strategies/ 里有 18 个 .strategy.md 和 26 个 .template.md。
这不是简单地把文件数堆上去。变化主要落在六类用户会感知到的地方:
| 方向 | 之前的主路径 | 当前状态 |
|---|---|---|
| Trace 分析 | 单条 trace 上提问、跑 Skill、看报告 | 保留原路径,并增加选区追问、结果快照、跨窗口结果对比 |
| 多 Trace 对比 | 当前窗口选择 reference trace,偏实时 | 新增分析结果 snapshot,对比已完成结果,不要求另一个窗口继续打开 |
| 模型接入 | Claude Agent SDK 是主路径 | Claude Agent SDK 与 OpenAI Agents SDK 都是一等 runtime |
| Provider 配置 | 主要靠 .env 和 README 说明 |
UI Provider Manager、active profile、env fallback、/health 诊断一起工作 |
| 证据可靠性 | 主要依赖 prompt 约束模型写 SQL 和引用证据 | SQL stdlib guardrail、最终可执行 SQL、证据 ID、数据来源说明、逐句数据引用进入 contract |
| 运行分发 | Docker 和本地源码为主 | Docker、Windows/macOS/Linux 免安装包、本地源码、CLI/API 都进入文档和发布流程 |
过去两周还修了一批影响可用性的边界问题:大 trace 上传限制提升到 5 GiB,并增加 admission 和磁盘预检查;启动脚本会清理孤儿 trace_processor_shell 并自动打开浏览器;Linux glibc、IPv6-disabled host、Claude SDK native binary 选择、Docker env provider 优先级、OpenAI/MiMo tool calling 兼容性、Perfetto frontend 预构建资产校验都做了修复。
这类修复看起来不像新功能,但它们决定了普通用户能不能把第一条真实 trace 跑完。
当前完整功能地图
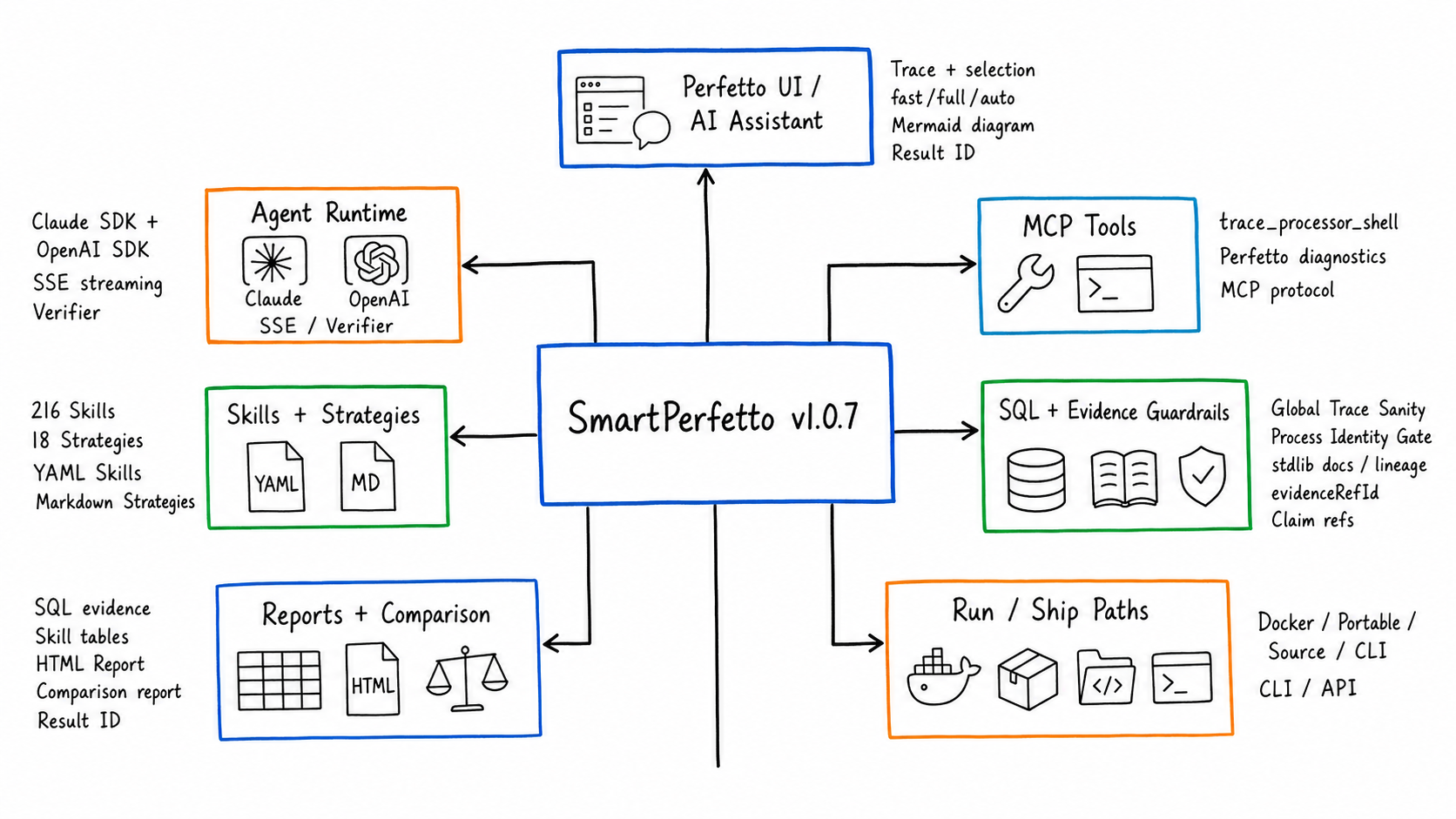
SmartPerfetto 现在可以按“入口、分析、证据、输出、运行方式”五层理解。
| 功能面 | 当前能力 | 适合场景 |
|---|---|---|
| Perfetto UI 内 AI Assistant | 加载 .pftrace / .perfetto-trace 后直接提问,支持 fast、full、auto 三种分析模式 |
日常看 trace,快速问包名、进程、启动、滑动、ANR |
| 选区和事件上下文 | Perfetto area selection / track event selection 会作为 selectionContext 传给后端 |
只分析某段时间、某一帧、某个可疑 slice 前后发生了什么 |
| 常见场景策略 | 18 个策略覆盖 startup、scrolling、ANR、interaction、touch、memory、power、network、media、game、pipeline、teaching、overview 等场景 | 把自然语言问题路由到合适的 SQL、Skill 和输出格式 |
| YAML Skill 系统 | 216 个功能性 Skill 文件,覆盖 atomic、composite、deep、pipeline、comparison、module 等类型 | 把 Perfetto SQL、显示列、分层结果和边界处理写成可复用分析单元 |
| SQL 与 Skill 证据 | 结果里保留 SQL、Skill 表格、时间戳、线程、slice、metric 来源 | 把“模型判断”落回 trace 数据,方便复核 |
| SQL guardrail 与 stdlib 知识库 | raw SQL 自动补齐 stdlib include,Skill validator 检查 table/function/macro 依赖,SQL 展示/复制使用最终可执行 SQL | 降低 SQL 因 Perfetto stdlib 迁移、缺 include 或 unsafe create 造成的误判 |
| 全局 Trace Sanity | global_trace_sanity_check 汇总最长 slice、D 状态、Runnable 等待、Runqueue 压力和 CPU 热点进程 |
开始场景分析前先看全局瓶颈,避免只盯住单个线程或单个 Skill |
| 证据来源索引 | DataEnvelope 带 evidenceRefId、traceSide、sourceToolCallId、plan phase、producer reason,报告支持逐句数据引用 |
追问“这个数字从哪张表哪一行来”时,有稳定 ID 和行列信息 |
| HTML 分析报告 | 每次分析完成后生成报告,通用接口 /api/reports/:reportId 可读取 |
分享给团队、贴到 issue、留作回归记录 |
| Trace 实时对比 | compare_arrows 入口选择 reference trace,在同一轮 AI 分析里查询 current/reference |
两条 raw trace 都可访问,想临时比较当前窗口与参考 trace |
| 多 Trace 分析结果对比 | fact_check 入口选择 baseline/candidates,或直接输入 Result ID |
对比已经完成的多次分析结果,适合 A/B 测试、版本回归、多人协作 |
| Provider Manager | UI 里创建、编辑、激活 provider profile,active profile 优先于 env fallback | 多模型、多 provider、多协议测试,不想反复改 .env |
| 双 SDK runtime | claude-agent-sdk 与 openai-agents-sdk 分开接入,支持 Anthropic/Claude-compatible、OpenAI/Ollama/OpenAI-compatible |
根据 provider 的真实协议能力选择 runtime |
| 渲染管线教学 | 基于当前 trace 观测到的 App、RenderThread、Producer、SurfaceFlinger/HWC 事件生成教学结果 | 学习 Android 出图路径,并把静态知识对回本次 trace |
| 上游 Perfetto 诊断产品化 | heap graph、bitmap heap metadata、critical blocking calls、lock contention owner、Chrome scroll jank frame timeline 等进入 YAML Skill | 把 upstream Perfetto 的分析经验转成 SmartPerfetto 可执行证据 |
| Mermaid 展示 | AI Assistant 默认展开 Mermaid 源码块,优化渲染样式,支持点击放大预览 | 报告里出现流程图、因果图、对比图时可读性更好 |
| API / CLI / MCP | 后端 REST + SSE、@gracker/smartperfetto CLI、MCP 工具文档 |
接入脚本、CI、内部平台,或直接在终端分析 trace |
| 运行与分发 | Docker Hub、本地源码 ./start.sh、Windows EXE、macOS App、Linux tarball |
不同用户按环境选择最少依赖路径 |
| 企业/多租户基础 | tenant/workspace、RBAC、provider isolation、scoped trace/report metadata、runtime dashboard、lease supervisor 等已经进入主干 | 团队部署和商业支持的基础能力;大规模外部 RSS/load 实测仍按文档标记为后续验证项 |
这里最该强调的是证据边界。SmartPerfetto 不会把整个 trace 文件塞进 prompt。模型接触到的是后端工具返回的 SQL 结果、Skill 输出、报告摘要和结构化上下文。性能数字仍来自 trace_processor_shell 和 Skill 里的确定性计算。
新功能一:多 Trace 分析结果对比
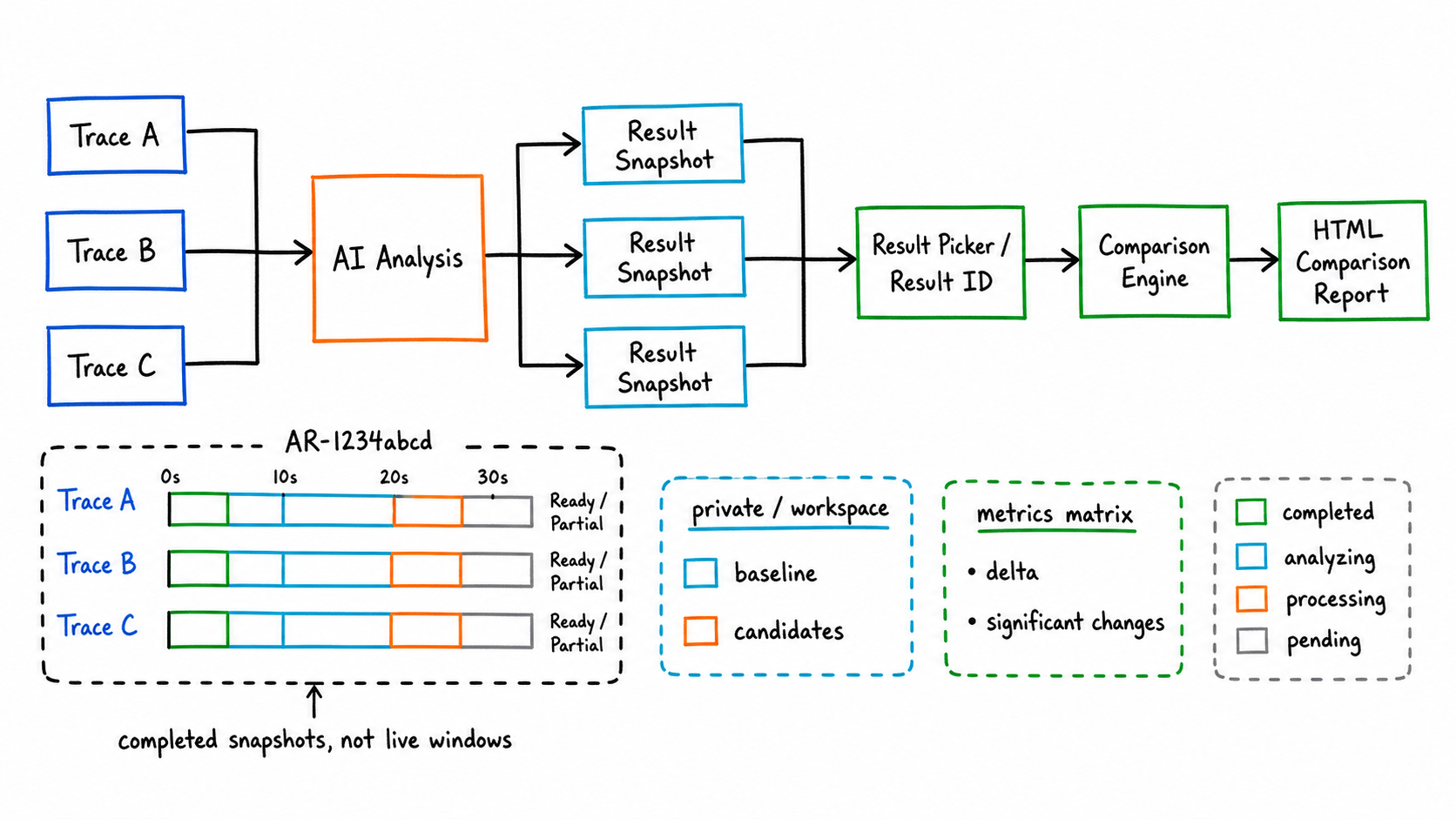
旧的 Trace 对比更像“当前窗口 + reference trace”的实时分析。这个模式仍然保留,适合在一次对话里让 AI 同时查询两条 raw trace。
新的多 Trace 分析结果对比换了一个对象:它比较的是已经完成的分析结果。每次 AI 分析结束后,SmartPerfetto 会把关键指标、证据引用、结论 contract 和报告入口保存成 analysis result snapshot。UI 顶部出现 Ready result 或 Partial result 时,说明这次分析已经有了可复用结果。
用户有两种入口:
- 直接在 AI 输入框里说
对比一下另外一份、对比 AR-1234abcd,或者对比 AR-11111111 和 AR-22222222。 - 点击顶部
fact_check图标,打开结果选择器,手动选择 baseline 和一个或多个 candidates。
这个功能解决的问题不在于同时打开两条 trace,而在于复用已经完成的分析结果。它不要求另一个 Perfetto UI 窗口继续打开,也支持同一个 workspace 内共享结果。默认结果是 private;用户显式共享后,同 workspace 用户可以把它作为候选结果参与对比。
输出分两层:
- 聊天消息里给出 Comparison ID、baseline/candidates、显著变化数量和前几行关键指标。
- HTML comparison report 展开标准指标、delta、输入 snapshot、显著变化和 AI 结论。
当前标准化指标优先覆盖启动耗时、FPS、Jank、慢帧等可比较项。缺指标时,后端会尝试回填;回填失败也会完成对比,但会标出缺失原因。
这对性能回归很有用。一次启动优化、一次滑动手感调整、一次不同机型复测,都可以在各自 trace 上先完成 AI 分析,再把结果放到同一个 comparison report 里看差异。
新功能二:SQL、证据来源和上游诊断能力
最近新增内容里最需要补充的一块,是 SmartPerfetto 对证据来源的处理。用户看到的仍然是对话、表格和报告,内部多了三层 contract:SQL 怎么变成最终可执行版本、表格/摘要从哪个工具调用产生、结论里的数值该回到哪一行证据。
第一层是 SQL guardrail。execute_sql、execute_sql_on、raw SQL auto include 和 Skill validator 现在共用同一套 stdlib dependency analyzer,识别 SQL 里的 table、function、macro 和 INCLUDE PERFETTO MODULE。这带来几个直接收益:
- raw SQL 引用了 Perfetto stdlib 表或函数时,后端会尽量自动补齐需要的 module。
- Skill validator 会检查 Skill 里声明的
prerequisites.modules是否覆盖实际 SQL 用到的 stdlib table/function/macro。 - guardrail 会检查低噪声 SQL 风险,例如可重复执行的
CREATE、SPAN_JOIN安全写法、直接解析args表等。 - AI Assistant 展示和复制 SQL 时使用最终可执行 SQL,并经过 syntaqlite formatter;formatter 失败时降级到原 SQL,不阻断分析。
边界也要写清楚:当前 guardrail 是工程 contract,不是完整 Perfetto SQL AST parser。它能降低高频误判,不能证明所有未来 Perfetto SQL 语法都被静态覆盖。
第二层是 stdlib docs 与 lineage 知识库。仓库新增了 backend/data/perfettoSqlDocs.json,由 upstream stdlib_docs.json 生成 module、entity、direct/transitive includes 和可选 pfsql lineage 状态。lookup_sql_schema、list_stdlib_modules、query_perfetto_source 可以把官方 stdlib 文档、include 关系和源码搜索结果一起返回给 Agent。这样模型写 SQL 前不再只靠记忆,也不需要把所有 stdlib 细节硬写进 prompt。
第三层是数据来源索引。SQL 和 Skill 产生的 DataEnvelope 可以携带 evidenceRefId、traceSide、traceId、queryHash、sourceToolCallId、paramsHash、plan phase、toolNarration 和 producerReason。HTML report 和 analysis result snapshot 会保留这些字段。当前报告 contract 还加入了“逐句数据引用(结构化来源)”:结论里出现关键数值、线程名、进程名、帧数或百分比时,可以把它映射到 evidence_ref_id、source_ref、row_index / row_selector、column 和 value。
快速回答也接入了同一套格式。内部会先用未清理的结论文本派生 conclusion contract,保留机器可读的 evidence id,再生成给用户看的清理版文本。analysis result snapshot 会持久化这个 contract,后续做多 Trace 对比或回看报告时,来源引用不会因为前端展示清理而丢掉。
这件事对排错很实用。用户不需要只说“AI 结论不对”,可以指向 Q1、某个 evidenceRefId、某个 Result ID、某张表的某一列,维护者也能判断问题在 SQL、Skill、trace 数据源、模型总结还是报告渲染。
这轮还把一批 upstream Perfetto 诊断经验产品化到 YAML Skill:
| 能力 | SmartPerfetto 落点 | 用户价值 |
|---|---|---|
| 全局 Trace Sanity | global_trace_sanity_check |
开始分析前先看最长 slice、D 状态、Runnable 等待、Runqueue 压力和 CPU 热点进程 |
| 进程身份确认 | process_identity_resolver 和 process identity gate |
避免同名进程、多进程 App、provider 进程导致 Skill 查错目标 |
| Heap / Bitmap | android_heap_graph_summary、android_bitmap_memory_per_process |
有 heap graph / bitmap 表时输出对象和 bitmap 维度;没有数据时明确降级 |
| Blocking calls | frame_blocking_calls |
区分 MainThread、RenderThread、Binder 等 thread role,并保留阻塞来源 |
| Lock contention | lock_contention_in_range、lock_contention_analysis |
输出 blocked thread、owner thread、owner TID、callsite 和 overlap duration |
| Chrome Scroll Jank | chrome_scroll_jank_frame_timeline |
覆盖 Chrome v3/v4 scroll jank、tagging 和 preferred frame timeline availability |
这些能力不改变 SmartPerfetto 的基本原则:模型负责解释和排序,数值仍来自 trace_processor_shell、SQL、Skill 和报告里可追溯的数据来源。
新功能三:Provider Manager 与双 runtime
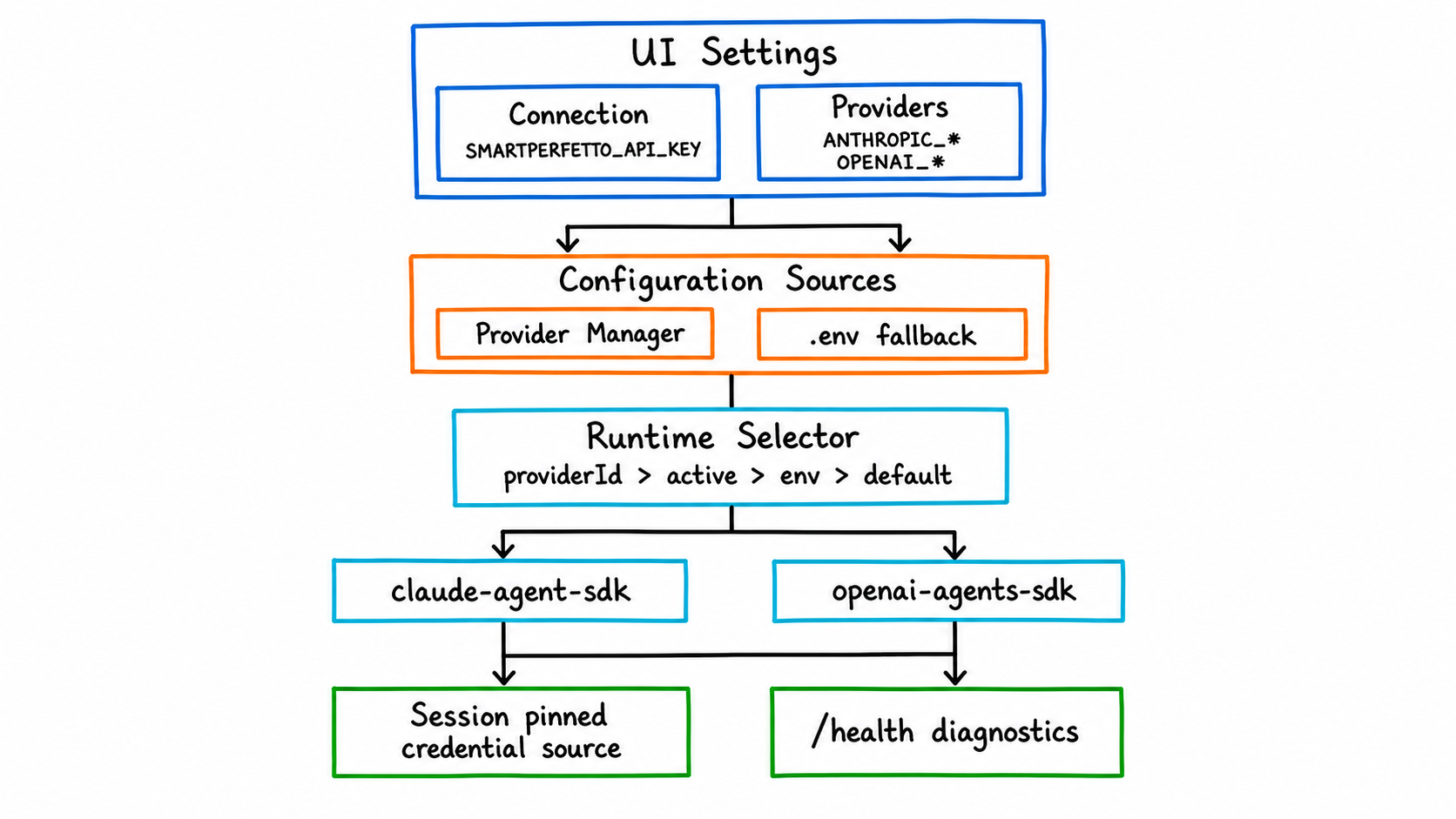
SmartPerfetto 的模型配置现在有三条边界:
Connection配 SmartPerfetto 后端地址和可选的SMARTPERFETTO_API_KEY,它不是模型厂商 key。Providers配模型 provider profile,包括 Base URL、API key/token、模型 ID、协议类型。- runtime 决定后端用哪个 SDK 编排工具调用:
claude-agent-sdk或openai-agents-sdk。
运行时选择优先级是:
| 优先级 | 来源 |
|---|---|
| 1 | 请求或会话里的 providerId |
| 2 | Provider Manager 当前 active provider |
| 3 | .env 中的 SMARTPERFETTO_AGENT_RUNTIME |
| 4 | 默认 claude-agent-sdk |
Claude Agent SDK 适合 Anthropic、Claude Code 本地认证、Bedrock、Vertex,以及 Anthropic/Claude-compatible provider。OpenAI Agents SDK 适合 OpenAI Responses API、Ollama,以及支持流式 tool/function calling 的 OpenAI-compatible gateway。
Provider Manager profile 优先于 .env fallback。已经创建的分析 session 会固定当时的 credential source;恢复这个 session 时,不会因为后来切换了 active provider 就换到另一个模型。这个约束很重要,因为 trace 分析里的多轮追问依赖前一轮的工具结果和 SDK 会话状态。
排障时不要只看 .env。打开 http://localhost:3000/health,看 aiEngine.runtime、aiEngine.credentialSource、aiEngine.providerMode 和 diagnostics。很多 provider preset 来自公开文档,可能随账号地区、套餐或控制台域名变化。连接失败、流式输出异常、tool call 不稳定时,应先核对 provider 控制台里的 Base URL、模型 ID 和协议类型。
新功能四:渲染管线教学从静态文档转向当前 trace
“出图教学”这两周做了重构。以前更像是检测一个主管线,展示对应 Mermaid、关键 slice 和教学文档。现在目标换成了:基于当前 trace 里真实观测到的事件,展示 App、Framework、RenderThread、Producer、BufferQueue/Transaction、SurfaceFlinger/HWC、present 这些角色之间发生了什么。
新的后端服务会构造 observedFlow:
- lanes 表示当前 trace 中可观测到的角色,例如 app、render_thread、producer、buffer_queue、surfaceflinger、hwc_present。
- events 表示真实 slice/thread/process/layer 事件,带
ts、dur、durMs、evidence source 和可选 frame/layer 关联。 - dependencies 表示可确认的依赖,例如 wakeup 或 critical path。
- completeness 标明缺哪些信号,避免把静态知识伪装成本次 trace 的事实。
这对混合渲染尤其重要。WebView、Flutter、React Native、TextureView、SurfaceView、OpenGL ES、Vulkan、Camera、Video、Game engine 这类 producer 不能简单归到一个“主管线”里。SmartPerfetto 现在会把 host HWUI 和 producer 分开展示,再根据证据说明二者有没有依赖。
教学功能的价值不在于替用户背 Android 出图机制,而是把知识点贴回本次 trace 里的实际事件。用户看完应该能知道:本次 trace 里哪些路径看到了证据,哪些路径因为采集缺口还不能确认。
这两周的可用性修复
新增功能之外,最近的修复主要集中在“真实用户把工具跑起来”这件事上。
| 修复方向 | 用户感知 |
|---|---|
| 5 GiB trace 上传 | 更大的 trace 可以走上传路径;后端先做 admission 和磁盘预检查,避免上传到一半才失败 |
| 启动脚本清理孤儿进程 | 上次异常退出后残留的 trace_processor_shell 不容易占住端口 |
| 本地启动自动打开浏览器 | ./start.sh 跑起来后更接近日常工具体验 |
| Linux glibc / IPv6-disabled host | Ubuntu 20.04、禁用 IPv6 的环境更容易启动 |
| Claude SDK native binary fallback | 可选 native 包选错平台时,后端能走自动 fallback |
| OpenAI/MiMo 兼容性 | 修复 reasoning content、tool 参数、plan phases、startup_slow_reasons 等兼容问题 |
| quick/full session 隔离 | 切换 fast/full/auto 时,轻量上下文和完整上下文不会混用 |
| stale SDK conversation recovery | Claude/OpenAI 会话句柄过期时,后端能恢复或降级,避免第二轮追问直接断掉 |
| process identity gate | Skill 执行前会校验目标进程身份,避免包名、进程名或多进程场景把 SQL 查到错误对象 |
| SQL stdlib guardrail | 缺失 stdlib include、unsafe create、SPAN_JOIN 和 args 解析问题能在 validator 或 guardrail 阶段暴露 |
| 跨窗口结果对比 | 多窗口下的结果选择、heartbeat、Result ID 使用更稳定 |
| backend trace_processor 隔离 | 本地 trace 和 backend-created trace processor target 分开处理,降低第二条 trace 错用目标的概率 |
| frontend prebuild 资产守卫 | syntaqlite-*、trace_processor.wasm、trace_processor_memory64.wasm、manifest hash 进入校验,降低免安装包和 Docker 漏资产风险 |
| Mermaid 体验 | 源码默认展开、样式更清楚、图表支持点击放大 |
这些问题很多来自真实 issue 和本地复现。SmartPerfetto 的困难不只在“模型会不会分析”,还在模型、Perfetto UI、后端 SSE、trace_processor_shell、浏览器窗口、provider 协议之间的状态是否一致。任何一个状态漂移,最终都会表现成“AI 结果不可靠”。
现在怎么选运行方式
普通用户优先选 Docker 或免安装包。
| 运行方式 | 适合谁 | 说明 |
|---|---|---|
| Docker Hub | 只想快速试用或部署 | 不需要 Node.js,不需要初始化 submodule;需要在 .env 或 UI Provider Manager 配模型凭证 |
| 免安装包 | 不想安装 Docker 的用户 | Windows 解压双击 SmartPerfetto.exe,macOS 双击 SmartPerfetto.app,Linux 运行 ./SmartPerfetto |
本地源码 ./start.sh |
开发者、想跟主干的人 | 使用仓库提交的预构建 frontend,日常后端/Skill/策略改动不需要构建 Perfetto UI |
Dev 模式 ./scripts/start-dev.sh |
修改 AI Assistant 插件 UI 的人 | 需要初始化 perfetto/ submodule,保存前端代码后 watch 构建 |
CLI smp |
想在终端或脚本里分析 trace 的人 | 复用 agentv3、Skill、报告生成和本地 session 存储 |
源码运行的 Node.js 要求是 24 LTS。仓库有 .nvmrc 和 .node-version,npm 开了 engine-strict=true;./start.sh、./scripts/start-dev.sh、./scripts/restart-backend.sh 会优先通过 nvm/fnm 切到 Node 24。
macOS 免安装包当前采用 ad-hoc signing,避免被系统直接判为 damaged;正式公证仍需要 Developer ID 和 notary profile。这个状态应在发布说明里写清楚,避免用户把 Gatekeeper 行为当作后端问题。
赞助与商业支持
SmartPerfetto 的开源维护成本主要来自四类地方:真实 trace 复现、模型 token、Provider 兼容性验证、跨平台发布包验证。项目接受个人赞助、企业赞助、AI Credits / Token 厂商赞助,也接受围绕 AGPL 的商业授权和企业支持咨询。
个人赞助适合支持开源维护、测试 trace、文档示例和公开 demo 的模型消耗。个人赞助者可以进入 README 的感谢名单;如果赞助者希望匿名,也可以只记录为匿名支持。
普通企业赞助适合支持长期维护、问题复现、公开文档和回归测试。企业赞助者也可以进入 README 感谢名单,并在 sponsor 页面展示企业名称和链接。更深的企业合作可以放到商业支持里处理,例如 Android 性能 trace 专家诊断、Perfetto / SmartPerfetto 团队培训、企业内部部署、定制 YAML Skill / Strategy、商业授权与集成咨询。
LLM / API / Token 厂商赞助更适合用 credits、token 套餐、试用账号或开发者额度支持 SmartPerfetto。SmartPerfetto 这类工具只会聊天不够,还要稳定支持流式输出、tool/function calling、长上下文恢复、结构化参数和真实 trace 分析。厂商赞助可以换来三类更直接的项目支持:
| 赞助类型 | 项目侧支持 |
|---|---|
| 个人赞助 | README 感谢名单,支持开源维护和公开示例成本 |
| 普通企业赞助 | README 感谢名单,sponsor 页面展示,企业支持/培训/诊断合作入口 |
| LLM / Token 厂商赞助 | README 前部赞助展示,Provider 配置说明,模型推荐候选,第一时间适配和回归验证 |
这里的“模型推荐”必须基于实际验证。赞助不会改变 SmartPerfetto 的默认 Provider 选择、兼容性结论或技术判断;如果某个模型在真实 trace 分析、工具调用或长程推理里不稳定,文档会如实说明。反过来,如果一个厂商提供了可持续 credits,并且模型在 SmartPerfetto 的真实分析任务中稳定跑通,就适合进入 README 更靠前的位置、Provider 配置指南和推荐模型说明。
联系方式仍然走当前 sponsor 页面和 README 里的微信 553000664。安全问题、商业授权和企业内部部署需求应单独沟通,不要混在公开 bug issue 里。
Bug 反馈该怎么写
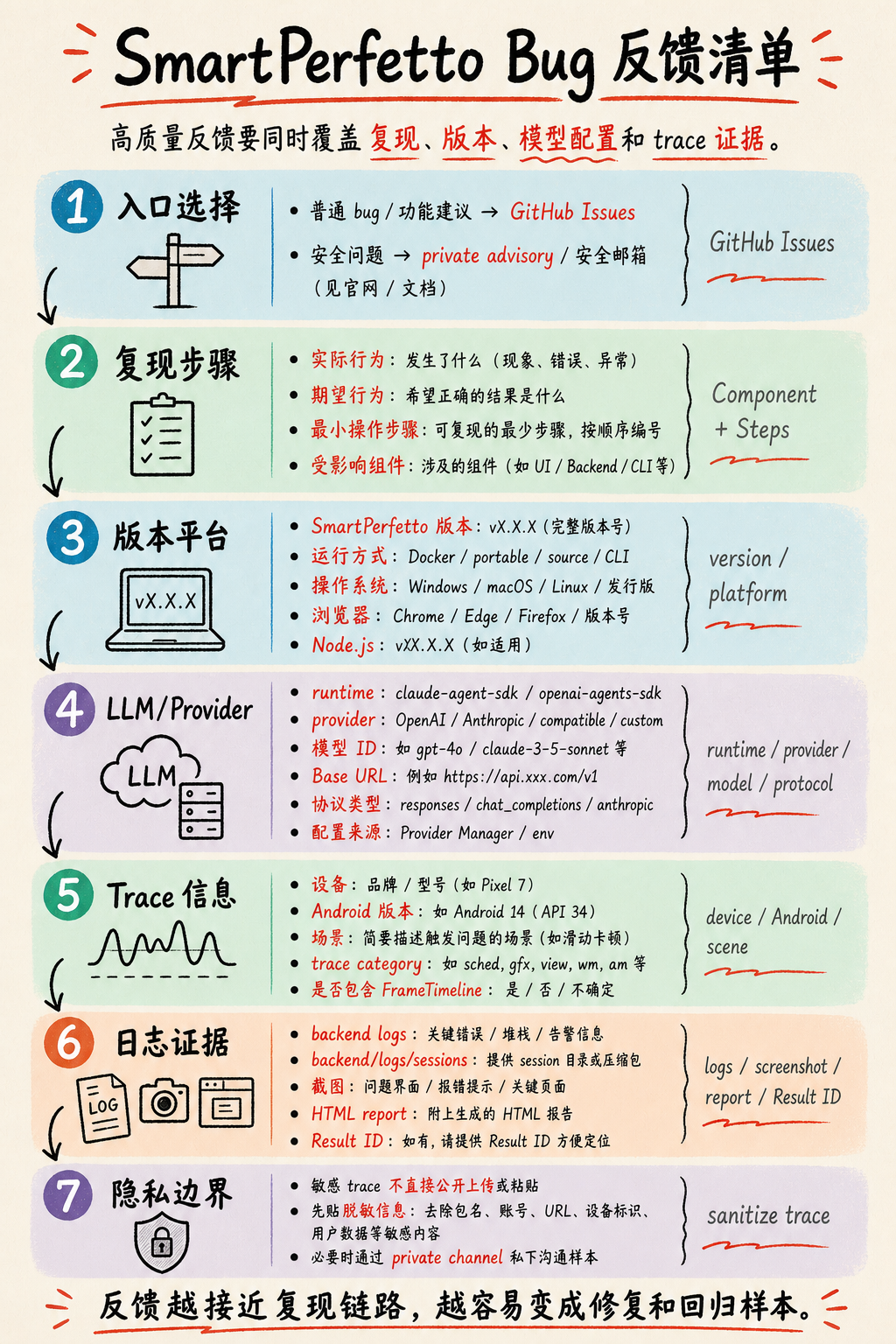
SmartPerfetto 的 bug 反馈入口是 GitHub Issues。安全问题不要发公开 issue,走 GitHub private advisory 或安全邮箱。
普通 bug 里至少写清楚当前模板要求的六项:Description、Component、Steps to Reproduce、Trace Information、Logs / Screenshots、Environment。对 SmartPerfetto 来说,还应补齐版本、平台和 LLM 配置,因为很多问题由 provider 协议、模型 tool calling、trace 采集质量、runtime session 状态共同影响,不能只按前端或后端 bug 处理。
一份可定位的反馈建议包含这些字段:
| 类别 | 要写什么 |
|---|---|
| SmartPerfetto 版本 | 版本号、commit、Docker image tag、免安装包文件名,至少给出其中一种 |
| 运行方式 | Docker Hub、源码 ./start.sh、dev 模式、Windows/macOS/Linux 免安装包、CLI |
| 平台环境 | OS 版本、浏览器、Node.js 版本;Docker 路径还要写 Docker Desktop/Engine 和 WSL2 状态 |
| 问题组件 | AI Analysis、Skills、Frontend UI Panel、Trace Processor、Backend API、Provider Manager、CLI 等 |
| 复现步骤 | 从加载 trace 到点击/输入/切换的最小步骤,写实际结果和期望结果 |
| Trace 信息 | 设备、Android 版本、业务场景、trace category、是否包含 FrameTimeline,trace 大小 |
| LLM / Provider | runtime 是 claude-agent-sdk 还是 openai-agents-sdk;provider 名称、模型 ID、Base URL、协议类型、配置来源是 Provider Manager 还是 .env |
| 分析选项 | fast、full、auto,是否在多轮追问中切换过模式 |
| 证据定位 | Result ID、HTML report、evidenceRefId、sourceToolCallId、逐句数据引用里的 Q1/C1、相关 SQL 或 Skill 表格 |
| 证据材料 | 后端日志、backend/logs/sessions/、截图、HTML report、Result ID、/health 的 aiEngine 片段 |
| 隐私边界 | trace 可能包含业务和用户数据,公开 issue 不要直接上传敏感 trace;可以先贴脱敏信息,必要时再私下沟通样本 |
Provider 相关问题要把“模型能聊天”和“模型能稳定 tool call”分开描述。SmartPerfetto 依赖流式输出、tool/function calling、上下文恢复和结构化参数。一个 provider 在普通聊天里正常,不代表它能跑完整 trace 分析。
Trace 相关问题也要写采集条件。Android 12+ 且包含 FrameTimeline 的 trace 更适合 SmartPerfetto;滑动、启动、ANR、GPU/渲染各自需要不同 category。没有对应数据源时,正确行为应该是标出缺失信号,而不是编一个确定结论。
分析结论不符合预期时,优先贴报告中的证据位置。比如某个结论写了“主线程 Runnable 等待 120ms”,就把对应 Q1/C1、evidenceRefId、表格行、列名和值一起贴出来。这样反馈可以直接变成 SQL 修复、Skill 分支或报告 contract 修复。
当前最需要的反馈
SmartPerfetto 当前缺的是能复现、能回归、能改进 Skill 的样本。泛泛评价很难转成代码修复或 Skill 改进。
更有价值的反馈通常长这样:
- 某条滑动 trace 里,SmartPerfetto 把 jank 归到 RenderThread,但人工看是主线程 Binder 等待。请附上时间段、frame id、相关 SQL 或截图。
- 某条报告里的逐句数据引用指到了错误行或缺少关键数值。请附
Q1/C1、evidenceRefId、Result ID、HTML report 和对应表格截图。 - 某个 provider 在
openai-agents-sdk下 tool call 参数变形。请附 runtime、provider、模型 ID、协议类型和 session log。 - 某个设备/厂商 trace 缺少常见表,导致 Skill 失败。请附 Android 版本、trace category、失败 Skill 名称和错误日志。
- 多 Trace 对比里某个 Result ID 找不到。请附 workspace、可见性、Result ID、当前窗口状态和操作步骤。
一条好的 bug 反馈应该能变成三类东西之一:代码修复、Skill 分支、回归测试。只有截图和一句“结果不对”,很难判断问题在 trace、模型、provider、前端状态还是后端工具。
收束
SmartPerfetto 这两周的变化,方向很清楚:从“在 Perfetto 里加一个 AI 对话窗口”,走向“把 trace 分析变成可查询、可复用、可分享、可回归的工程系统”。
它仍处在快速开发阶段。公开 API、内部合约、Provider preset、企业部署面都会继续调整。对普通用户来说,最稳的路径是用 Docker 或免安装包跑一条自己的 trace;对贡献者来说,最有用的输入是可复现 trace、能说明错误归因的证据、能补进 Skill/策略的 SQL 和回归样本。
如果你已经在 Android 性能工作里使用 Perfetto,SmartPerfetto 现在值得再试一次。两周前的介绍已经不足以代表当前仓库状态。