本文是 Perfetto 系列的第九篇文章,主题是 Perfetto 中的 CPU 信息分析。Perfetto 提供了远超 Systrace 的数据可视化与分析能力,理解 CPU 相关信息是定位性能瓶颈、分析功耗问题的基础。
本系列的目标,就是通过 Perfetto 这个工具,从一个全新的图形化视角,来审视 Android 系统的整体运行,同时也提供一个学习 Framework 的新途径。或许你已经读过很多源码分析的文章,但总是对繁杂的调用链感到困惑,或者记不住具体的执行流程。那么通过 Perfetto,将这些流程可视化,你可能会对系统有更深入、更直观的理解。
本文目录
- Perfetto 系列文章
- Perfetto 中的 CPU 信息概览
- 抓取 CPU 信息所需要的 Trace Config
- CPU 核心架构:big.LITTLE
- CPU 调度
- CPU Frequency (CPU 频率) 深度解析
- Linux 内核调度策略:选核与迁移
- 实战与 SQL
- 总结
Perfetto 系列文章
- Android Perfetto 系列目录
- Android Perfetto 系列 1:Perfetto 工具简介
- Android Perfetto 系列 2:Perfetto Trace 抓取
- Android Perfetto 系列 3:熟悉 Perfetto View
- Android Perfetto 系列 4:使用命令行在本地打开超大 Trace
- Android Perfetto 系列 5:Android App 基于 Choreographer 的渲染流程
- Android Perfetto 系列 6:为什么是 120Hz?高刷新率的优势与挑战
- Android Perfetto 系列 7 - MainThread 和 RenderThread 解读
- Android Perfetto 系列 8:深入理解 Vsync 机制与性能分析
- Android Perfetto 系列 9 - CPU 信息解读
- Android Perfetto 系列 10 - Binder 调度与锁竞争
- 视频(B站) - Android Perfetto 基础和案例分享
- 视频(B站) - Android Perfetto 分享 - 出图类型分享:AOSP、WebView、Flutter + OEM 系统优化分享
Perfetto 中的 CPU 信息概览
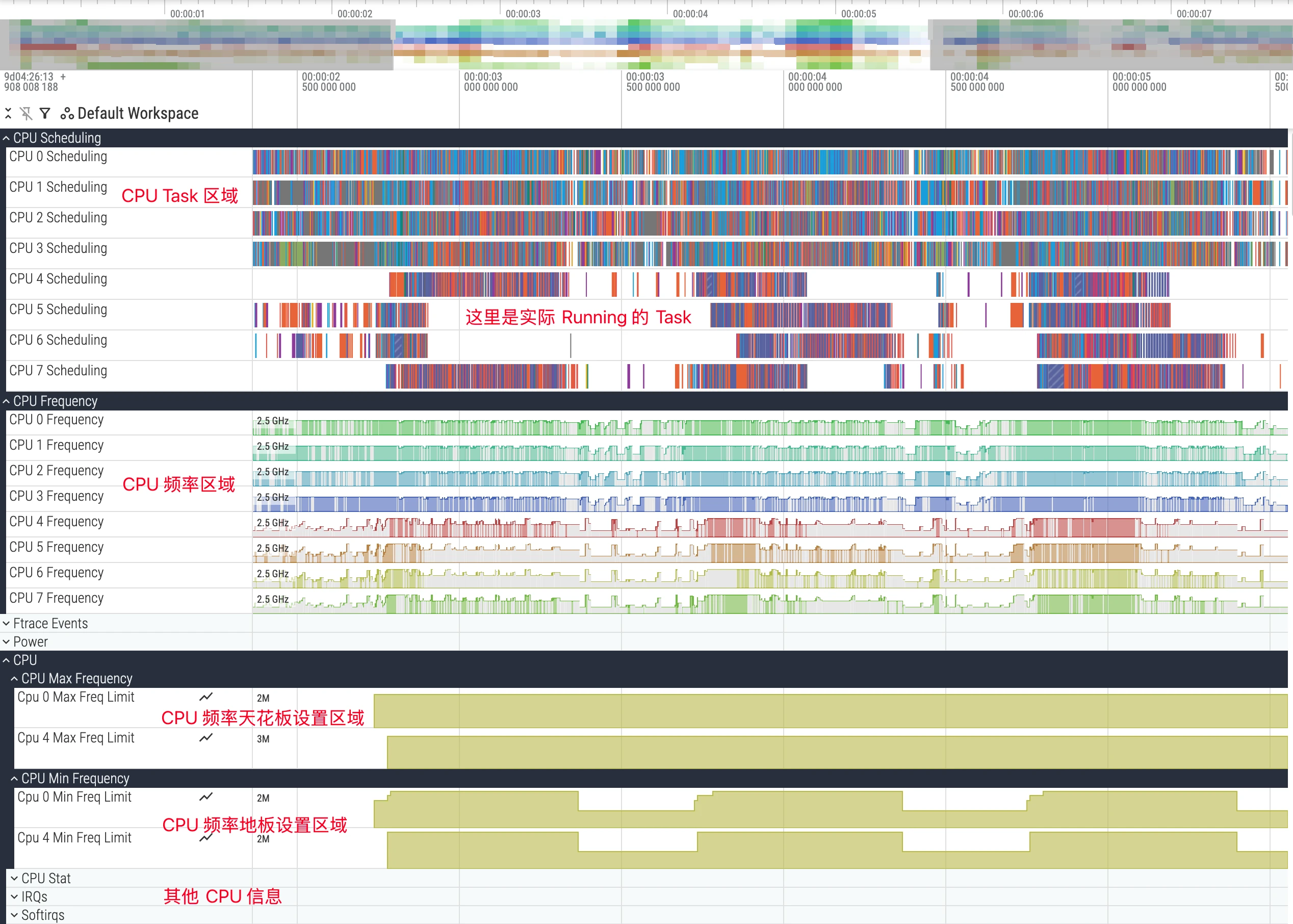
在 Perfetto UI 中,CPU 相关的信息通常分组置于顶部,是性能分析的起点。主要包含以下三个核心轨道:
- CPU Scheduling (CPU 调度): 显示在每个时间点,各个 CPU 核心上正在执行的线程。
- CPU Frequency (CPU 频率): 显示每个 CPU 核心或核心簇的频率变化情况。
- CPU Idle (CPU 空闲状态): 显示每个 CPU 核心进入的低功耗状态 (C-States)。
通过分析 CPU 相关的信息,可以解答以下关键性能问题, 或者进行竞品分析:
- 应用主线程为何没有执行?是否被其他线程抢占?
- 某个任务执行缓慢的原因是什么?是否被调度到了低性能核心?
- 在特定场景下,CPU 频率是否受限?
- 应用在后台时,CPU 是否有效进入了深度睡眠状态?
抓取 CPU 信息所需要的 Trace Config
为了采集到本文分析所需的所有 CPU 数据,你需要一个正确的 TraceConfig。不正确的配置会导致某些轨道(如 CPU 频率)或某些内核事件(如唤醒事件)丢失。以下是 Perfetto 官方文档推荐的、用于通用 CPU 分析的配置。你可以将其添加到你的 Perfetto 的 Config 中,抓 Trace 的时候使用。
1 | data_sources { |
这个配置启用了包括 sched(调度)、power(频率和空闲)、task(任务生命周期)在内的关键 ftrace 事件,是进行深度 CPU 分析的基础。
CPU 核心架构:big.LITTLE
在深入分析前,必须了解现代手机 SoC 的 CPU 核心架构。目前主流的移动处理器普遍采用 big.LITTLE 异构多核架构,或其变种,如 big.Medium.LITTLE(大中小核)。
- 小核 (LITTLE cores): 针对低功耗设计,频率较低,用于处理后台任务、轻量级计算,以保证续航。
- 大核 (big cores): 针对高性能设计,频率更高,功耗也更大,用于处理用户交互、游戏、应用启动等重负载场景。
- 超大核 (Prime Core): 部分旗舰芯片会有一个频率极高的超大核,用于应对最严苛的单核性能挑战。
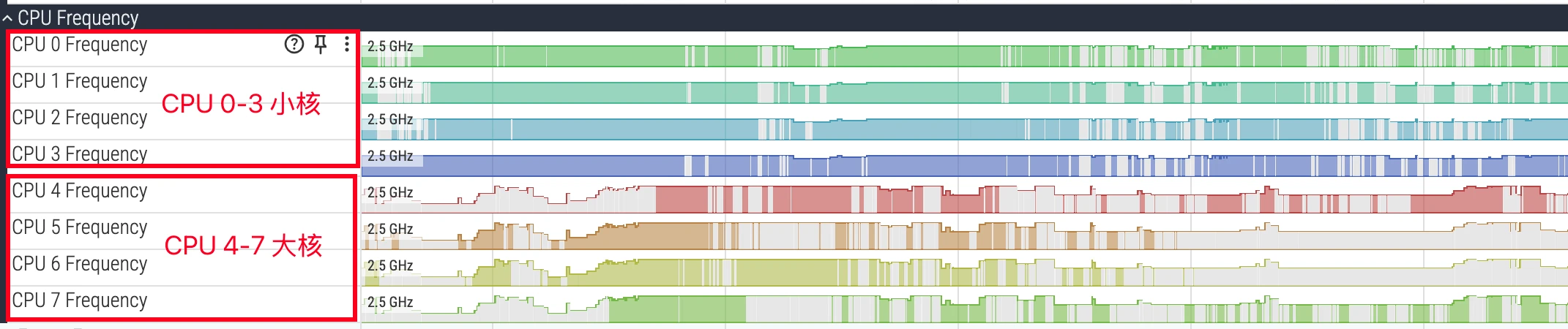
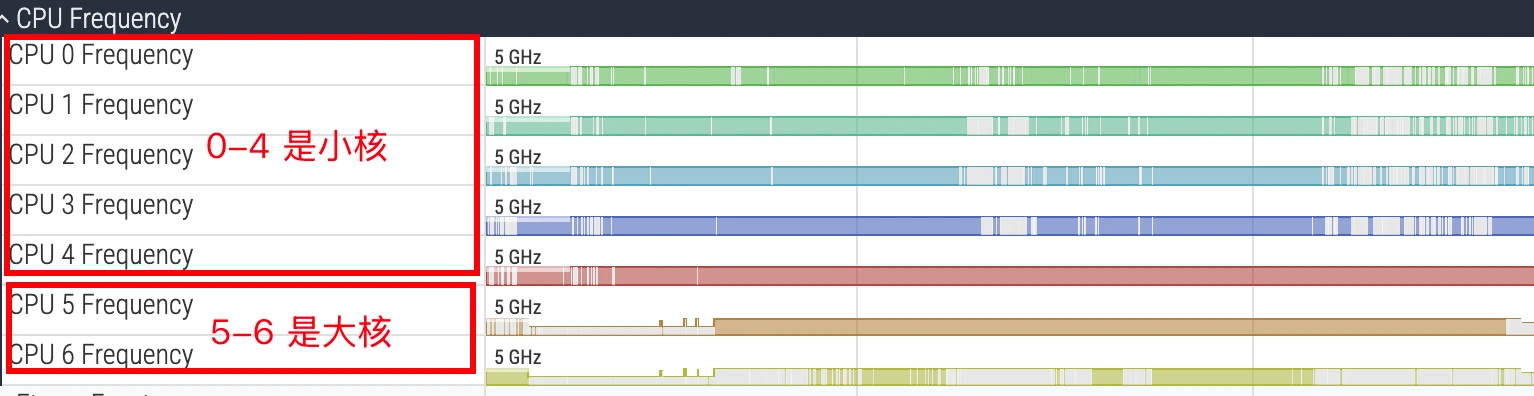
在 Perfetto 的 CPU 轨道中,核心通常从 0 开始编号。例如,在一个典型的八核处理器中,CPU 0-3 可能为小核,CPU 4-6 为大核,CPU 7 为超大核。识别核心类型对于性能分析至关重要:一个计算密集型任务如果长时间运行在小核上,其耗时必然远超预期。分析时,需要将线程的运行核心与其任务属性进行匹配,以判断调度器(Scheduler)的行为是否符合预期。
下面是一个典型的 4+4 的 CPU :
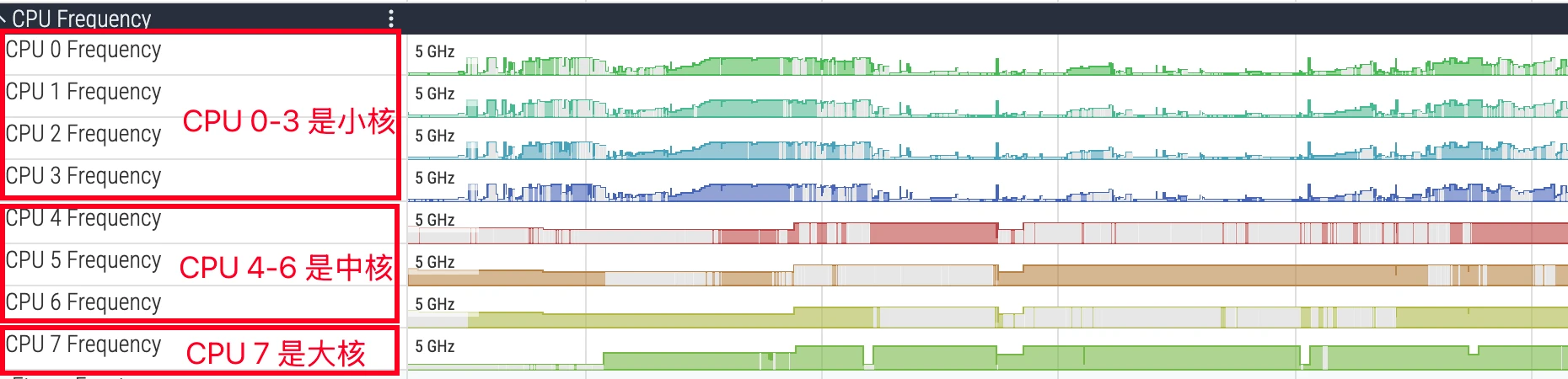
下面是一个典型的 4+3+1 的 CPU ( MTK 的天玑 9500、9400 ,以及高通骁龙高端系列):
下面是一个 5+2 的 CPU (高通 8Elite 1 阉割版,8Elite 1 的标准版 0-5 是小核,6-7 是大核,这里就不放图了)
一般通过查阅 CPU 的 spec 就可以知道他的大中小核心的架构,或者 cat 对应的 CPU 节点也可以,这里就不再赘述了。
CPU 调度
CPU Scheduling 轨道是最常用且最重要的部分,它可视化了 Linux 内核调度器的决策过程。其数据来源于内核 ftrace 中的 sched/sched_switch 事件。
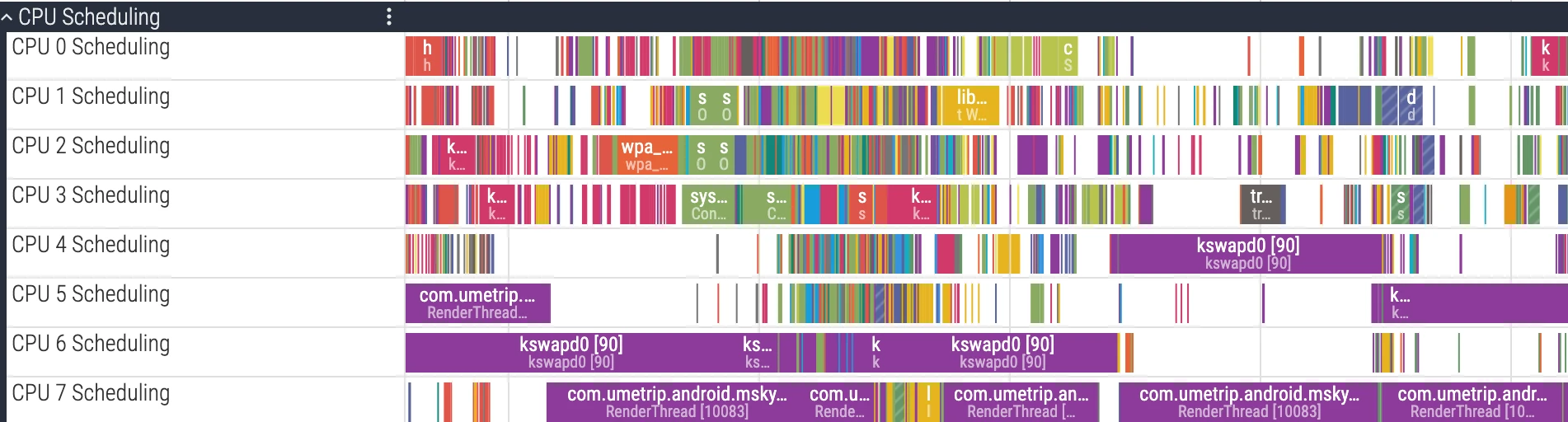
每个 CPU 核心对应一行独立的轨迹。轨道上的不同色块,代表了在该时间片上,特定线程正在该 CPU 核心上运行。
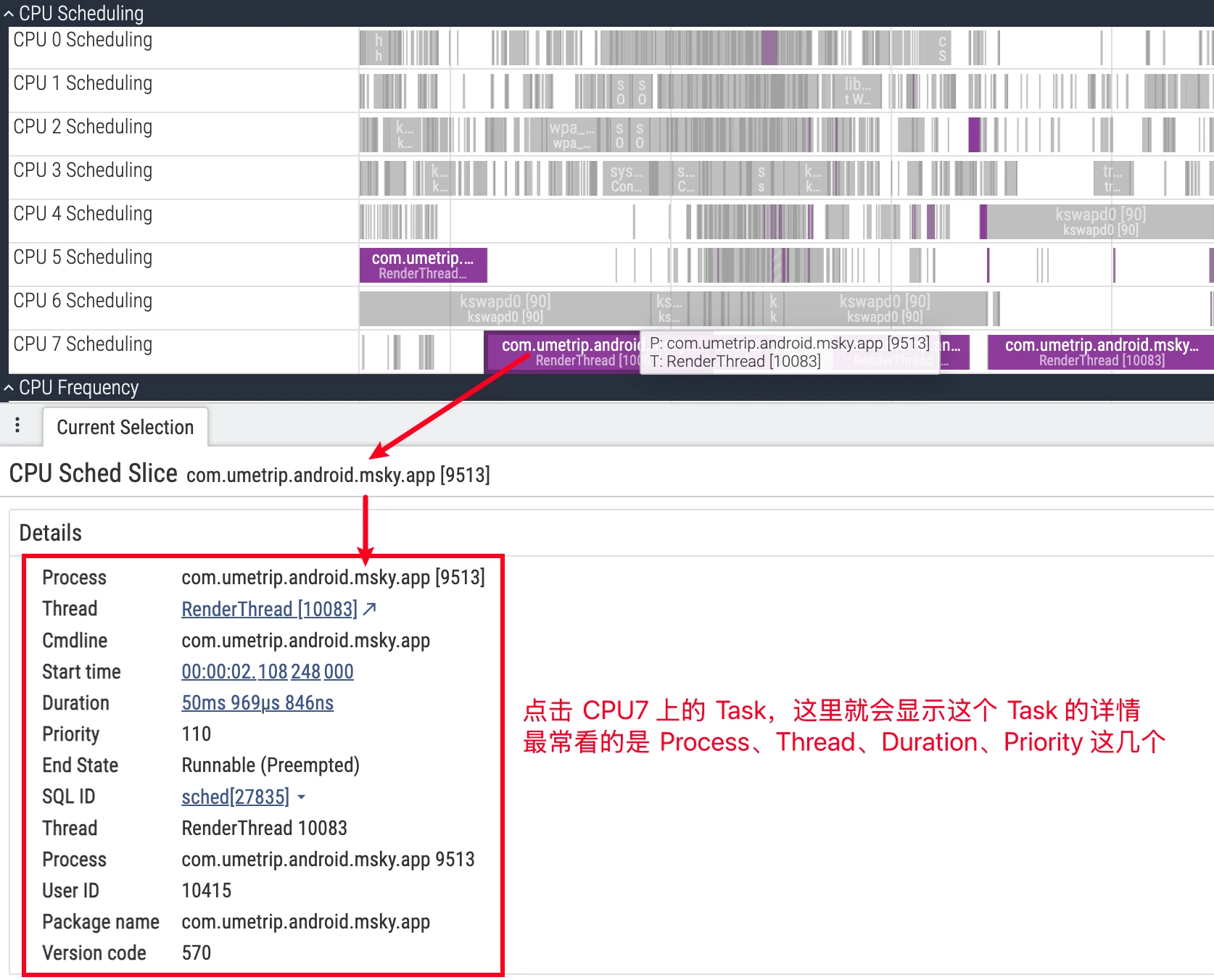
- UI 细节:点击 CPU 切片,详情面板会显示该次调度的
cpu、end_state、priority、所属process/thread等;向下展开进程还能看到每个线程的独立轨道,便于跟踪单个线程的状态演化(参考 官方文档)。
线程状态深度解析
理解 Linux 的线程状态是进行性能优化的前提。在 Perfetto 中,选中一个线程,下方的 Current State 面板会显示其当前状态。这些状态信息来源于 Perfetto 解析得到的 thread_state/thread_state_slice 表。
Running (绿色)
状态定义:绿色代表线程正在 CPU 上执行代码。这是唯一真正在消耗 CPU 资源进行计算的状态。
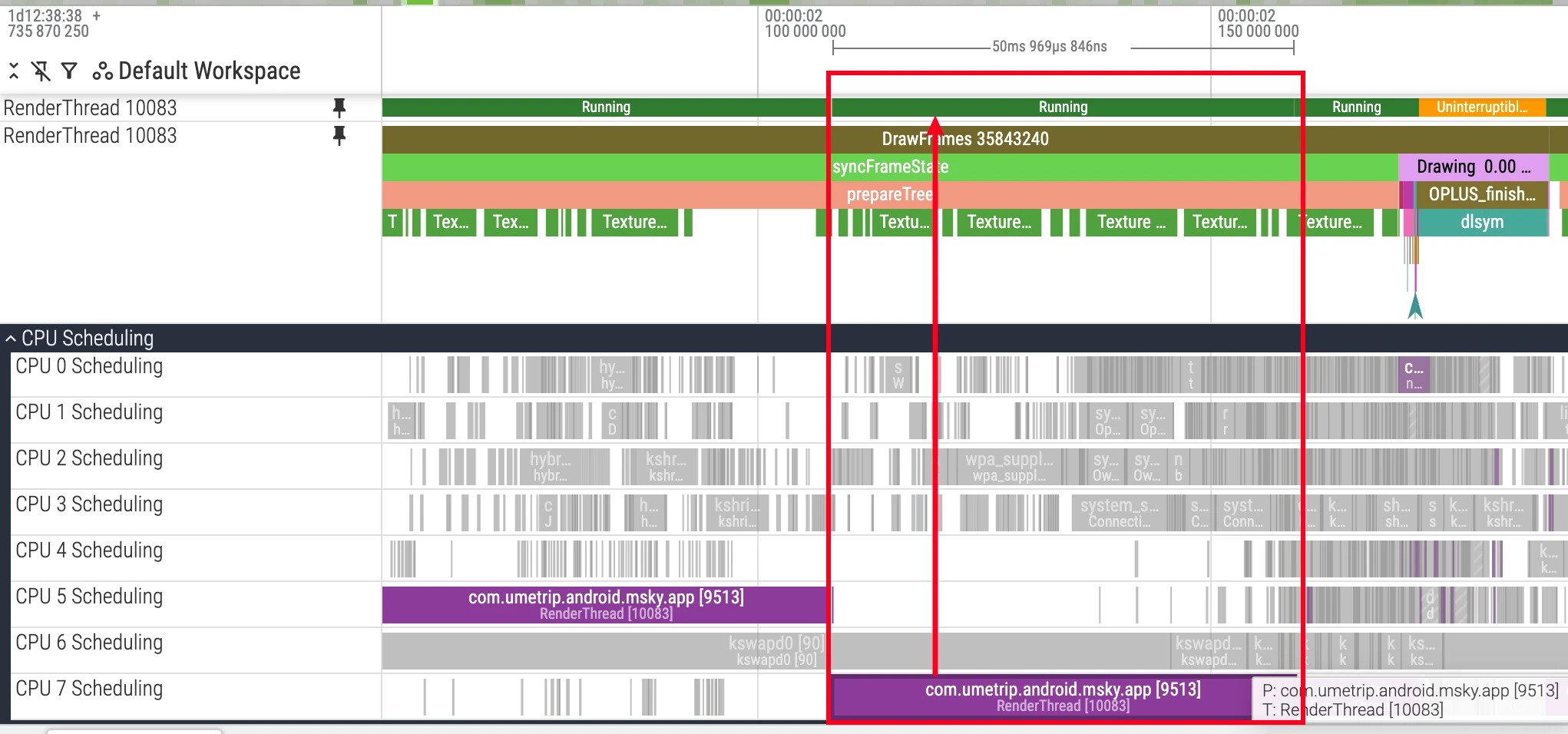
分析要点:
- 执行时长:过长的
Running状态,尤其是在关键线程上,通常意味着密集的计算任务,例如复杂的算法或循环。这会增加任务耗时,并可能阻塞其他线程的执行。 - 运行核心:结合 CPU 的核心架构(例如 big.LITTLE)进行分析。一个计算密集型任务是否被调度到了预期的性能核心(大核)上,是评估调度策略是否合理的重要依据。
- 运行频率:线程的实际执行速度也受 CPU 频率影响。即使线程运行在大核上,如果因为温控等原因导致降频,其性能表现也会下降。因此需要结合
CPU Frequency轨道进行综合分析。
R (Runnable / 可运行)
状态定义:线程已具备所有运行条件,正在等待调度器分配 CPU 核心。在 Perfetto 的线程私有轨道中,Runnable 状态通常以浅绿色或白色条显示。
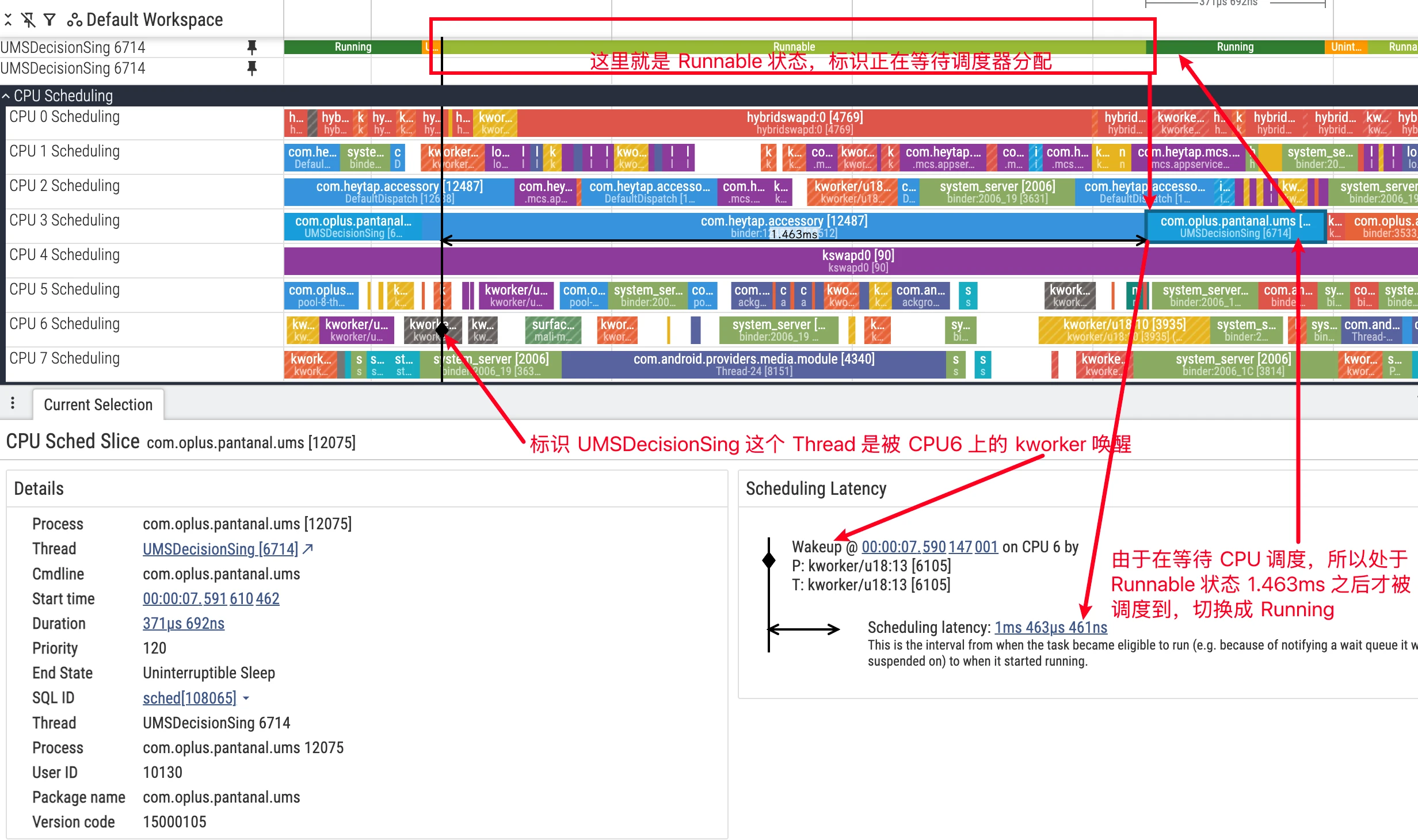
分析要点:
Runnable与卡顿:对于 UI 线程这类对响应时间敏感的线程,长时间处于Runnable状态是造成卡顿的直接原因。它意味着线程无法及时获得 CPU 时间来处理任务(如 UI 绘制),从而导致掉帧。
Runnable 的三种类型:
仔细观察会发现,线程进入 Runnable 状态的“前身”各不相同。根据内核的调度时机,我们可以将其分为三种情况:
从睡眠中唤醒-Wake-up:这是最常见的一种。线程因等待的资源(如锁、I/O、Binder 回复)已经就绪,从
S或D状态被唤醒,进入Runnable状态,等待被调度器选中执行。用户抢占-User Preemption:指线程的运行时间片用完,或出现更高优先级的任务,导致调度器在从内核态返回用户态时(如系统调用、中断返回后)决定换下当前线程。此时,被换下的线程从
Running变为Runnable。在底层的sched_switchtrace 中,它的prev_state标记为R。内核抢占-Kernel Preemption:指一个更高优先级的任务或中断,在当前线程正在执行内核态代码期间,就“强行”将其打断,使其让出 CPU。这种情况通常意味着一次更紧急的调度。此时,被换下的线程从
Running变为Runnable (Preempted)。在底层 trace 中,它的prev_state标记为R+,Perfetto 据此进行了解析和展示。
理解这三种类型的区别,有助于更精细地判断调度延迟的原因。例如,大量的 Runnable (Preempted) 可能暗示着系统中存在频繁的、高优先级的唤醒源,导致关键线程在内核态中被频繁打断,或者当时的 CPU 已经满载了(比较常见的情况),这时候优先级比较低的 Task 就很容易被其他优先级高的 Task 抢占,被迫让出 CPU 。如果你的关键 Task 总是被抢占,那就需要调整优先级。

S (Sleep / 可中断睡眠)
状态定义:线程因等待某个事件而进入睡眠,可以被信号中断。这是最常见的睡眠状态,通常情况下是良性的,因为它在等待期间不消耗 CPU 资源。
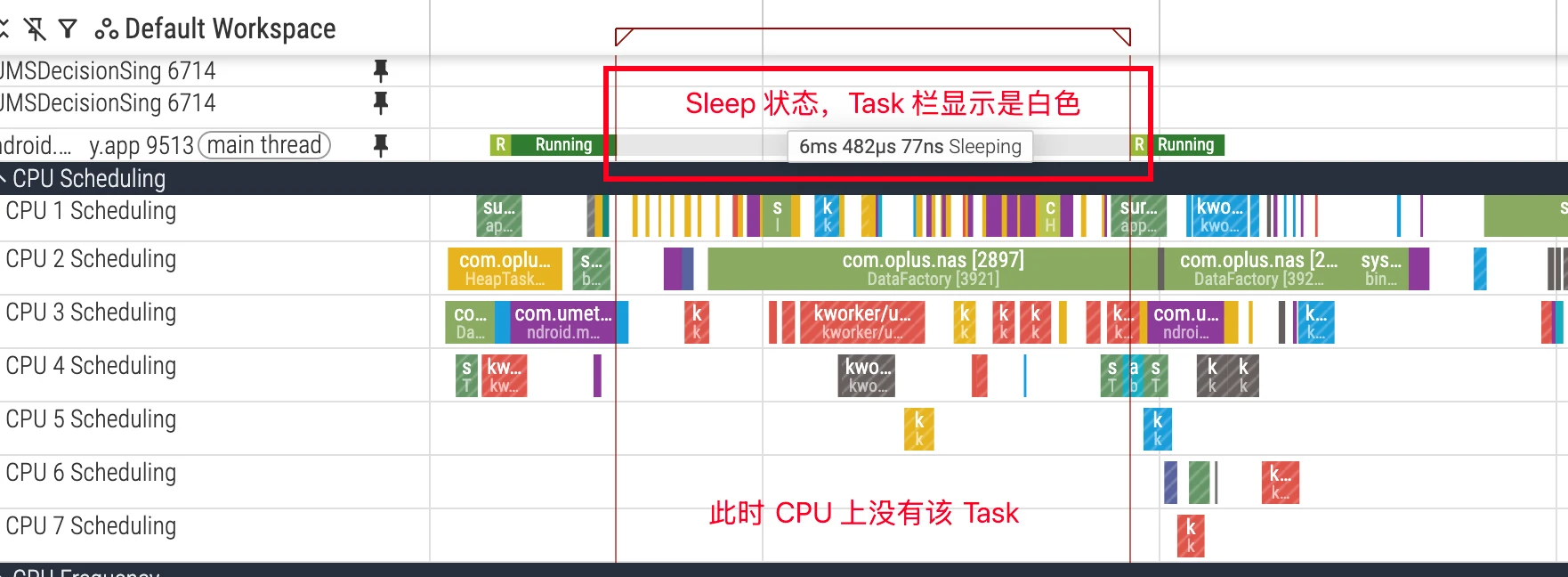
分析要点:
- 等待的资源:如果关键线程(如 UI 线程)睡眠时间过长,同样会引发性能问题。常见的等待原因包括:
- 锁竞争:等待获取一个
mutex(Java 锁或 native futex)。 - Binder 通信:等待另一个进程通过 Binder 调用返回结果。
- I/O 操作:等待网络 socket 数据 (
epoll_wait)。 - 显式休眠:代码中调用了
Thread.sleep()或Object.wait()。
- 锁竞争:等待获取一个
- 依赖分析:在 Perfetto 中,选中 CPU 区域被唤醒正在 Running 的 Task,就会有 UI 标识他是被哪个 CPU 上的哪个 Task 唤醒的,这有助于快速定位线程间的依赖关系。结合函数调用栈,可以进一步定位导致睡眠的具体代码。
D (Uninterruptible Sleep / 不可中断睡眠)
状态定义:线程在等待硬件 I/O 操作完成,期间不能被任何信号中断。此状态旨在保护进程与设备交互过程中的数据一致性。在 Perfetto 中,该状态通常显示为橙色或红色,是需要重点关注的信号。

分析要点:
- 严重的性能瓶颈:长时间的
D状态意味着线程被完全阻塞,无法响应任何事件。如果发生在 UI 线程,极易导致 ANR。 - 常见原因:
- 磁盘 I/O:频繁或单次大量的文件读写操作。
- 内存压力:系统物理内存不足,导致频繁的页面换入/换出 (swap),其本质是高频的磁盘 I/O。
- 内核驱动问题:部分内核驱动的实现缺陷也可能导致线程陷入
D状态。
- 排查方向:在
Current State面板中,如果D状态伴有(iowait)标记,则明确表示在等待 I/O。需要检查应用的 I/O 模式,评估其合理性,例如是否将耗时 I/O 操作置于主线程,或是否存在可优化的空间(如减少 I/O 次数和数据量)。
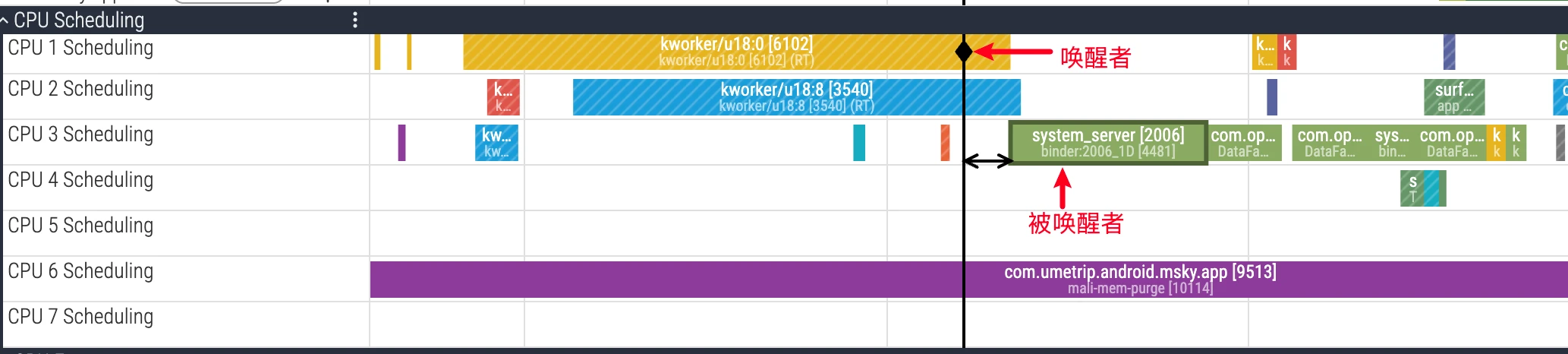
唤醒关系分析
线程间的依赖关系是性能分析中的一个难点。一个线程长时间 Sleep,关键在于找出它在“等谁”。Perfetto 提供了强大的唤醒关系可视化功能。
- UI 操作:在 Perfetto 的 CPU 区域中,用鼠标左键单击选中一个处于
Running状态的线程 Task 。Perfetto 会自动绘制一条从“唤醒者”到“被唤醒者”的依赖箭头,并高亮显示唤醒源所在的线程切片。 - 底层原理:该功能依赖于内核的
sched_wakeupftrace 事件。当线程 T1 释放了某个资源(如解锁、完成 Binder 调用),而线程 T2 正在等待该资源时,内核会将 T2 标记为Runnable状态,并记录下 T1 -> T2 的这次唤醒事件。Perfetto 解析这些事件,从而构建出线程间的依赖链。
通过唤醒分析,可以清晰地追踪复杂的调用链,例如:UI 线程等待一个 Binder 调用 -> Binder 线程执行任务 -> Binder 线程等待另一个锁 -> 持锁线程释放锁并唤醒 Binder 线程 -> Binder 线程完成任务并唤醒 UI 线程。整个过程中的瓶颈点将一目了然。
调度唤醒与延迟分析
当线程 A 在 wait() 上挂起时,它进入 S(Sleeping)并从 CPU 运行队列移除。线程 B 调用 notify() 后,内核会把线程 A 转换为 R(Runnable)。此时线程 A“有资格”被放回某个 CPU 的运行队列,但这并不意味着“立刻”运行。
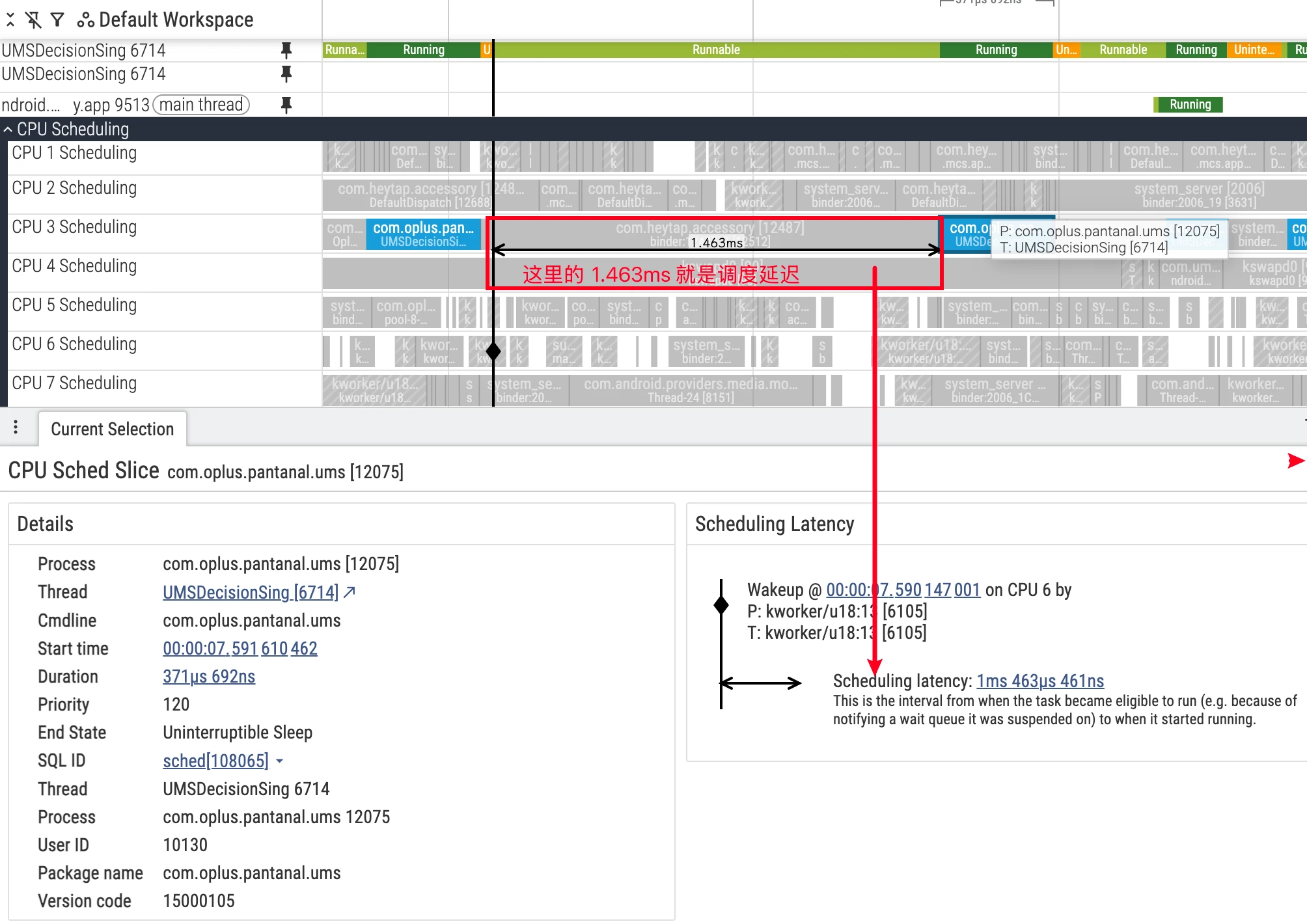
常见等待原因包括:
- 所有 CPU 都在忙:线程 A 需要等待空出队列槽位(或当前运行的线程优先级更高)。
- 存在空闲 CPU,但迁移需时:负载均衡器将线程迁移到其他 CPU 需要一定时间窗口。
除非使用实时优先级,大多数 Linux 调度器配置并非严格的“work‑conserving”。调度器有时会“等待”当前 CPU 线程自然空闲,以避免跨 CPU 迁移带来的额外开销与功耗。这会在 R 状态下形成可观测的“排队延迟”。结合 sched_waking/sched_wakeup_new 可更精确地刻画“被唤醒”到“真正入队/运行”之间的时间段(参考官方文档:sched_waking / sched_wakeup 的差异与适用场景)。
- 在目标线程的
thread_state轨道中筛选state=R的切片,用作“调度延迟”的直接证据。 - 同步对照同一 CPU 的其它重负载线程与 IRQ/SoftIRQ 轨迹,验证是否存在时间重叠的抢占或高优先级压制。
- 若频繁在
R状态排队并以end_state=R+收尾,视为非自愿抢占严重,需评估优先级、放置与负载均衡策略。
sched_waking 与 sched_wakeup 的差异与非严格 work-conserving
sched_waking在线程被标记为可运行(R)时就会发出,sched_wakeup与跨 CPU 唤醒有关,可能记录在源或目的 CPU 上;对大多数延迟分析而言,仅sched_waking已足够(参见官方说明)。- 多数 Linux 调度配置在通用优先级下并非严格“work-conserving”。调度器有时会“等待当前 CPU 空闲”以避免跨核迁移带来的额外开销与功耗,这会造成 R 状态下的等待时间(排队延迟)并非异常,而是权衡后的结果(参见 Perfetto CPU Scheduling)。
用户态与内核态:sys_* 切片定位空火焰图
Running的绿色切片未必都是应用代码在忙。若线程陷入单个长系统调用如sys_read、sys_futex,用户态采样火焰图可能几乎为空。- 若 UI 线程某段
sched_slice很长,而 CPU 火焰图热点很少或几乎没有:- 打开该线程的
slice视图,查找是否存在长时间sys_*切片; - 若存在:瓶颈多在 I/O 或同步原语,优先检查 I/O 路径、锁粒度与访问模式;
- 若不存在:回到火焰图,继续剖析用户态热点函数。
- 打开该线程的
- 建议:合并 I/O、切换异步、优化锁竞争、降低系统调用频率与单次数据量。
CPU 时间与墙上时间
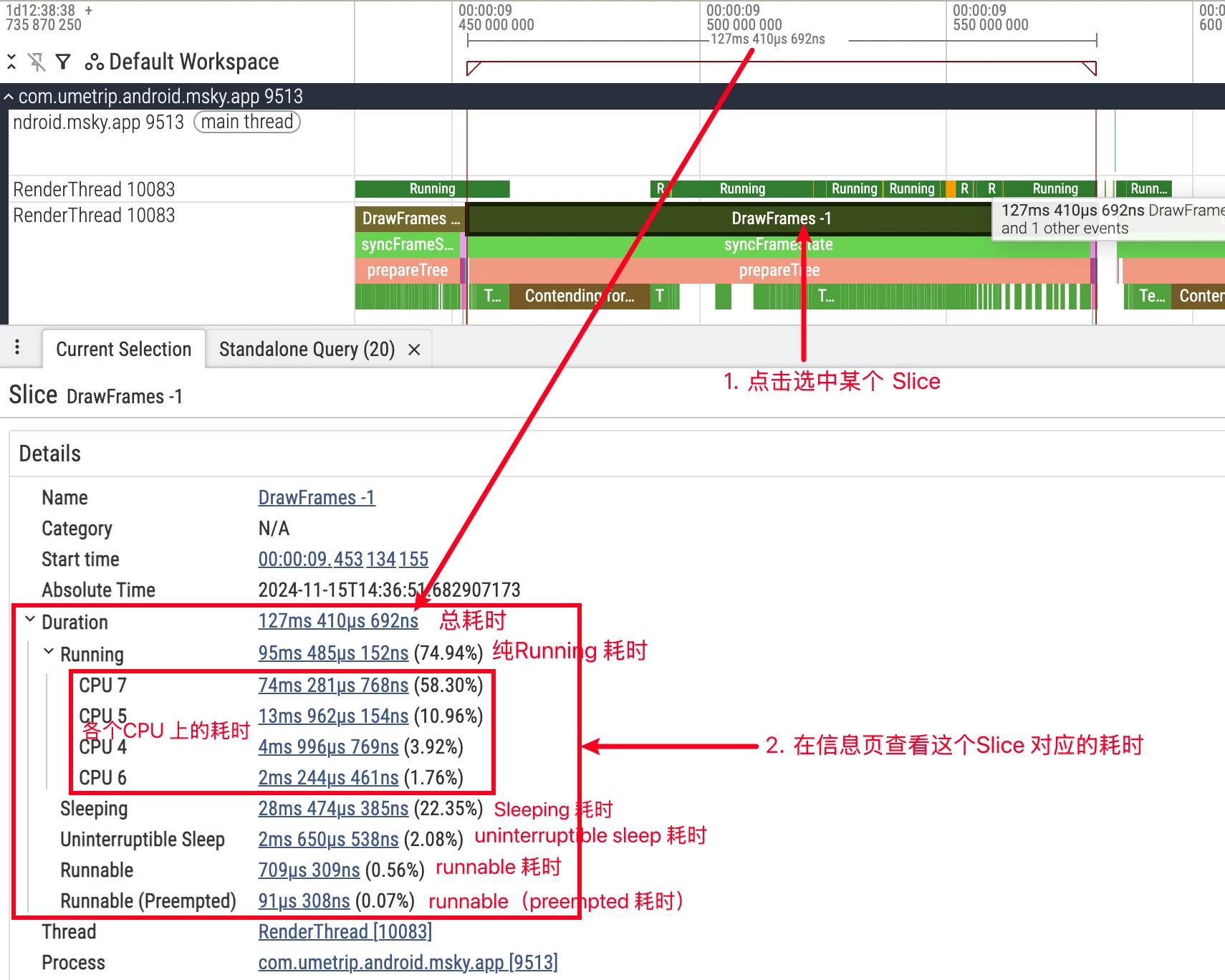
Wall是切片从开始到结束的真实世界时间,CPU是真正在 CPU 上运行的时间。- 二者关系:
Wall = CPU + Runnable + Sleep。- 选中目标切片(如
Choreographer#doFrame),比较Wall与CPU; - 若
Wall ≈ CPU,则为计算过重,使用火焰图定位热点;\n 3) 若Wall >> CPU,则为调度或依赖等待,查看thread_state的R/S/D分布与唤醒链。
- 选中目标切片(如
CPU Frequency (CPU 频率) 深度解析
CPU 频率直接影响代码执行速度,同时也与功耗正相关。CPU Frequency 轨道显示了每个核心在特定时间的运行频率(scaling_cur_freq)。但更重要的是理解其背后的限制因素:
影响 CPU 频率的核心因素
任务负载 (Task Utilization): 这是最主要的驱动因素。现代 Android 系统多采用
schedutil作为cpufreq调频策略。它直接关联调度器(Scheduler),根据线程的“繁忙”程度(utilization)来决定频率。一个高负载的线程(util很高)会促使schedutil请求更高的频率,反之亦然。场景策略 (Power HAL): Android Framework 通过 Power HAL 向底层传递当前的系统状态,即“场景”。例如,在应用启动、游戏、或触摸屏幕时,Power HAL 会向内核请求更高的性能,这通常通过抬高 CPU 的地板频 (Floor /
scaling_min_freq) 和/或 天花板频 (Ceiling /scaling_max_freq) 来实现,确保 CPU 能快速响应。温度控制 (Thermal Throttling): 这是拥有最高优先级的限制。当设备温度(来自电池、CPU、NPU 等传感器)超过预设阈值时,温控系统会强制降低 CPU 的天花板频,以减少发热,保护硬件。此时,即使有高负载任务,CPU 频率也无法提升,是导致游戏掉帧、应用卡顿的常见外部原因。
功耗限制与省电模式: 在低电量或开启省电模式时,系统同样会通过降低天花板频、限制最高性能输出来延长续航。
因此,当发现一个重任务在运行时 CPU 频率上不去,不仅要看当前频率,更要关注 scaling_max_freq 是否被限制了。这通常意味着性能瓶颈的根源不在于应用代码本身,而在于系统的温控或功耗策略。
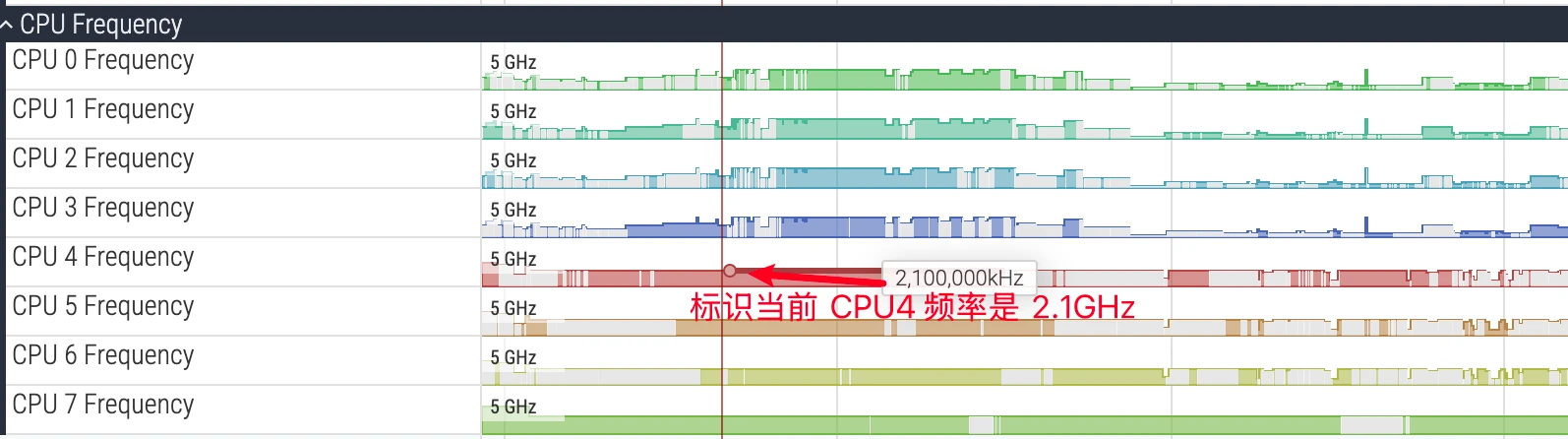
上图是 CPU 频率区域的标识图,鼠标放上去就可以看到当前的频率,CPU 频率变化很快。图中 CPU 有带颜色和不带颜色的部分,带颜色标识当前 CPU 有 Task 在跑,不带颜色说明当前 CPU 是空的,无 Task。
频率数据采集与平台差异
- 两种获取方式:
- 事件驱动:启用
power/cpu_frequency,在内核 cpufreq 驱动变更频率时记录事件。并非所有平台支持,在多数 ARM SoC 上可靠,在大量现代 Intel 平台上常无数据。 - 轮询采样:启用
linux.sys_stats并设置cpufreq_period_ms > 0,定期读取/sys/devices/system/cpu/cpu*/cpufreq/cpuinfo_cur_freq,ARM/Intel 均可用。建议与事件驱动组合使用以补齐“初始频率快照”。
- 事件驱动:启用
- Android 设备常以“簇”为单位调频,常见现象是同簇内多个 CPU 同步变频。
- 已知问题:
- 事件仅在频率变化时产生,短 Trace 或稳定场景可能出现左侧“空白”。此时需依赖轮询补足。
- 某些 UI 版本在未捕获 Idle 状态时不渲染 cpufreq 轨道,但数据仍可通过查询得到。
- 参考:
CPU frequency and idle states官方说明。
big.LITTLE:相同频率不等于相同性能或能耗
- 在异构 CPU 上,同为 2.0GHz,小核与大核的实际算力和能耗并不等价。频率必须结合核心类型理解。
- 核心容量(capacity)与 IPC:大核通常具备更宽的乱序执行、更多执行端口、更大的缓存与更激进的预取/分支预测,单位周期完成的指令数(IPC)更高;同频下,大核完成同样工作所需时间更短、能量更少。
- 簇级 DVFS(cluster-level DVFS):移动 SoC 多以“簇”为单位调频。小核簇的高频并不等同于大核簇的中频性能输出;不同簇的电压-频率-能量曲线不同,同一频点无法横向类比“每瓦性能”。
- 内存/缓存/互联瓶颈:热点若受制于内存带宽、LLC 命中率或系统互联(NoC),单纯提升小核频率收益有限;大核更大的缓存/更强预取可显著降低同任务的访存等待,体现“同频不同效”。
- 能效曲线非线性:小核在接近最高频时常进入能效陡降区(电压抬升使边际能耗激增),而大核在中等频点可能达到“更高单位能效”。同频比较忽略了“电压-频率-能量”的三维权衡。
P-States 与 governor
- CPU 频率并非连续值,而是离散的性能状态 P-States。常用 governor 为
schedutil,依据任务利用率等信号选择合适 P-State,并联动电压调节。 - UI 上的频率变化,实质是 governor 在不同 P-State 之间切换。高频不必然更快或更省电,需要结合核簇类型与当时的上限/下限约束理解。
- 核验步骤:
- 在
CPU Frequency观察频率的上下限是否被拉高/压低(如场景策略/温控限制scaling_max_freq)。 - 在
CPU Scheduling查看关键线程运行在哪类核心(结合设备的核编号划分)。 - 若“高频 + 小核 + 仍慢”,优先考虑选核/访存瓶颈,而非简单“频率不够”。
- 在
- 建议结合 Power HAL 场景、热管理与任务画像(CPU 密集或访存密集)综合优化,避免单纯以频率作为调参目标。参考官方文档: Perfetto CPU Scheduling。
Linux 内核调度策略:选核与迁移
理解了线程状态和频率后,我们还需要深入了解 Linux 内核调度器(在 Android 中主要是 EAS - Energy Aware Scheduling)的两个核心行为:如何为任务挑选一个 CPU 核心,以及为何要将任务从一个核心迁移到另一个。
选核逻辑 (Task Placement)
当一个线程从 Sleep 状态被唤醒,或一个新线程被创建时,EAS 调度器需要为它选择一个最合适的 CPU 核心。其核心目标是在满足任务性能需求的前提下,尽可能地降低系统功耗。决策流程大致如下:
- 评估任务负载 (Task Utilization): 调度器会评估该线程的
util,即它需要多少计算资源。这是一个动态调整的值,反映了线程历史上的繁忙程度。 - 寻找“足够”的核心: 调度器会遍历所有可用的 CPU 核心,比较任务的
util和每个核心的capacity(容量/最大计算能力)。大核的capacity远高于小核。调度器会寻找capacity>util的核心,即能“装下”这个任务的核心。 - 寻找“最节能”的核心: 在所有满足
capacity要求的核心中,调度器会利用预置在内核中的“能量模型”(Energy Model)进行计算。这个模型知道每个核心在每个频率下运行的功耗。调度器会选择一个能让整个系统(包括任务本身和其他正在运行的任务)总功耗最低的 CPU 核心作为最终选择。
简而言之:EAS 的目标不是为任务找一个最快的核,而是找一个“刚刚好够用”且“最省电”的核。
核心迁移逻辑 (Task Migration)
将任务从一个 CPU 核心移动到另一个,是调度器进行动态调优的关键手段。主要发生在以下情况:
负载均衡 (Load Balancing): 这是最常见的迁移原因。调度器会周期性地检查系统是否处于“负载不均衡”状态。例如,
CPU-1(小核)上挤满了高负载任务导致其利用率饱和,而CPU-7(大核)却很空闲。此时,调度器会判定系统失衡,并将CPU-1上的某个高负载任务“拉到”(pull)CPU-7上运行,以恢复平衡,提升性能。唤醒时迁移 (Wake-up Migration): 当一个线程睡醒时,调度器会重新评估它的最佳核心。如果这个线程在睡眠期间
util发生了变化(例如,一个后台下载线程突然收到了一个大文件下载任务,util飙升),或者原先运行的核心现在非常繁忙,调度器就可能在唤醒时直接为它选择一个更合适的新核心,而不是让它在原来的地方排队。
理解选核与迁移逻辑,有助于我们判断调度器的行为是否“异常”。例如,一个明显的前台 UI 线程被不合理地长时间限制在小核上,或者在大小核之间过于频繁地“反复横跳”,都可能暗示着系统调度策略或任务优先级设置存在问题。
当然目前 Android 厂商针对调度器有做非常多的客制化,关键 Task(Critical Task)通常会占用更多的 CPU ,甚至更容易上大核。另外还有很多绑核策略、签核策略,导致大家看到的每个厂商的现象都不一样。这也是各个厂商的核心竞争力(比如 Oppo 的蜂鸟引擎)。
实战与 SQL
使用 SQL 进行量化分析
Perfetto 内置的 SQL 查询引擎是其强大功能之一,允许开发者对 Trace 数据进行精确的聚合、筛选和分析。以下是一些常用的 CPU 分析查询。
1. 计算各进程的 CPU 总时长
此查询统计每个进程在所有 CPU 上运行的总时长,按降序排列,用于快速定位消耗 CPU 资源最多的进程。
1 | SELECT |
2. 分析单个线程的时间状态分布
此查询基于 thread_state 表,可用于分析特定线程(示例为 surfaceflinger)在各种状态下的时间分布,从而判断其主要瓶颈。
1 | SELECT |
3. 查找特定时间段内 CPU 消耗最高的线程
此查询用于分析特定场景(如应用启动的 2-5s 时间段)中,消耗 CPU 时间最长的线程。
1 | SELECT |
4. 查看线程在各 CPU 核心上的运行时间分布
此查询有助于了解一个线程的 CPU 亲和性,以及它是否在预期的大小核上运行。
1 | SELECT |
5. 计算各进程的 CPU 利用率
此查询计算了每个进程在整个 Trace 时间范围内的 CPU 利用率。
1 | SELECT |
总结
对 Perfetto 中 CPU 信息的熟练分析,是 Android 性能优化的关键技能。通过深度理解 核心架构、线程状态、唤醒关系、频率限制 和 C-State,并结合强大的 SQL 查询进行量化分析,开发者可以精准地定位并解决各类性能与功耗问题。
关于我 && 博客
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
- 博主个人介绍 :里面有个人的微信和微信群链接。
- 本博客内容导航 :个人博客内容的一个导航。
- 个人整理和搜集的优秀博客文章 - Android 性能优化必知必会 :欢迎大家自荐和推荐 (微信私聊即可)
- Android性能优化知识星球 : 欢迎加入,多谢支持~
一个人可以走的更快 , 一群人可以走的更远