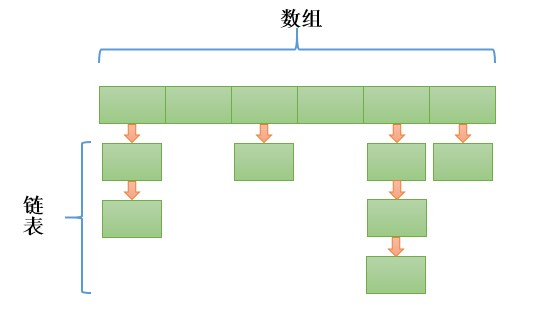
链表和数组可以按照人们意愿排列元素的次序,但是,如果想要查看某个指定的元素,却又忘记了它的位置,就需要访问所有的元素,直到找到为止。如果集合中元素很多,将会消耗很多时间。有一种数据结构可以快速查找所需要查找的对象,这个就是哈希表(hash table).
HashMap是基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
本文按源码顺序拆 HashMap:先看数据结构是数组+链表的组合,再看构造函数里 initialCapacity 与 loadFactor 的默认值含义;接着是 put 操作的扩容流程、key 为 null 时的特殊存放位置,以及 hash 冲突的解决方式;get 操作的查找路径与 put 一致,区别在判定逻辑;最后是 fail-fast 机制怎么用 modCount 在迭代器里检测并发修改。Java 8 的红黑树改造不在本文范围。
1. HashMap的数据结构:
HashMap使用数组和链表来共同组成的。可以看出底层是一个数组,而数组的每个元素都是一个链表头。
1 | static class Entry<K,V> implements Map.Entry<K,V> { |
Entry是HashMap中的一个内部静态类,包级私有,实现了Map中的接口Entey<K,V>。可以看出来它内部含有一个指向下一个元素的指针。
2.构造函数
HashMap的构造函数有四个:
- HashMap() — 构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
- HashMap(int initialCapacity) — 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
- HashMap(int initialCapacity, float loadFactor) — 构造一个带指定初始容量和加载因子的空 HashMap。
- HashMap(Map<? extends K,? extends V> m) — 构造一个映射关系与指定 Map 相同的新 HashMap
就两种,一个是指定初始容量和加载因子,一个是用一个给定的映射关系生成一个新的HashMap。说一下第一种。
1 | /** |
参数很简单,初始容量,和加载因子。初始容量定义了初识数组的大小,加载因子和初始容量的乘积确定了一个阈值。阈值最大是(1<<30) + 1。初始容量一定是2的N次方,而且刚刚比要设置的值大。默认初始容量是16,默认加载因子是0.75。当表中的元素数量大于等于阈值时,数组的容量会翻倍,并重新插入元素到新的数组中,所以HashMap不保证顺序恒久不变。
当输入的加载因子小于零或者不是浮点数时会抛出异常(IllegalArgumentException)。
3.put操作
1 | /** |
由于HashMap只是key值为null,所以首先要判断key值是不是为null,是则进行特殊处理。
1 | /** |
可以看出key值为null则会插入到数组的第一个位置。如果第一个位置存在,则替代,不存在则添加一个新的。稍后会看到addEntry函数。
** PS:考虑一个问题,key值为null会插入到table[0],那为什么还要遍历整个链表呢?**
回到put函数中。在判断key不为null后,会求key的hash值,并通过indexFor函数找出这个key应该存在table中的位置。
1 | /** |
indexFor函数很简短,但是却实现的很巧妙。一般来说我们把一个数映射到一个固定的长度会用取余(%)运算,也就是h % length,但里巧妙地运用了table.length的特性。还记得前面说了数组的容量都是很特殊的数,是2的N次方。用二进制表示也就是一个1后面N个0,(length-1)就是N个1了。这里直接用与运算,运算速度快,效率高。但是这是是利用了length的特殊性,如果length不是2的N次方的话可能会增加冲突。
前面的问题在这里就有答案了。因为indexFor函数返回值的范围是0到(length-1),所以可能会有key值不是null的Entry存到table[0]中,所以前面还是需要遍历链表的。
得到key值对应在table中的位置,就可以对链表进行遍历,如果存在该key则,替换value,并把旧的value返回,modCount++代表操作数加1。这个属性用于Fail-Fast机制,后面讲到。如果遍历链表后发现key不存在,则要插入一个新的Entry到链表中。这时就会调用addEntry函数
1 | /** |
这个函数有四个参数,第一个是key的hash值,第二个第三个分别是key和value,最后一个是这个key在table中的位置,也就是indexFor(hash(key), table.length-1)。首先会判断size(当前表中的元素个数)是不是大于或等于阈值。并且判断数组这个位置是不是空。如果条件满足则要resize(2 * table. length),等下我们来看这个操作。超过阈值要resize是为了减少冲突,提高访问效率。判断当前位置不是空时才resize是为了尽可能减少resize次数,因为这个位置是空,放一个元素在这也没有冲突,所以不影响效率,就先不进行resize了。
1 | /** |
resize操作先要判断当前table的长度是不是已经等于最大容量(1<<30)了,如果是则把阈值调到整数的最大值((1<<31) - 1),就没有再拓展table的必要了。如果没有到达最大容量,就要生成一个新的空数组,长度是原来的两倍。这时候可能要问了,如果oldTable. length不等于MAXIMUM_CAPACITY,但是(2 * oldTable. length)也就是newCapacity大于MAXIMUM_CAPACITY怎么办?这个是不可能的,因为数组长度是2的N次方,而MAXIMUM_CAPACITY = 1<<30。
生成新的数组后要执行transfer函数。
1 | /** |
这个函数要做的就是把原来table中的值挨个拿出来插到新数组中,由于数组长度发生了改变,所以元素的位置肯定发生变化,所以HashMap不能保证该顺序恒久不变。回到resize函数,这时新的数组已经生成了,只需要替换原来数组就好了。并且要更新一下阈值。可以看出来resize是个比较消耗资源的函数,所以能减少resize的次数就尽量减少。
回到函数addEntry 中,判断完是不是需要resize后就需要创建一个新的Entry了。
1 | /** |
调用createEntry函数,参数跟addEntry一样,第一个是key的hash值,第二个第三个分别是key和value,最后一个是这个key在table中的位置。这里的操作与Entry的构造函数有关系。
1 | /** |
构造函数中传入一个Entry对象,并把它当做这个新生成的Entry的next。所以createEntry函数中的操作相当于把table[bucketIndex]上的链表拿下来,放在新的Entry后面,然后再把新的Entry放到table[bucketIndex]上。
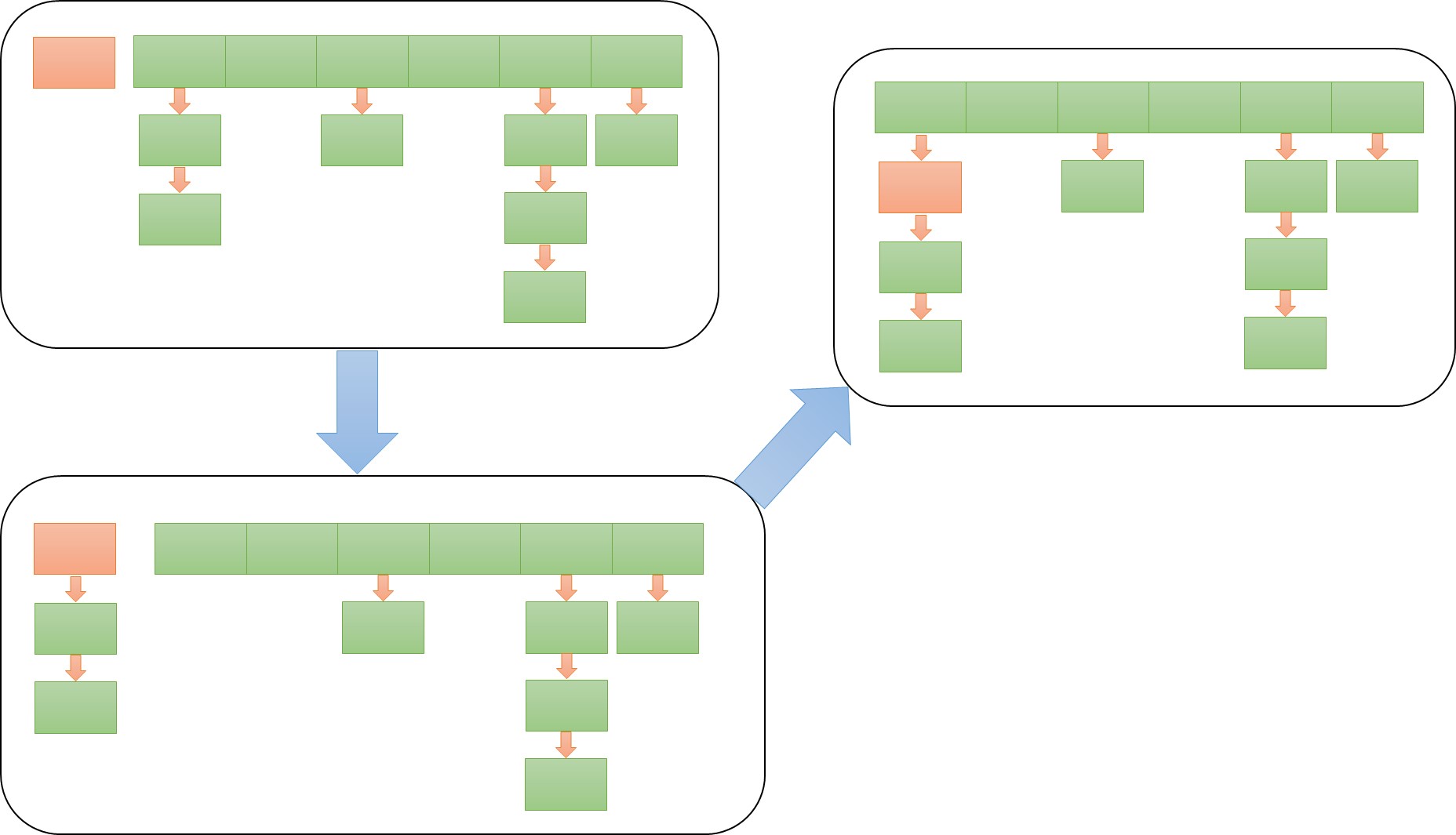
到这里整个put函数算是结束了。如果新插入的K,V则会返回null。
4.get操作
1 | /** |
也是先判断key是不是null,做特殊处理。直接上代码,不赘述。
1 | /** |
key不是null则会调用getEntry函数,并返回一个Entry对象,如果不是null,就返回entry的value。
1 | /** |
直接求key值hash值,然后求table中的位置,遍历链表。有返回entry对象,没有返回null。
5. Fail-Fast机制
1 | /** |
我们知道java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
这一策略在源码中的实现是通过modCount域,保证线程之间修改的可见性。,modCount顾名思义就是修改次数,对HashMap内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在非同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。
参考
- 《Core JAVA》
- 《JAVA API》
关于我 && 博客
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
- 博主个人介绍 :里面有个人的微信和微信群链接。
- 本博客内容导航 :个人博客内容的一个导航。
- 个人整理和搜集的优秀博客文章 - Android 性能优化必知必会 :欢迎大家自荐和推荐 (微信私聊即可)
- Android性能优化知识星球 : 欢迎加入,多谢支持~
一个人可以走的更快 , 一群人可以走的更远