本文介绍了 App 开发者不经常接触到但在 Android Framework 渲染链路中非常重要的一个类 Choreographer,包括 Choreographer 的引入背景、简介、部分源码解析、与 MessageQueue 的交互、在 APM 中的应用,以及手机厂商基于 Choreographer 的一些优化思路。
Choreographer 的引入主要是配合 Vsync,为上层应用的渲染提供稳定的 Message 处理时机。当 Vsync 信号到来时,系统通过对 Vsync 信号周期的调整,控制每一帧绘制操作的时机。目前主流手机的屏幕刷新率已达到 120Hz,即每 8.3ms 刷新一次,系统为配合屏幕刷新频率,相应调整 Vsync 周期。每个 Vsync 周期到来时,Vsync 信号唤醒 Choreographer 执行应用的绘制操作,这正是引入 Choreographer 的主要作用。了解 Choreographer 还可以帮助应用开发者深入理解每一帧的运行原理,同时加深对 Message、Handler、Looper、MessageQueue、Input、Animation、Measure、Layout、Draw 等核心组件的认识。许多 APM(应用性能监控)工具也利用了 Choreographer(通过 FrameCallback)、FrameMetrics/gfxinfo framestats(底层依赖 FrameInfo)、MessageQueue(通过 IdleHandler)和 Looper(通过自定义 MessageLogging)这些组合机制进行性能监测。深入理解这些机制后,开发者可以更有针对性地进行性能优化,形成系统化的优化思路。
本文目录
- Perfetto 系列目录
- 主线程运行机制的本质
- Choreographer 简介
- 源码解析
- MessageQueue 与 Choreographer
- APM 与 Choreographer
- 厂商优化
- 参考资料
- 本文知乎地址
- 关于我 && 博客
本文是 Perfetto 系列文章的第五篇,主要是对 Perfetto 中的 Choreographer 进行简单介绍
本系列的目的是通过 Perfetto 这个工具,从另外一个角度来看待 Android 系统整体的运行,同时也从另外一个角度来对 Framework 进行学习。也许你看了很多讲 Framework 的文章,但是总是记不住代码,或者不清楚其运行的流程,也许从 Perfetto 这个图形化的角度,你可以理解的更深入一些。
Perfetto 系列目录
- Android Perfetto 系列目录
- Android Perfetto 系列 1:Perfetto 工具简介
- Android Perfetto 系列 2:Perfetto Trace 抓取
- Android Perfetto 系列 3:熟悉 Perfetto View
- Android Perfetto 系列 4:使用命令行在本地打开超大 Trace
- Android Perfetto 系列 5:Android App 基于 Choreographer 的渲染流程
- Android Perfetto 系列 6:为什么是 120Hz?高刷新率的优势与挑战
- Android Perfetto 系列 7 - MainThread 和 RenderThread 解读
- Android Perfetto 系列 8:深入理解 Vsync 机制与性能分析
- Android Perfetto 系列 9 - CPU 信息解读
- Android Perfetto 系列 10 - Binder 调度与锁竞争
- 视频(B站) - Android Perfetto 基础和案例分享
- 视频(B站) - Android Perfetto 分享 - 出图类型分享:AOSP、WebView、Flutter + OEM 系统优化分享
如果大家还没看过 Systrace 系列,下面是传送门:
- Systrace 系列目录 : 系统介绍了 Perfetto 的前身 Systrace 的使用,并通过 Systrace 来学习和了解 Android 性能优化和 Android 系统运行的基本规则。
- 本文的 Systrace 版本:Android 基于 Choreographer 的渲染机制详解
- 个人博客 :个人博客,主要是 Android 相关的内容,也放了一些生活和工作相关的内容。
欢迎大家在 关于我 页面加入微信群或者星球,讨论你的问题、你最想看到的关于 Perfetto 的部分,以及跟各位群友讨论所有 Android 开发相关的内容
主线程运行机制的本质
在讲 Choreographer 之前,我们先理一下 Android 主线程运行的本质,其实就是 Message 的处理过程,我们的各种操作,包括每一帧的渲染操作 ,都是通过 Message 的形式发给主线程的 MessageQueue ,MessageQueue 处理完消息继续等下一个消息,如下图所示
MethodTrace 图示
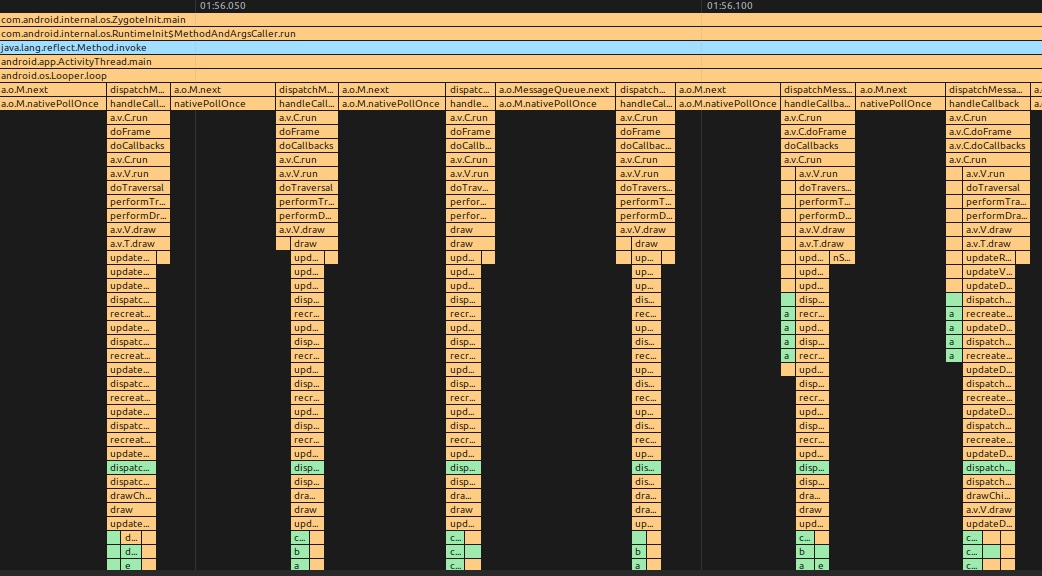
Perfetto 图示

演进
引入 Vsync 之前的 Android 版本,渲染一帧相关的 Message ,中间是没有间隔的,上一帧绘制完,下一帧的 Message 紧接着就开始被处理。这样的问题就是,帧率不稳定,可能高也可能低,不稳定,如下图
MethodTrace 图示
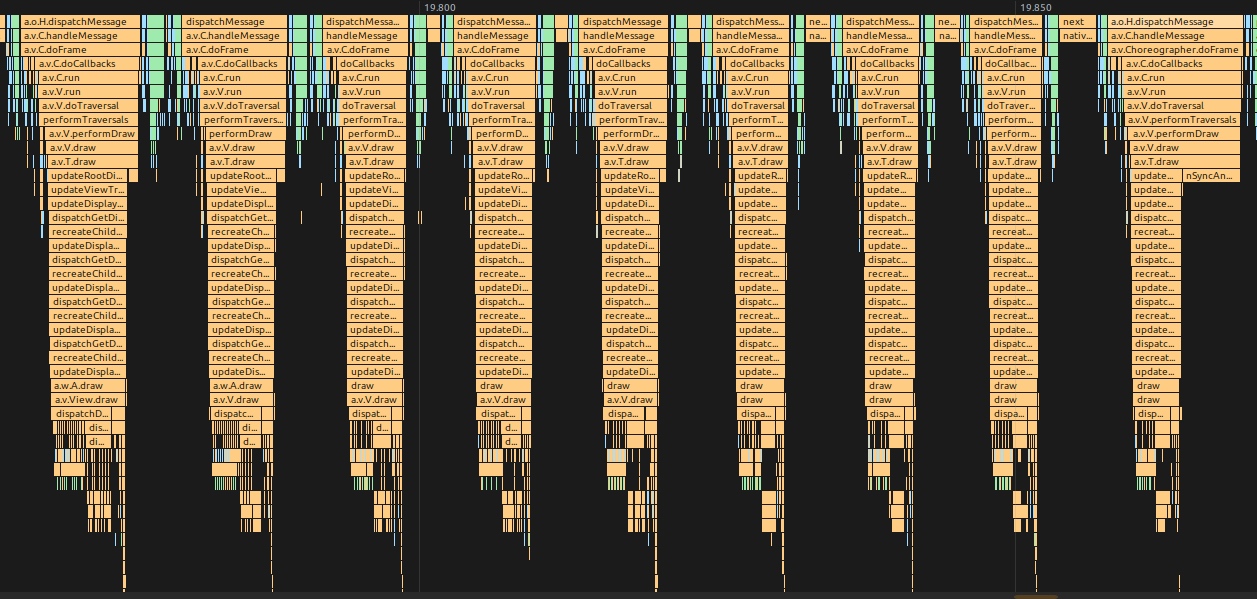
Trace 图示(资源比较老,用 Systrace 图示)
这时候的瓶颈会落在 dequeueBuffer。因为屏幕有固定的刷新周期,FB 消耗 Front Buffer 的速度基本稳定,SF 消耗 App Buffer 的速度也基本稳定,所以 App 会卡在 dequeueBuffer 这里。这会导致 App Buffer 获取不稳定,也更容易出现卡顿掉帧。
对于用户来说,稳定的帧率才是好的体验,比如你玩王者荣耀,相比 fps 在 60 和 40 之间频繁变化,用户感觉更好的是稳定在 50 fps 的情况.
所以 Android 的演进中,最初引入了 Vsync + TripleBuffer + Choreographer 的机制,后来从 Android R (Android 11) 开始引入并持续完善 BlastBufferQueue,共同构成了现代 Android 稳定帧率输出机制,让软件层和硬件层可以以共同的频率一起工作。
引入 Choreographer
Choreographer 的引入主要是配合 Vsync,为上层应用的渲染提供稳定的 Message 处理时机。当 Vsync 信号到来时,系统通过对 Vsync 信号周期的调整,控制每一帧绘制操作的时机。目前主流手机的屏幕刷新率已达到 120Hz,即每 8.3ms 刷新一次,系统为配合屏幕刷新频率,相应调整 Vsync 周期。每个 Vsync 周期到来时,Vsync 信号唤醒 Choreographer 执行应用的绘制操作,如果每个 Vsync 周期应用都能渲染完成,那么应用的 fps 就是120,给用户的感觉就是非常流畅,这就是引入 Choreographer 的主要作用
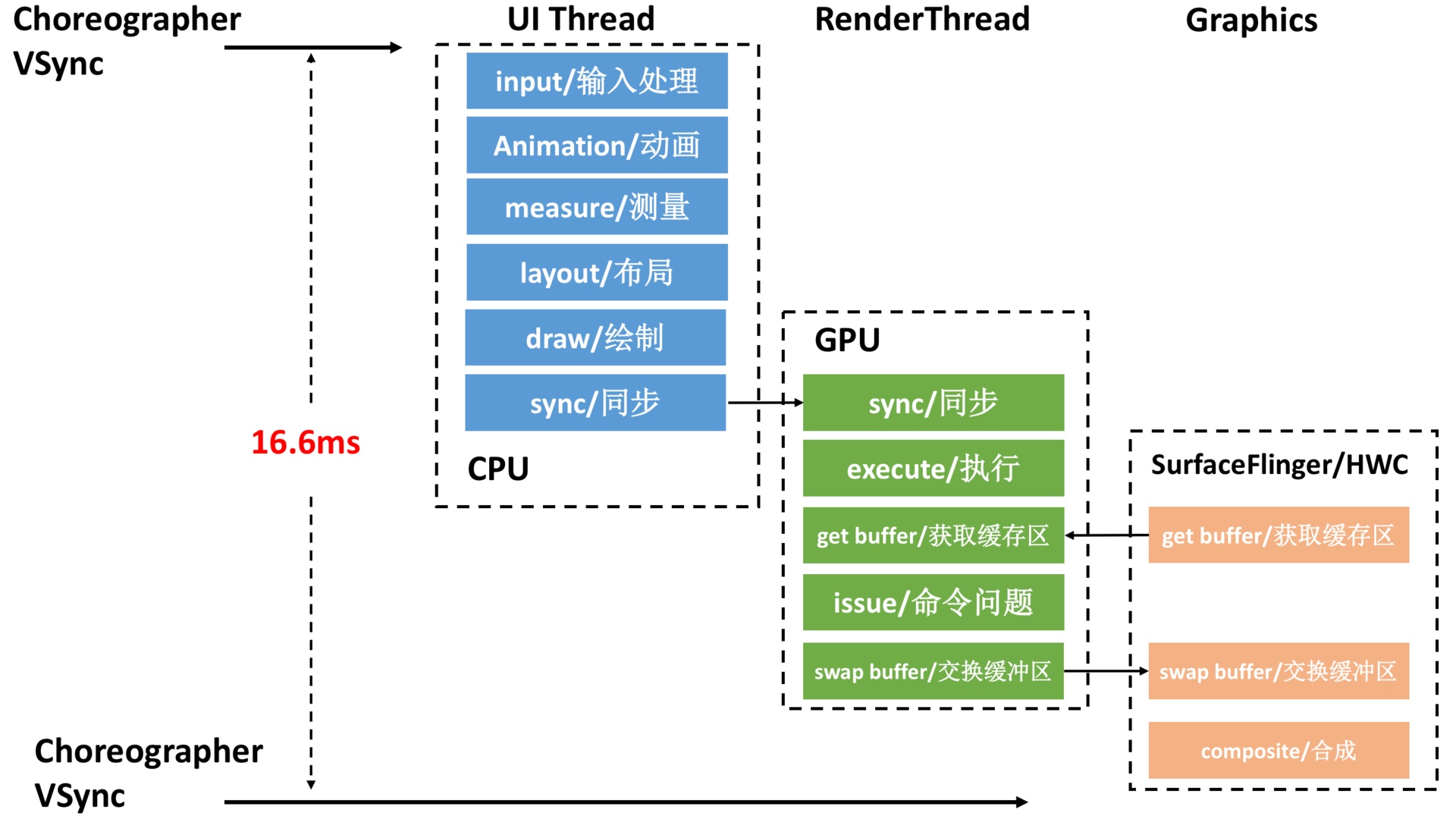
当然目前主流旗舰手机的刷新率已达到120Hz,Vsync周期已缩短至8.3ms,上图中的操作要在更短的时间内完成,对性能的要求也越来越高,具体可以看新的流畅体验,90Hz 漫谈 这篇文章(文章虽然讨论90Hz,但同样的原理适用于120Hz)
Choreographer 简介
Choreographer 扮演 Android 渲染链路中承上启下的角色
- 承上:负责接收和处理 App 的各种更新消息和回调,等到 Vsync 到来的时候统一处理。比如集中处理 Input(主要是 Input 事件的处理)、Animation(动画相关)、Traversal(包括 measure、layout、draw 等操作),判断卡顿掉帧情况,记录 CallBack 耗时等
- 启下:负责请求和接收 Vsync 信号。接收 Vsync 事件回调(通过 FrameDisplayEventReceiver.onVsync);请求 Vsync(FrameDisplayEventReceiver.scheduleVsync)
从上面可以看出,Choreographer 在 Android 渲染管线中扮演关键的协调者角色,其重要性在于通过 Choreographer + SurfaceFlinger + Vsync + BlastBufferQueue 这一套完整的渲染机制,确保 Android 应用能够以稳定的帧率运行(60 fps、90 fps 或 120 fps),有效减少帧率波动带来的视觉不适感。
了解 Choreographer 还可以帮助应用开发者深入理解每一帧的运行原理,同时加深对 Message、Handler、Looper、MessageQueue、Input、Animation、Measure、Layout、Draw 等核心组件的认识。许多 APM(应用性能监控)工具也利用了 Choreographer(通过 FrameCallback)、FrameMetrics/gfxinfo framestats(底层依赖 FrameInfo)、MessageQueue(通过 IdleHandler)和 Looper(通过自定义 MessageLogging)这些组合机制进行性能监测。深入理解这些机制后,开发者可以更有针对性地进行性能优化,形成系统化的优化思路。
另外,虽然图表是解释流程的有效方式,但本文将更多依赖 Perfetto 和 MethodTrace 工具的可视化输出。Perfetto 以时间线方式(从左到右)展示整个系统的运行状况,涵盖 CPU、SurfaceFlinger、SystemServer 和应用进程等关键组件的活动。使用 Perfetto 和 MethodTrace 可以直观展示关键执行流程,当您熟悉系统代码后,Perfetto 的输出能够直接映射到设备的实际运行状态。因此,本文除了引用少量网络图表外,主要依靠 Perfetto 来展示分析结果。
从 Perfetto 的角度来看 Choreographer 的工作流程
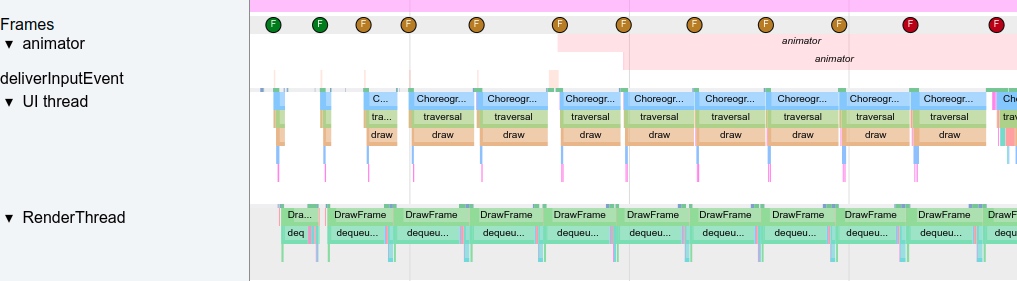
下图以滑动设置界面为例子,我们先看一下从上到下设置界面的完整预览图。Perfetto 中从左到右,每一个绿色的帧都表示一帧,也就是最终我们会在手机上看到的画面。
- 图中每一个 VSYNC-app 的值的区间是一个 Vsync 的时间,对应当前设备的刷新率,如 60Hz 时为 16.6ms,120Hz时为8.3ms,上升沿或者下降沿就是 Vsync 到达的时间
- 每一帧处理的流程:接收到 Vsync 信号回调-> UI Thread –> RenderThread –> SurfaceFlinger
- UI Thread 和 RenderThread 就可以完成 App 一帧的渲染,在 Android 11 及以上版本中,会通过 BlastBufferQueue 路径把渲染完的 Buffer 提交给 SurfaceFlinger 去合成,然后我们就可以在屏幕上看到这一帧
- Settings 滑动时每一帧耗时都很短(Ui Thread 耗时 + RenderThread 耗时),但是由于 Vsync 的存在,每一帧都会等到 Vsync 才开始处理

有了上面这个整体的概念,我们将 UI Thread 的每一帧放大来看,看看 Choreographer 的位置以及 Choreographer 是怎么组织每一帧的

Choreographer 的工作流程
- Choreographer 初始化
- 初始化 FrameHandler,绑定 Looper
- 初始化 FrameDisplayEventReceiver,与 SurfaceFlinger 建立通信用于接收和请求 Vsync
- 初始化 CallBackQueues
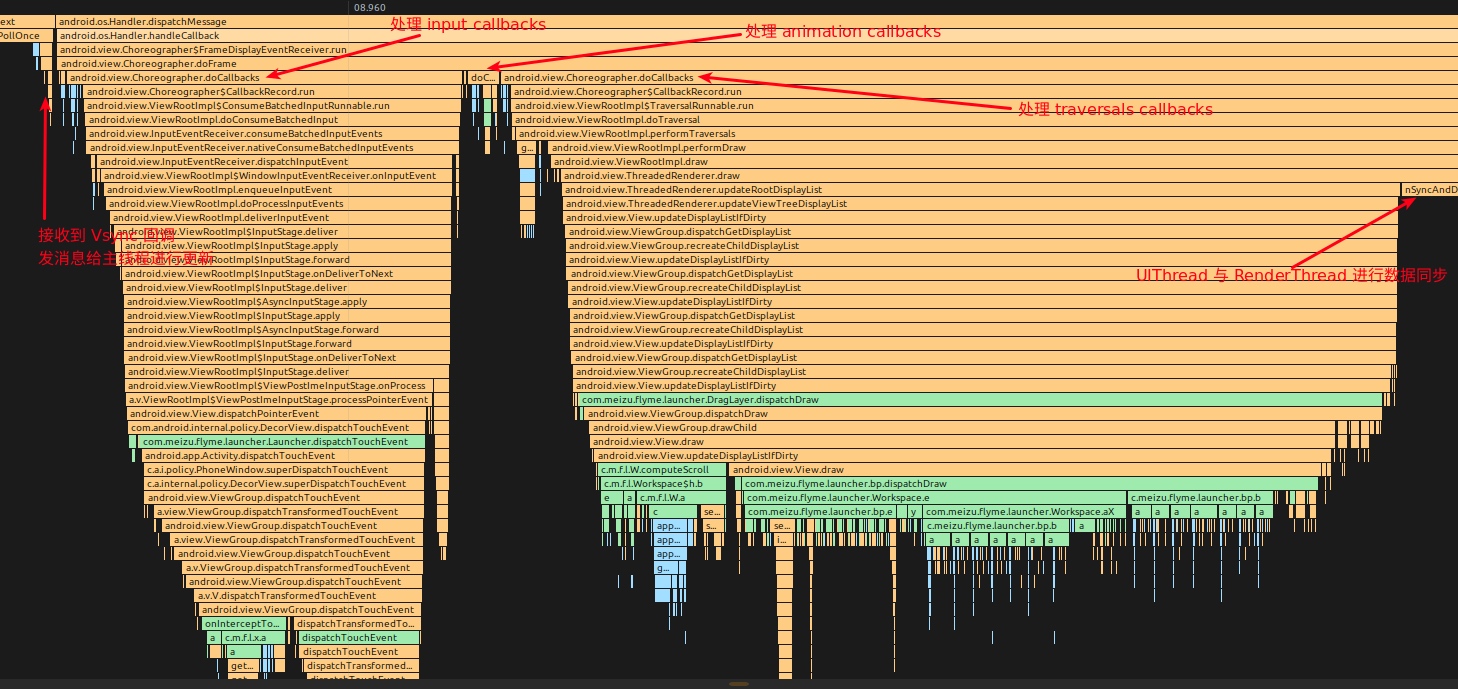
- SurfaceFlinger 的 appEventThread 唤醒发送 Vsync,Choreographer 回调 FrameDisplayEventReceiver.onVsync,进入 Choreographer 的主处理函数 doFrame
- Choreographer.doFrame 计算掉帧逻辑
- Choreographer.doFrame 处理 Choreographer 的第一个 callback:input
- Choreographer.doFrame 处理 Choreographer 的第二个 callback:animation
- Choreographer.doFrame 处理 Choreographer 的第三个 callback:insets animation
- Choreographer.doFrame 处理 Choreographer 的第四个 callback:traversal
- traversal-draw 中 UIThread 与 RenderThread 同步数据
- Choreographer.doFrame 处理 Choreographer 的第五个 callback:commit
- RenderThread 处理绘制命令
- 在 Android 11 及以上版本中,RenderThread 通过 BlastBufferQueue 向 SurfaceFlinger 提交绘制内容(不同版本细节持续演进)
- BlastBufferQueue 由 App 端创建和管理
- 通过生产者 (BBQ_BufferQueue_Producer) 和消费者 (BufferQueue_Consumer) 模型工作
- UI 线程等待 RenderThread 的概率与时长通常会降低,可以更早地准备下一帧(仍取决于具体同步点)
第一步初始化完成后,后续就会在步骤 2-10 之间循环
同时也附上这一帧所对应的 MethodTrace(这里预览一下即可,下面会有详细的大图)
Choreographer 与 RenderThread 及 BlastBufferQueue 的交互
从 Android R (Android 11) 开始,RenderThread 与 SurfaceFlinger 之间的交互发生了重要变化,其核心是 BlastBufferQueue 的引入与后续演进。下面看这一机制是如何工作的。
BlastBufferQueue 工作原理
BlastBufferQueue 是一个专为 UI 渲染优化的 BufferQueue 变体,它替代了传统由 SurfaceFlinger 创建的 BufferQueue,转为由 App 端创建和管理,用于 App 与 SurfaceFlinger 之间的缓冲区管理。
- 更高效的缓冲区管理
在传统的 BufferQueue 中,App 需要通过 dequeueBuffer 获取一个可用的缓冲区,然后渲染内容,最后通过 queueBuffer 将缓冲区提交给 SurfaceFlinger。这个过程中,如果没有可用的缓冲区,App 需要等待,这会导致阻塞。
BlastBufferQueue 通过更智能的缓冲区管理,减少了这种等待,特别是在高刷新率设备上,效果更明显。
RenderThread 与 UI 线程的解耦
在较老实现中,UI 线程与 Buffer 提交路径耦合更紧,主线程更容易在关键同步点发生等待。引入 BlastBufferQueue 并持续优化后,UI 线程通常可以更早完成本帧 Java 侧工作并进入下一帧准备,从而降低主线程阻塞概率(是否阻塞仍取决于具体同步点与场景)。创建机制
BlastBufferQueue 在 ViewRootImpl 的 relayoutWindow 过程中创建:
1 | // 创建 BBQ 的示例代码 |
- 与 Choreographer 的配合
Choreographer 仍然是协调这一切的核心。当 Vsync 信号到来时,Choreographer 会触发 doFrame,执行各种回调,其中 CALLBACK_TRAVERSAL 会触发 ViewRootImpl 的 performTraversals(),最终走到 draw 流程。
在 draw 流程中,通过 BlastBufferQueue,RenderThread 可以更独立地工作,而 UI 线程可以更早地返回处理其他任务。
下面我们就从源码的角度,来看一下具体的实现
源码解析
下面从源码的角度来简单看一下,源码只摘抄了部分重要的逻辑,其他的逻辑则被剔除,另外 Native 部分与 SurfaceFlinger 交互的部分也没有列入,不是本文的重点,有兴趣的可以自己去跟一下。下面的源码基于 AOSP mainline(frameworks/base HEAD,核对日期:2026-02)实现,不同 Android release 的细节可能会有差异。
Choreographer 的初始化
Choreographer 的单例初始化
1 | // Thread local storage for the choreographer. |
Choreographer 的构造函数
1 | private Choreographer(Looper looper, int vsyncSource) { |
FrameHandler
1 | private final class FrameHandler extends Handler { |
Choreographer 初始化链
在 Activity 启动过程,执行完 onResume 后,会调用 Activity.makeVisible(),然后再调用到 addView(), 层层调用会进入如下方法
1 | ActivityThread.handleResumeActivity(IBinder, boolean, boolean, String) (android.app) |
FrameDisplayEventReceiver 简介
Vsync 的注册、申请、接收都是通过 FrameDisplayEventReceiver 这个类,所以可以先简单介绍一下。 FrameDisplayEventReceiver 继承 DisplayEventReceiver , 有三个比较重要的方法
- onVsync – Vsync 信号回调
- run – 执行 doFrame
- scheduleVsync – 请求 Vsync 信号
1 | private final class FrameDisplayEventReceiver extends DisplayEventReceiver implements Runnable { |
Choreographer 中 Vsync 的注册
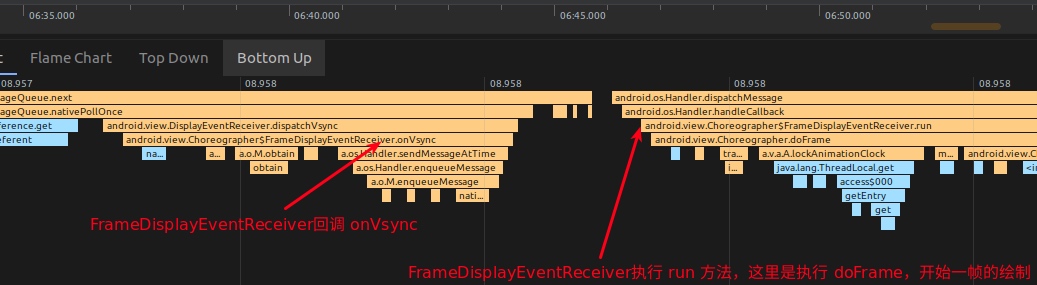
从下面的函数调用栈可以看到,Choreographer 的内部类 FrameDisplayEventReceiver.onVsync 负责接收 Vsync 回调,通知 UIThread 进行数据处理。
那么 FrameDisplayEventReceiver 是通过什么方式在 Vsync 信号到来的时候回调 onVsync 呢?答案是 FrameDisplayEventReceiver 的初始化的时候,最终通过监听文件句柄的形式,其对应的初始化流程如下
android/view/Choreographer.java
1 | private Choreographer(Looper looper, int vsyncSource) { |
android/view/Choreographer.java
1 | public FrameDisplayEventReceiver(Looper looper, int vsyncSource) { |
android/view/DisplayEventReceiver.java
1 | public DisplayEventReceiver(Looper looper, int vsyncSource) { |
简单来说,FrameDisplayEventReceiver 的初始化过程中,通过 BitTube (本质是一个 socket pair),来传递和请求 Vsync 事件,当 SurfaceFlinger 收到 Vsync 事件之后,通过 appEventThread 将这个事件通过 BitTube 传给 DisplayEventDispatcher,DisplayEventDispatcher 通过 BitTube 的接收端监听到 Vsync 事件之后,回调 Choreographer.FrameDisplayEventReceiver.onVsync,触发开始一帧的绘制,如下图
DisplayEventReceiver 与 SurfaceFlinger 的通信细节
在 Android 系统中,DisplayEventReceiver 通过 JNI 调用 nativeInit 方法来建立与 SurfaceFlinger 服务的通信通道。这个过程涉及多个关键步骤:
创建 NativeDisplayEventReceiver 对象:在 Java 层调用 nativeInit 后,JNI 创建一个 NativeDisplayEventReceiver 实例,用于接收 Vsync 信号。
获取 IDisplayEventConnection:通过 ISurfaceComposer 接口获取 IDisplayEventConnection,这是一个 Binder 接口,用于与 SurfaceFlinger 服务通信。
建立 BitTube 连接:BitTube 是一个基于 socket pair 的通信机制,专为高频、小数据量的跨进程通信设计。它在 App 进程和 SurfaceFlinger 进程之间创建一个高效的通信通道。
文件描述符监听:通过 Looper 监听 BitTube 的文件描述符,当有 Vsync 信号到来时,Looper 会通知 DisplayEventDispatcher 处理事件。
整个通信流程如下:
1 | App 进程 SurfaceFlinger 进程 |
这种设计的优势在于避免了使用 Binder 传递高频的 Vsync 事件数据,通过直接的 socket 通信提高了性能和实时性,这对于保证流畅的 UI 渲染很重要。同时,由于 BitTube 使用了文件描述符,可以无缝集成到 Android 的 Looper 机制中,使得整个系统能够以事件驱动的方式工作。
Choreographer 处理一帧的逻辑
Choreographer 处理绘制的逻辑核心在 Choreographer.doFrame 函数中,从下图可以看到,FrameDisplayEventReceiver.onVsync post 了自己,其 run 方法直接调用了 doFrame 开始一帧的逻辑处理
android/view/Choreographer.java
1 | public void onVsync(long timestampNanos, long physicalDisplayId, int frame, VsyncEventData eventData) { |
doFrame 函数主要做下面几件事
- 计算掉帧逻辑
- 记录帧绘制信息
- 执行 CALLBACK_INPUT、CALLBACK_ANIMATION、CALLBACK_INSETS_ANIMATION、CALLBACK_TRAVERSAL、CALLBACK_COMMIT
记录帧绘制信息
Choreographer 中 FrameInfo 来负责记录帧的绘制信息,doFrame 执行的时候,会把每一个关键节点的绘制时间记录下来,我们使用 dumpsys gfxinfo 就可以看到。当然 Choreographer 只是记录了一部分,剩余的部分在 hwui 那边来记录。
从 FrameInfo 这些标志就可以看出记录的内容,后面我们看 dumpsys gfxinfo 的时候数据就是按照这个来排列的
1 |
|
doFrame 函数记录从 Vsync time 到 markPerformTraversalsStart 的时间
1 | void doFrame(long frameTimeNanos, int frame, VsyncEventData eventData) { |
执行 Callbacks
1 | void doFrame(long frameTimeNanos, int frame, VsyncEventData eventData) { |
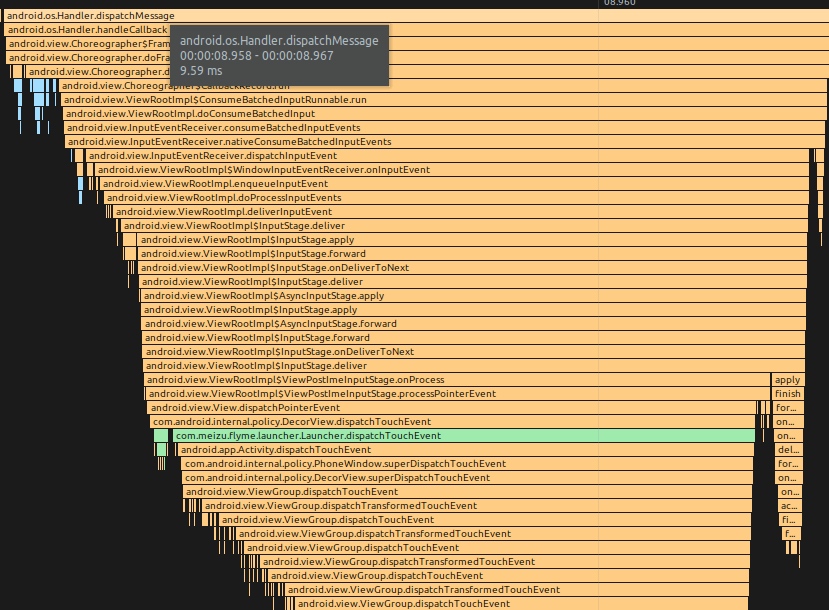
Input 回调调用栈
input callback 一般是执行 ViewRootImpl.ConsumeBatchedInputRunnable
android/view/ViewRootImpl.java
1 | final class ConsumeBatchedInputRunnable implements Runnable { |
Input 时间经过处理,最终会传给 DecorView 的 dispatchTouchEvent,这就到了我们熟悉的 Input 事件分发
Animation 回调调用栈
一般我们接触的多的是调用 View.postOnAnimation 的时候,会使用到 CALLBACK_ANIMATION
1 | public void postOnAnimation(Runnable action) { |
那么一般是什么时候回调用到 View.postOnAnimation 呢,我截取了一张图,大家可以自己去看一下,接触最多的应该是 startScroll,Fling 这种操作
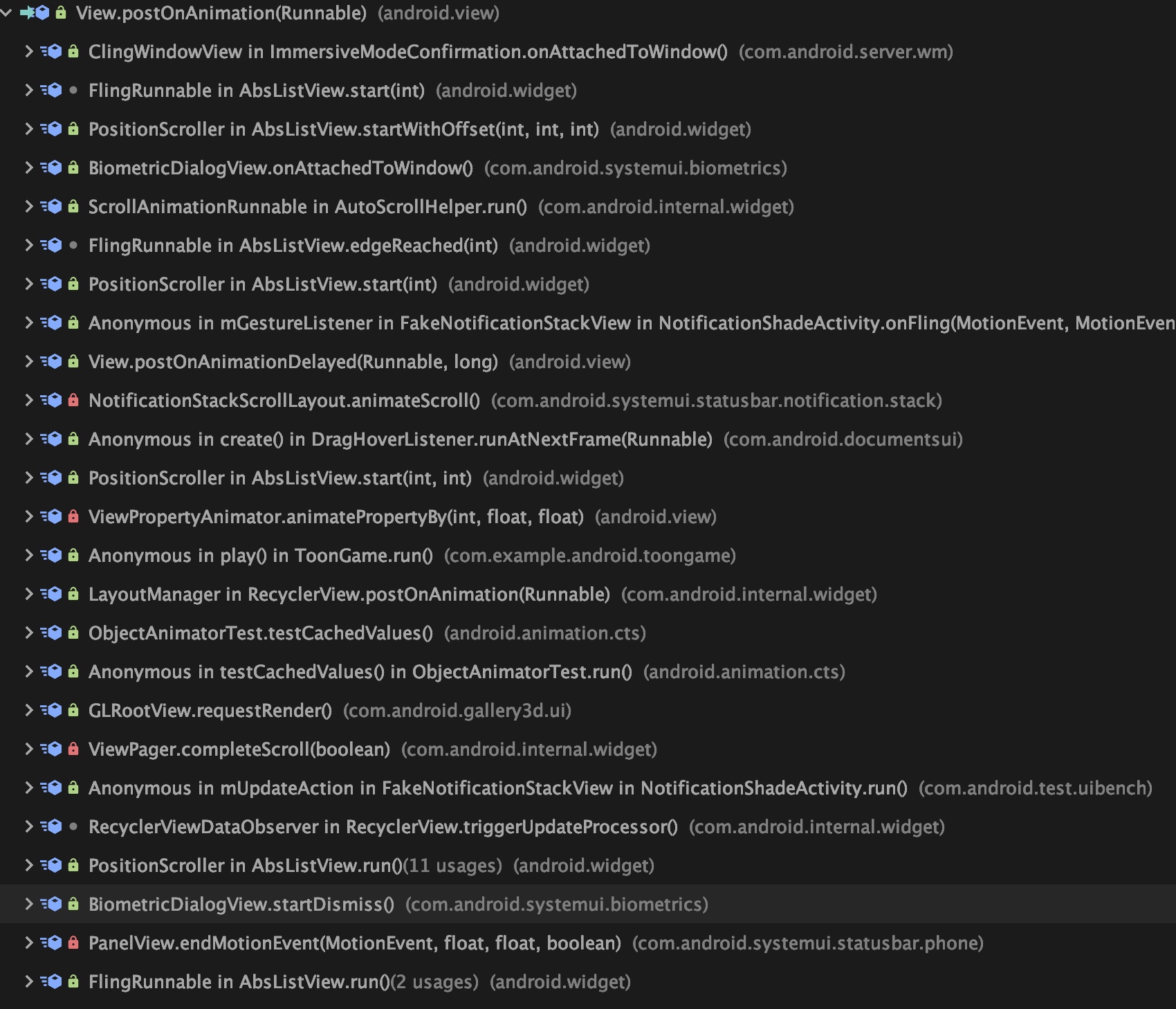
其调用栈根据其 post 的内容,下面是松手之后的 fling 动画。
另外我们的 Choreographer 的 FrameCallback 也是用的 CALLBACK_ANIMATION
1 | public void postFrameCallbackDelayed(FrameCallback callback, long delayMillis) { |
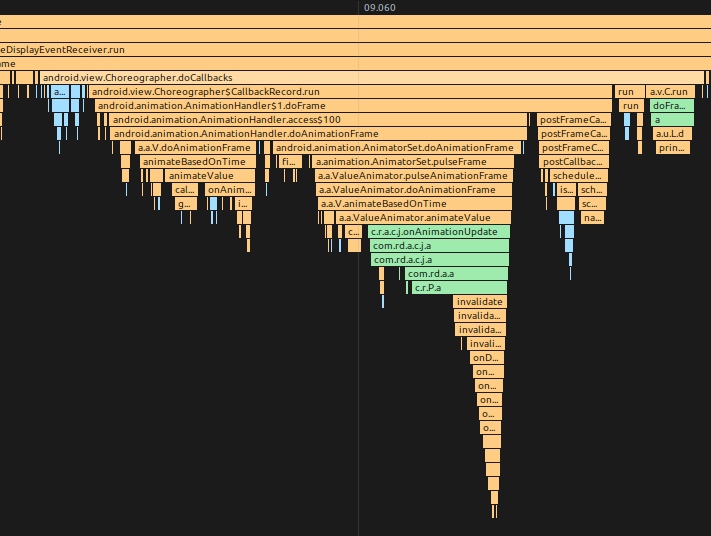
Traversal 调用栈
1 | void scheduleTraversals() { |
doTraversal 的 TraceView 示例
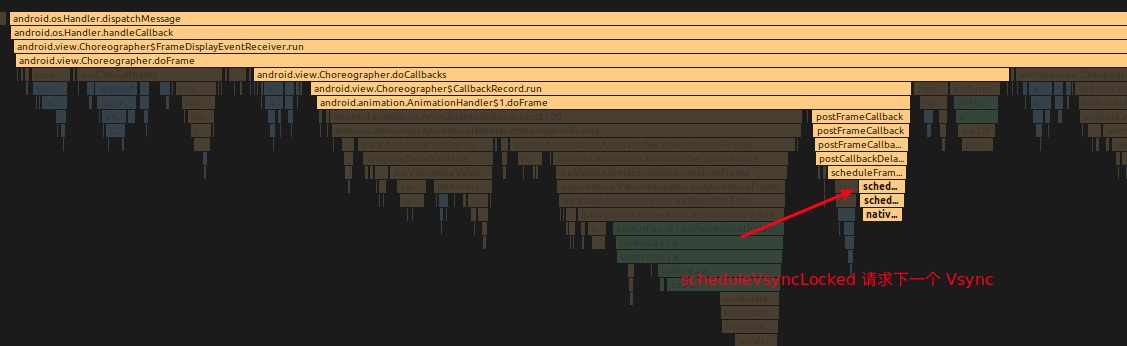
下一帧的 Vsync 请求
由于动画、滑动、Fling 这些操作的存在,我们需要一个连续的、稳定的帧率输出机制。这就涉及到了 Vsync 的请求逻辑,在连续的操作,比如动画、滑动、Fling 这些情况下,每一帧的 doFrame 的时候,都会根据情况触发下一个 Vsync 的申请,这样我们就可以获得连续的 Vsync 信号。
看下面的 scheduleTraversals 调用栈(scheduleTraversals 中会触发 Vsync 请求)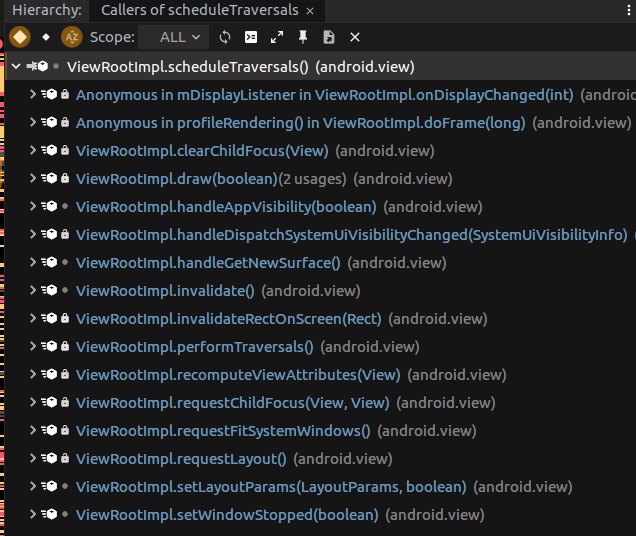
我们比较熟悉的 invalidate 和 requestLayout 都会触发 Vsync 信号请求
我们下面以 Animation 为例,看看 Animation 是如何驱动下一个 Vsync ,来持续更新画面的
ObjectAnimator 动画驱动逻辑
android/animation/ObjectAnimator.java
1 | public void start() { |
android/animation/ValueAnimator.java
1 | private void start(boolean playBackwards) { |
android/animation/AnimationHandler.java
1 | public void addAnimationFrameCallback(final AnimationFrameCallback callback, long delay) { |
调用 postFrameCallback 会走到 mChoreographer.postFrameCallback ,这里就会触发 Choreographer 的 Vsync 请求逻辑
android/animation/AnimationHandler.java
1 | public void postFrameCallback(Choreographer.FrameCallback callback) { |
android/view/Choreographer.java
1 | private void postCallbackDelayedInternal(int callbackType, |
通过上面的 Animation.start 设置,利用了 Choreographer.FrameCallback 接口,每一帧都去请求下一个 Vsync
动画过程中一帧的 TraceView 示例
源码小结
Choreographer 采用线程单例模式设计,与Looper强耦合。每个线程只能拥有一个Choreographer实例,且必须绑定一个有效的Looper对象,因为其内部Handler依赖Looper进行消息分发。在应用中,通常绑定主线程的Looper以确保UI操作的线程安全性。
DisplayEventReceiver 是一个抽象基类,其JNI实现创建IDisplayEventConnection对象作为Vsync信号的监听器。通过此机制,SurfaceFlinger的AppEventThread发出的Vsync中断信号能够被精确传递到Choreographer实例。当Vsync信号到达时,系统回调DisplayEventReceiver的onVsync方法,触发渲染流程。
DisplayEventReceiver 提供scheduleVsync方法用于请求Vsync信号。应用程序需要更新UI时,先通过此方法申请下一个Vsync中断,然后在onVsync回调中执行实际的绘制逻辑,确保渲染与屏幕刷新同步。
Choreographer 定义了FrameCallback接口,其doFrame方法在每次Vsync到来时被调用。这一设计对Android动画系统具有重要意义,使动画能够与屏幕刷新率精确同步,相比早期自行计时的实现,提供了更加流畅、省电的动画体验。
Choreographer 核心功能是接收Vsync信号并触发通过postCallback注册的回调函数。框架定义了五种类型的回调,按照执行优先级排序:
CALLBACK_INPUT:处理输入事件,如触摸、按键等交互
CALLBACK_ANIMATION:处理各类动画计算与更新
CALLBACK_INSETS_ANIMATION:处理系统插入动画,如软键盘、状态栏动画等
CALLBACK_TRAVERSAL:处理视图树的测量、布局与绘制
CALLBACK_COMMIT:执行 post-draw 收尾工作,并在必要时修正 frame time(用于更准确地反映延迟与抖动)
ListView 和 RecyclerView 的Item复用机制(ViewHolder模式)在框架层面上的具体实现会涉及到CALLBACK_INPUT和CALLBACK_ANIMATION阶段。在滑动或快速滚动时,Item的初始化、测量与绘制可能在Input回调中触发(如直接响应触摸事件),也可能在Animation回调中执行(如惯性滑动或自动滚动)。RecyclerView通过更高效的复用机制和预取(Prefetch)策略,能够在这两个阶段更智能地准备ViewHolder,减少主线程阻塞,尤其在高刷新率设备上表现更为出色。
CALLBACK_INPUT 和 CALLBACK_ANIMATION 在执行过程中会修改View的各种属性(如位置、透明度、变换矩阵等),因此必须先于CALLBACK_TRAVERSAL执行,以确保所有状态更新都能在当前帧的测量、布局与绘制过程中被正确应用。这种严格的执行顺序保证了Android UI渲染的一致性和可预测性。
APM 与 Choreographer
由于 Choreographer 的位置,许多性能监控手段都会利用它来做分析。这里补一条边界:FrameInfo 本身是 Framework 内部结构(@hide),应用侧通常通过 FrameCallback、FrameMetrics、dumpsys gfxinfo framestats、Perfetto 等手段间接获取帧信息。常用的方法如下:
- 利用 FrameCallback 的 doFrame 回调
- 利用 FrameMetrics API
- 利用 framestats(底层依赖 FrameInfo):
adb shell dumpsys gfxinfo <packagename> framestats - 利用 SurfaceFlinger latency:
adb shell dumpsys SurfaceFlinger --latency - 利用 SurfaceFlinger PageFlip 机制:
adb service call SurfaceFlinger 1013(需要系统权限) - Choreographer 自身的掉帧计算逻辑
- BlockCanary 基于 Looper 的性能监控
- Perfetto 工具的强大监控能力
- Perfetto 已是 Android 主线 tracing 基础设施(Android 10+ 已明显替代早期 systrace.py 工作流)
- Perfetto可以捕获更详细的系统性能数据,包括Choreographer的工作细节
- 使用Perfetto UI可以可视化分析帧渲染过程
利用 Perfetto 进行高级监控
Perfetto 是 Android 新一代的系统跟踪工具,目前已是 Android 主线系统跟踪方案。它提供了比 Systrace 更强大的功能:
更全面的性能数据采集
Perfetto 可以同时收集 CPU、内存、图形渲染、系统服务等多维度的数据更低的开销
采用高效的跟踪引擎,对系统性能影响更小更好的 Choreographer 追踪
可以详细跟踪 Choreographer 的工作过程,包括:
- Vsync 信号的接收和处理
- doFrame 方法的执行细节
- 各类回调的执行时间
- UI 线程和 RenderThread 的协作过程
- 追踪 BlastBufferQueue 相关链路
能够跟踪 BlastBufferQueue 的工作过程,帮助开发者理解缓冲区管理机制
使用 Perfetto 跟踪 Choreographer
1 | # 开始记录 Perfetto trace(示例:15 秒,常用类别) |
在 Perfetto UI 中,可以找到名为 “Choreographer#doFrame” 的事件,它展示了每一帧的处理时间和细节。还可以查看 UI 线程和 RenderThread 之间的协作关系,以及与 SurfaceFlinger 的交互。
利用 framestats(底层依赖 FrameInfo)进行监控
adb shell dumpsys gfxinfo
1 | Window: StatusBar |
利用 SurfaceFlinger 进行监控
命令解释:
- 数据的单位是纳秒,时间是以开机时间为起始点
- 每一次的命令都会得到128行的帧相关的数据
数据:
- 第一行数据,表示刷新的时间间隔refresh_period
- 第1列:这一部分的数据表示应用程序绘制图像的时间点
- 第2列:在SF(软件)将帧提交给H/W(硬件)绘制之前的垂直同步时间,也就是每帧绘制完提交到硬件的时间戳,该列就是垂直同步的时间戳
- 第3列:在SF将帧提交给H/W的时间点,算是H/W接受完SF发来数据的时间点,绘制完成的时间点。
掉帧 jank 计算
每一行都可以通过下面的公式得到一个值,该值是一个标准,我们称为jankflag,如果当前行的jankflag与上一行的jankflag发生改变,那么就叫掉帧
ceil((C - A) / refresh-period)
利用 SurfaceFlinger PageFlip 机制进行监控
1 | Parcel data = Parcel.obtain(); |
Choreographer 自身的掉帧计算逻辑
SKIPPED_FRAME_WARNING_LIMIT 默认为30, 由 debug.choreographer.skipwarning 这个属性控制
1 | if (jitterNanos >= mFrameIntervalNanos) { |
BlockCanary
Blockcanary 做性能监控使用的是 Looper 的消息机制,通过对 MessageQueue 中每一个 Message 的前后进行记录,打到监控性能的目的
android/os/Looper.java
1 | public static void loop() { |
MessageQueue 与 Choreographer
在 Android 消息机制中,异步消息具有特殊的处理优先级。系统可以通过 enqueueBarrier 方法向消息队列插入一个屏障(Barrier),使得该屏障之后的所有同步消息暂时无法被执行,直到调用 removeBarrier 方法移除屏障。而被标记为异步的消息则不受屏障影响,可以正常处理。
消息默认为同步类型,只有通过 Message 的 setAsynchronous 方法(该方法为隐藏 API)才能将消息设置为异步。在初始化 Handler 时,可以通过特定参数指定该 Handler 发送的所有消息均为异步类型,此时 Handler 的 enqueueMessage 方法会自动调用 Message 的 setAsynchronous 方法。
异步消息的核心价值在于能够绕过消息屏障继续执行,如果没有设置屏障,异步消息与同步消息的处理方式完全相同。通过 removeSyncBarrier 方法可以移除之前设置的屏障。
SyncBarrier 在 Choreographer 中使用的一个示例
scheduleTraversals 的时候 postSyncBarrier
1 | void scheduleTraversals() { |
doTraversal 的时候 removeSyncBarrier
1 | void doTraversal() { |
Choreographer post Message 的时候,会把这些消息设为 Asynchronous ,这样 Choreographer 中的这些 Message 的优先级就会比较高,
1 | Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action); |
厂商优化
系统厂商由于可以直接修改源码,也利用这方面的便利,做一些功能和优化,不过由于保密的问题,代码就不直接放上来了,我可以大概说一下思路,感兴趣的可以私下讨论
移动事件优化
Choreographer 本身是没有 input 消息的, 不过修改源码之后,input 消息可以直接给到 Choreographer 这里, 有了这些 Input 消息,Choreographer 就可以做一些事情,比如说提前响应,不去等 Vsync
后台动画优化
当 Android 应用退到后台时,如果未被系统终止,其仍可能继续执行各类操作。在某些情况下,应用会持续调用 Choreographer 中的 Animation Callback,即使这些动画对用户不可见,这些 Callback 的执行完全无意义,却会对 CPU 资源造成较高的占用。
因此,系统厂商在 Choreographer 中会针对这种情况做优化,通过一系列策略限制不符合条件的后台应用继续执行无意义的动画回调,有效降低系统资源占用。
帧绘制优化
和移动事件优化一样,由于有了 Input 事件的信息,在某些场景下我们可以通知 SurfaceFlinger 不用去等待 Vsync 直接做合成操作
应用启动优化
我们前面说,主线程的所有操作都是给予 Message 的 ,如果某个操作,非重要的 Message 被排列到了队列后面,那么对这个操作产生影响;而通过重新排列 MessageQueue,在应用启动的时候,把启动相关的重要的启动 Message 放到队列前面,来起到加快启动速度的作用
animation callback 前置
在上一帧的主线程做完之后,距离下一个 vsync 其实是有一定时间的空闲的,这段时间其实可以用来准备下一帧。那么我们就可以把下一帧的 animation callback 提前到这里来做,这样可以有效利用 cpu 的空闲时间,减少掉帧
插帧
跟 animation callback 前置一样,在上一帧的主线程做完之后,距离下一个 vsync 其实是有一定时间的空闲的,这段时间其实可以用来准备下一帧。只不过这里我们直接生成新的一帧:即一个 Vsync 里面,执行两次 doFrame 。插帧相当于是提前准备好后面几帧的数据,这样在遇到真正耗时的帧的时候,不会出现卡顿。
插帧实现主要是在滑动场景,用在实现了 OverScroller 的滑动组件上,比如 ListView,RecyclerVIew 这些。因为如果用了 OverScroller,我们就会在 touch up 的时候, 就知道了滑动的时间和距离,就可以在这中间做手脚(插帧),相当于在一个 Vsync 内画好了后面好几个 VSync 里面的内容。
高帧率优化
现代 Android 设备上的高刷新率(120 Hz)将 Vsync 间隔从 16.6 ms 缩短至 8.3 ms,这带来了巨大的性能和功耗挑战。如何在一帧内完成渲染的必要操作,是手机厂商必须要思考和优化的地方:
- 超级 App 的性能表现以及优化
- 游戏高帧率合作
- 120 fps、90 fps 和 60 fps 相互切换的逻辑
参考资料
- https://www.jianshu.com/p/304f56f5d486
- http://gityuan.com/2017/02/25/choreographer/
- https://developer.android.com/reference/android/view/Choreographer
- https://www.jishuwen.com/d/2Vcc
- https://juejin.im/entry/5c8772eee51d456cda2e8099
- Android 开发高手课
- Perfetto - System profiling, app tracing, and trace analysis
- 使用 Perfetto 分析 UI 性能
- BufferQueue and Gralloc
- Android 15 图形渲染优化
本文知乎地址
由于博客留言交流不方便,点赞或者交流,可以移步本文的知乎界面
知乎 - Android 基于 Choreographer 的渲染机制详解 - Perfetto 版
掘金 - Android 基于 Choreographer 的渲染机制详解 - Perfetto 版
关于我 && 博客
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
- 博主个人介绍 :里面有个人的微信和微信群链接。
- 本博客内容导航 :个人博客内容的一个导航。
- 个人整理和搜集的优秀博客文章 - Android 性能优化必知必会 :欢迎大家自荐和推荐 (微信私聊即可)
- Android 性能优化知识星球 : 欢迎加入,多谢支持~
一个人可以走的更快 , 一群人可以走的更远