本文是 Perfetto 系列的第十篇文章,聚焦 Binder 这一 Android 跨进程通信的核心机制。Binder 承载着大部分系统服务与应用的交互,也常常是性能瓶颈的源头。本文站在系统开发与性能调优的视角,结合 linux.ftrace(binder tracepoints + sched)、thread_state 轨道,以及 ART 的 Java Monitor Contention(通过 atrace 的 dalvik 类别采集)等信号,给出一套可直接落地的诊断流程,帮助初学者和进阶开发者定位耗时、线程池压力与锁竞争等问题。
本系列的目标,就是通过 Perfetto 这个工具,从一个全新的图形化视角,来审视 Android 系统的整体运行,同时也提供一个学习 Framework 的新途径。或许你已经读过很多源码分析的文章,但总是对繁杂的调用链感到困惑,或者记不住具体的执行流程。那么通过 Perfetto,将这些流程可视化,你可能会对系统有更深入、更直观的理解。
本文目录
Perfetto 系列文章
- Android Perfetto 系列目录
- Android Perfetto 系列 1:Perfetto 工具简介
- Android Perfetto 系列 2:Perfetto Trace 抓取
- Android Perfetto 系列 3:熟悉 Perfetto View
- Android Perfetto 系列 4:使用命令行在本地打开超大 Trace
- Android Perfetto 系列 5:Android App 基于 Choreographer 的渲染流程
- Android Perfetto 系列 6:为什么是 120Hz?高刷新率的优势与挑战
- Android Perfetto 系列 7 - MainThread 和 RenderThread 解读
- Android Perfetto 系列 8:深入理解 Vsync 机制与性能分析
- Android Perfetto 系列 9 - CPU 信息解读
- Android Perfetto 系列 10 - Binder 调度与锁竞争
- 视频(B站) - Android Perfetto 基础和案例分享
- 视频(B站) - Android Perfetto 分享 - 出图类型分享:AOSP、WebView、Flutter + OEM 系统优化分享
Binder 基础与案例
对于首次接触 Binder 的读者,理解它的角色和参与者至关重要。可以先把 Binder 粗暴地理解成“跨进程的函数调用”:你在一个进程里像调用本地接口一样写代码,真正的调用和数据传输则由 Binder 帮你完成。整体上它是 Android 的主力跨进程通信(IPC)机制,核心包含四个组件:
- Client:应用线程通过
IBinder.transact()发起调用,将Parcel序列化的数据写入内核。 - Service(Server):通常运行在 SystemServer 或其他进程中,通过
Binder.onTransact()读取Parcel并执行业务逻辑。 - Binder Driver:内核模块
/dev/binder负责线程池调度、缓冲区管理、优先级继承等,是连接双方的“信使”。 - Thread Pool:服务端通常维护一组 Binder 线程。需要注意的是,线程池并不是一开始就创建满的,而是按需创建。Java 层默认最大线程数约为 15 个 Binder 工作线程(不含主线程),Native 层通过
ProcessState也可以配置最大线程数(默认值通常也是 15)。当所有 Binder 线程都忙碌时,新的请求就会在驱动层排队等待空闲线程。
为什么需要 Binder?
Android 采用多进程架构来隔离应用、提升安全性与稳定性。每个 APK 运行在独立的用户空间,当需要访问系统能力(相机、位置、通知等)时,必须跨进程调用 Framework 或 SystemServer。
传统 IPC 方案的局限:
| IPC 方式 | 问题 |
|---|---|
| Socket | 开销大,缺少身份校验 |
| Pipe | 仅支持父子进程,单向通信 |
| 共享内存 | 需要额外的同步机制,缺少访问控制 |
Binder 在内核层解决了这些问题,提供了三个关键能力:一是身份与权限(基于 UID/PID 校验,确保调用方合法);二是同步与异步调用(同步模式下 Client 等待 Server 返回,这是最常见的模式,而异步模式下 Client 发送后立即返回,适用于通知、状态上报等场景);三是优先级继承(当高优先级 Client 调用低优先级 Server 时,Server 会临时提升优先级,避免优先级反转问题)。
因此,当应用进程在启动阶段通过 IActivityManager#attachApplication() 把自己“挂到” SystemServer 时,底层必然借助 Binder 把调用安全、可靠地传递给 system_server。
从 App 开发者视角的案例
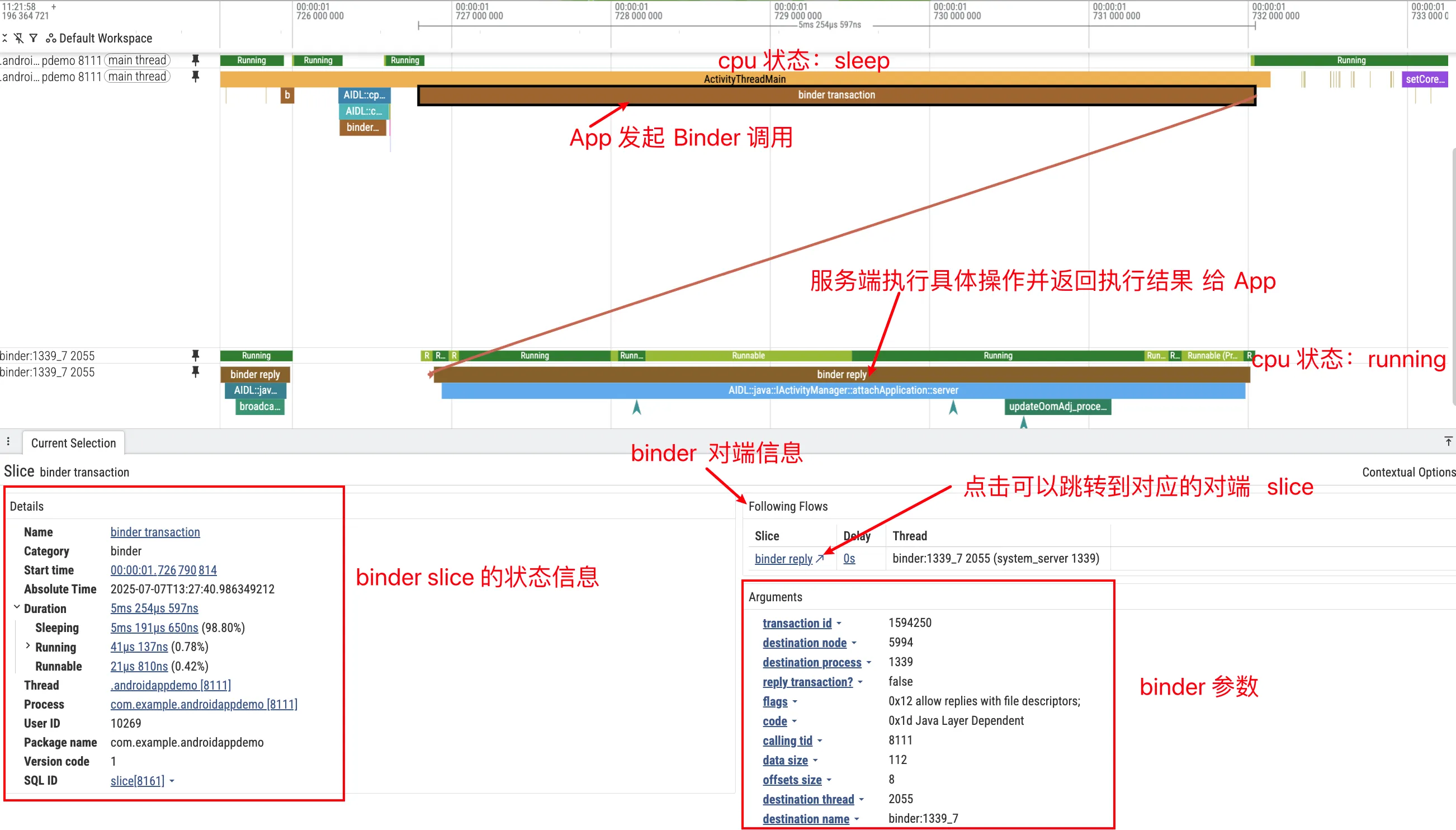
假设我们在 Trace 里关注到 AIDL::java::IActivityManager::attachApplication::server。它对应的是应用进程通过 IActivityManager#attachApplication(...) 发起的一次同步 Binder 调用,服务端实现位于 system_server 的 ActivityManagerService。调用路径可以概括为:首先,在 Proxy 侧,应用进程通过 ActivityManager.getService() 拿到一个 IActivityManager 的代理对象(BinderProxy);然后进行序列化,调用 attachApplication(...) 时,代理会把参数写入 Parcel,执行 transact();接着是内核传输,Binder 驱动将该事务排入 system_server 的 Binder 线程队列,并唤醒一个空闲线程(例如 Binder:1460_5);随后在 Stub 侧,ActivityManagerService(Stub)所在的线程被唤醒,读取参数并进入 attachApplication 的处理流程;最后是返回阶段,Service 处理完毕,将结果写入 Parcel,驱动唤醒原 App 线程,App 线程从 waitForResponse() 返回继续执行。
在 Perfetto 中,这条链路会显示为:Android Binder / Transactions 轨道上的一次事务(如果 trace 中能解析到 AIDL 信息,Slice 名称会类似 AIDL::java::IActivityManager::attachApplication::client/server,或在 SQL 中体现为 aidl_name=IActivityManager、method_name=attachApplication);App 线程在 thread_state 里处于 S (Sleeping) 状态(同步调用时常见),且 blocked_function 通常涉及 binder_thread_read / epoll_wait / ioctl(BINDER_WRITE_READ);SystemServer 的 Binder 线程出现 Running 切片;以及 Flow 箭头(Perfetto 会用箭头把 Client 的 transact 和 Server 的处理线程连接起来)。
Perfetto 观测准备
要在 Perfetto 中诊断 Binder,需要提前准备好数据源与 Trace 配置。
数据源与轨道总览
Binder 分析需要把「事务事件」和「线程调度/阻塞/锁」串起来。录制侧主要依赖 linux.ftrace(包含 Binder tracepoints、调度事件以及可选的 atrace 类别),再配合少量元数据源(进程/线程命名映射)。
linux.ftrace(内核层 + atrace) 是最通用、最基础的数据源,兼容所有 Android 版本。它直接读取内核的 ftrace 事件,包括 binder_transaction(事务开始)、binder_transaction_received(服务端收到事务)、binder_transaction_alloc_buf(缓冲区分配,诊断 TransactionTooLarge)等;再配合调度相关事件(sched_switch、sched_waking)即可还原出 “Client 发起调用 → 内核唤醒 Server 线程 → Server 处理 → 返回” 的链路。
另外,linux.ftrace 里还可以开启 atrace 类别来补充用户态 Slice:binder_driver/am/wm 等有助于解释系统服务语义;dalvik 则用于采集 ART 的 monitor contention(Java synchronized 竞争),从而在 UI 里出现 Thread / Lock contention 相关轨道。
linux.process_stats(元数据) 用于把 PID/TID 映射成进程名/线程名,方便在 UI 和 SQL 中阅读与过滤。开销极低,建议常开。
说明:Perfetto UI 中的 Android Binder / Transactions、Android Binder / Oneway Calls 轨道,以及 PerfettoSQL 标准库中的
android.binder/android.monitor_contention模块,都是在 trace processor 侧基于上述原始事件解析/聚合出来的,并不是需要额外开启的“录制数据源”。
Trace Config 推荐
以下配置兼顾了兼容性与新特性,建议作为标准的 Binder 分析模板。将配置保存为 binder_config.pbtx 即可使用:
1 | # ============================================================ |
配置项说明
| 数据源 | 作用 | Android 版本要求 | 开销 |
|---|---|---|---|
linux.ftrace (binder/*) |
内核层 Binder 事件 | 所有版本 | 低 |
linux.ftrace (sched/*) |
调度事件,串联线程唤醒 | 所有版本 | 中 |
linux.ftrace (atrace: dalvik/…) |
Framework Slice + Java Monitor Contention | 所有版本(字段随版本演进) | 低-中 |
linux.process_stats |
进程名称和 PID 映射 | 所有版本 | 极低 |
提示:本文的 Binder 分析工作流只依赖
linux.ftrace(binder tracepoints + sched + dalvik),因此 Android 12/13/14+ 的抓取思路基本一致。不同版本的 UI 字段名可能略有差异,遇到差异时推荐用 Perfetto SQL(stdlib)做校验。
快速上手:3 步抓取与查看 Binder Trace
抓取 Trace:
1
2
3
4
5
6
7
8
9
10
11# 推送配置
adb push binder_config.pbtx /data/local/tmp/
# 开始抓取
adb shell perfetto --txt -c /data/local/tmp/binder_config.pbtx \
-o /data/misc/perfetto-traces/trace.pftrace
# ... 操作手机复现卡顿 ...
# 取出文件
adb pull /data/misc/perfetto-traces/trace.pftrace .打开 Trace:访问 ui.perfetto.dev,拖入 trace 文件。
添加关键视图:
- 左侧点击 Tracks → Add new track
- 搜索 “Binder”,添加 Android Binder / Transactions 和 Android Binder / Oneway Calls
- 搜索 “Lock”,添加 Thread / Lock contention(如果有数据)
其他 Binder 分析工具
除了 Perfetto,还可以用两个工具辅助定位:am trace-ipc(系统自带)和 binder-trace(开源,能力更强但门槛更高)。
am trace-ipc:Java 层 Binder 调用追踪
am trace-ipc 用于追踪 Java 层 Binder 调用堆栈。系统会在目标进程开启 Binder stack tracking(BinderProxy.transact() 路径),在停止时导出文本统计。优点是零配置、无需 root。
基本用法很简单,就是”开始 → 操作 → 停止导出”三步:
1 | # 1. 开始追踪(系统会记录符合条件进程的 Binder 调用,通常以可调试进程为主) |
导出结果是纯文本,示例如下:
1 | Traces for process: com.example.app |
它会按进程分组,列出调用堆栈和次数(Count),适合快速回答“调了哪些服务、调了多少次”。
与 Perfetto 配合使用:Perfetto 看时间线与线程关系,trace-ipc 补“具体是哪个 Java 调用点发起调用”。
适用场景:怀疑卡顿/ANR 与频繁 IPC 有关,或需要定位具体 Java 发起点。
binder-trace:实时 Binder 消息解析
binder-trace 可以实时拦截并解析 Binder 消息,常被称为“Binder 的 Wireshark”,能看到接口、方法及部分参数。
它基于 Frida 动态注入,通常需要 root(或模拟器)和 frida-server,本地需 Python 3.9+。示例:
1 | # 追踪指定应用的 Binder 通信(-d 指定设备,-n 指定进程名,-a 指定 Android 版本) |
它支持按接口/方法/事务类型过滤,适合安全研究和逆向分析这类“看消息内容”的场景。日常性能排查通常仍以 Perfetto + am trace-ipc 为主。
Binder 分析工作流
拿到 Trace 后,不要直接在大海捞针。推荐按照“找目标 → 看耗时 → 查线程 → 找锁”的顺序进行。
步骤一:定位事务耗时
分析的第一步是找到你关心的那次 Binder 调用。在 Perfetto 中有几种常用的定位方式:如果你已经知道是哪个进程发起的调用,可以直接在 Transactions 轨道里找到你的 App 进程作为 Client 的区域;如果你知道调用的接口名或方法名,可以按 / 键打开搜索框,输入 AIDL 接口名(如 IActivityManager)、方法名(如 attachApplication),或者直接输入完整的 Slice 名(如 AIDL::java::IActivityManager::attachApplication::server)来快速定位;如果你是在排查 UI 卡顿问题,最直接的方式是先看 UI 线程的 thread_state 轨道,找到处于 S(Sleeping)状态且时长较长的片段——如果这段时间主线程几乎没有在执行代码,那很可能就是在等待 Binder 调用返回,这里就是分析的起点。
选中一个 Transaction Slice 后,右侧的 Details 面板会显示这次事务的详细信息(Client/Server 线程、时间戳、耗时等)。不同版本的 Perfetto UI 字段名可能略有差异,但你可以用 Perfetto SQL 的 android_binder_txns 来统一理解几个关键耗时:
client_dur:客户端端到端耗时(同步调用时基本等同于“我在等这次 Binder 返回”的时间)server_dur:服务端从开始处理到(同步时)发出 reply 的 wall clock 时长dispatch_dur = server_ts - client_ts:从客户端发起到服务端真正开始处理的延迟(常包含排队/线程可用性/调度影响)
下面这段 SQL 可以直接在 Perfetto UI 的 SQL 页面运行(用于快速找出最慢的同步事务,并拆出派发延迟与服务端耗时):
1 | INCLUDE PERFETTO MODULE android.binder; |
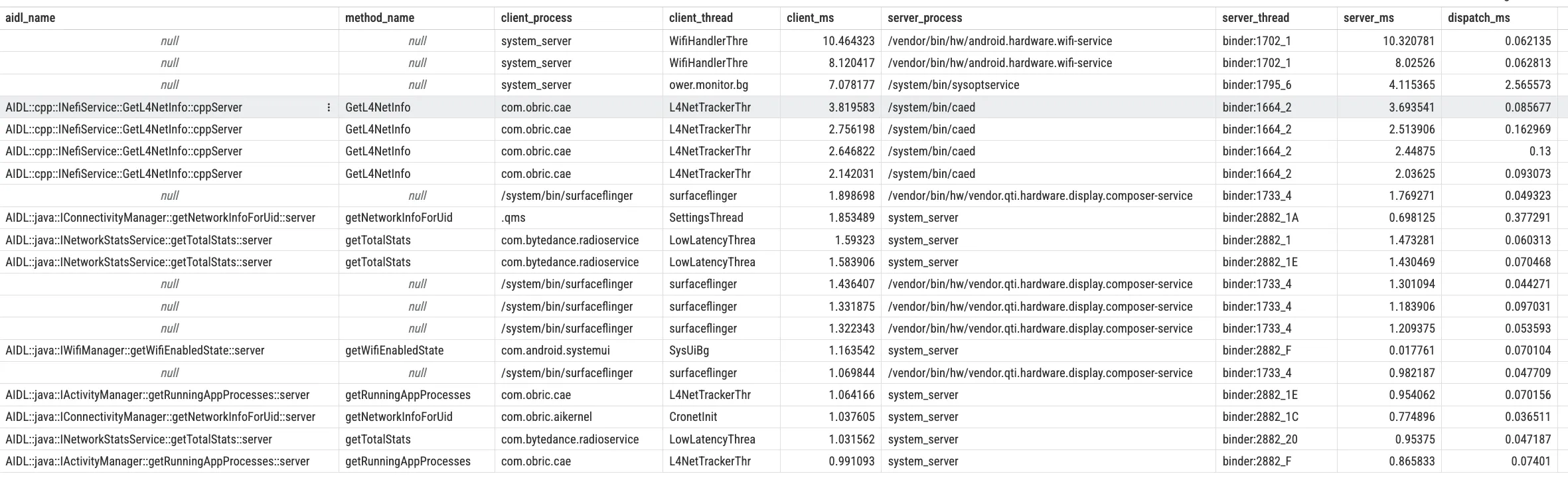
理解这些耗时之间的关系非常重要,因为它直接决定了你下一步应该往哪个方向深挖。如果 client_dur 很长但 server_dur 很短,通常说明慢主要不在服务端处理,而是在派发/排队(dispatch_dur 会很大),这时应该优先检查服务端线程池与调度情况(步骤二)。如果 server_dur 本身就很长,说明服务端处理慢,这时你需要跳转到服务端的 Binder 线程,看它在这段时间里到底在干什么——是在跑业务代码、等锁、还是等 IO。
步骤二:评估线程池与 Oneway 队列
如果步骤一的分析发现耗时主要不在服务端处理,而是在”排队”上,那就需要进一步检查 Binder 线程池的状态了。在深入分析之前,先回答一个经常被问到的问题:**”每个进程大概会有多少个 Binder 线程?system_server 的 Binder 线程池规模大致是什么量级?什么情况下会’耗尽’?”**
system_server 的 Binder 线程池规模
在上游 AOSP(Android 14/15)中,Binder 线程池的设计思路是:按需增长、可配置、没有单一固定数字。
- 线程池是按需增长的:每个服务端进程在 Binder 驱动中维护一个线程池,实际线程数会根据负载按需增减,上限由内核中的
max_threads字段和用户态ProcessState#setThreadPoolMaxThreadCount()等配置共同决定。 - 典型上限取决于进程角色:普通应用进程的 Binder 工作线程上限通常在 15 左右(libbinder 默认值);但
system_server会在启动时显式把上限调高,AOSP 当前代码中设置为 31。因此,system_server并不等同于“默认十几条线程”。
某些厂商 ROM 或定制内核会根据自身负载模型,把上限调大或调小(例如调到几十条线程),因此你在不同设备上通过ps -T system_server、top -H或 Perfetto 数Binder:线程时,看到的具体数字可能会有差异。 - 以实际观测为准,而不是死记一个数字:在 Perfetto 里,更推荐的做法是直接展开某个进程,看有多少个
Binder:xxx_y线程轨道,以及它们在抓 Trace 期间的活跃程度,以此来评估线程池的“规模”和“繁忙度”。
Binder 线程数、缓冲区与“Binder 耗尽”
在性能分析中,大家提到“Binder 个数”时,往往会混在一起谈三类不同的资源限制:
Binder 线程池耗尽是指某个进程内所有 Binder 工作线程都处于 Running / D / S 等忙碌状态,没有空闲线程可以被驱动唤醒处理新事务。其现象包括 Client 线程在 thread_state 轨道里长时间停留在 S 状态(调用栈停在 ioctl(BINDER_WRITE_READ) / epoll_wait),并且在 SQL 里可以观察到大量事务的 dispatch_dur(server_ts - client_ts)显著偏大——说明请求在服务端真正开始处理之前就已经卡在“等线程/等调度”上了。对于 system_server 这类关键进程,线程池被打满意味着系统服务响应能力下降,很容易放大为全局卡顿或 ANR。
Binder 事务缓冲区耗尽涉及每个进程在 Binder 驱动里的一块有限大小的共享缓冲区(典型值约 1MB 量级),用于承载正在传输的 Parcel 数据。典型场景包括一次事务传输过大的对象(如大 Bitmap、超长字符串、大数组等),以及大量并发事务尚未被消费完,导致缓冲区中堆积了太多尚未释放的 Parcel。可能的结果包括内核日志中出现 binder_transaction_alloc_buf 失败、Java 层抛出 TransactionTooLargeException,以及后续事务在驱动层长时间排队甚至失败(看起来像是“Binder 被用光了”)。解决这类问题的思路不是通过“多开线程”,而是控制单次传输的数据量(拆包、分页、流式协议),并对大块数据优先使用 SharedMemory / 文件 / ParcelFileDescriptor 等机制。
Binder 引用表 / 对象数量方面,Binder 驱动会为每个进程维护引用表和节点对象,这些也有上限,但在大多数实际场景中,很少首先撞到这里。常见风险是长时间持有大量 Binder 引用却不释放,更多体现为内存/稳定性问题,而不是 UI 卡顿。
在 Perfetto 里分析时,可以带着一个判断框架:
“现在的慢,是因为线程池被打满,还是事务过大/缓冲区被用光?”
前者主要看 **Binder 线程数与它们的 thread_state**,以及事务的 dispatch_dur(server_ts - client_ts,可近似理解为派发/排队延迟);后者则关注 单次事务的大小、并发事务数量和是否伴随 TransactionTooLargeException / binder_transaction_alloc_buf 相关日志。
现在回到我们的分析场景:
Binder 线程池的繁忙程度直接决定了服务的并发处理能力。对于同步事务来说,如果服务端 Binder 线程长期处于 Running 或 Uninterruptible Sleep (D) 状态,新的请求就会在内核里排队,客户端线程会长时间阻塞在 ioctl(BINDER_WRITE_READ) / epoll_wait,主线程在 thread_state 上通常表现为长段 S(Sleeping)。
在 Perfetto 中诊断线程池问题,优先看两个信号:Binder 线程是否长期满载,以及事务的 **dispatch_dur 是否显著大于 server_dur**(判读方式与步骤一一致)。
关于 Oneway 调用在 Perfetto 中的识别:同步调用(Two-way)和异步调用(Oneway)在 Perfetto 中的表现有明显区别,学会区分它们对分析很有帮助。同步调用时,客户端会阻塞等待(thread_state 显示 S),Perfetto 通常会画出 transaction → reply 的 Flow;而 Oneway 调用客户端发完就返回、几乎无阻塞,Flow 只有单向的 transaction,没有 reply 回来。另外,Oneway 调用的 Slice 名称后面可能会带 [oneway] 标记;在 SQL 里也可以通过 android_binder_txns.is_sync = 0 来过滤 Oneway。
在分析 Oneway 相关问题时,重点关注两件事:一是服务端的队列深度(如果同一 IBinder 对象上的 Oneway 请求堆积,后续请求的实际执行时机会被不断延后);二是是否存在批量发送的模式(短时间内大量 Oneway 调用会形成”尖峰”,在 Perfetto 中表现为服务端 Binder 线程上密集排列的短 Slice)。
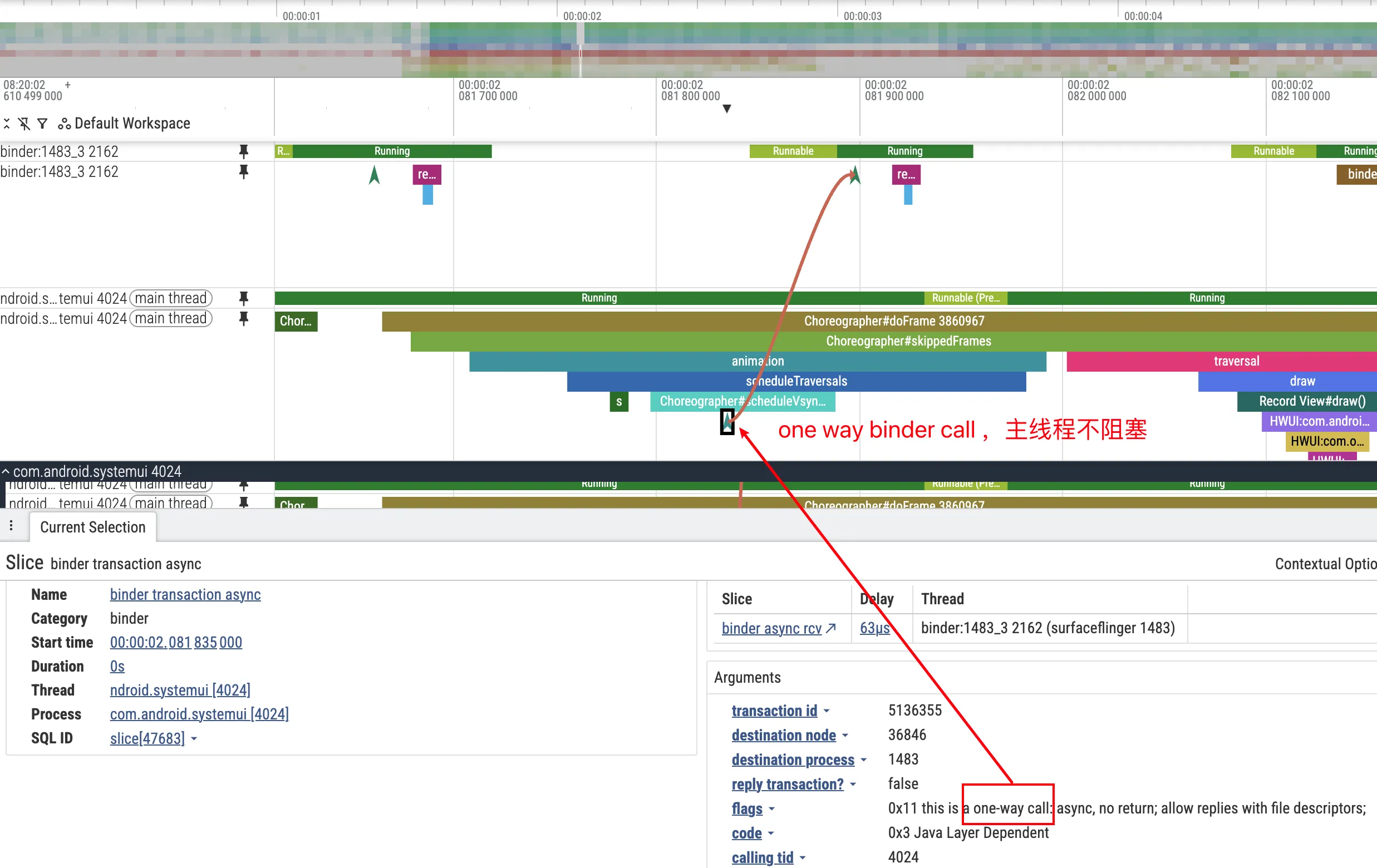
值得一提的是,SystemServer 的 Binder 线程不仅要处理来自各个 App 的请求,还要处理系统内部的调用(比如 AMS 调 WMS、WMS 调 SurfaceFlinger 等)。如果某个”行为不端”的 App 在短时间内疯狂发送 Oneway 请求,可能会把某个系统服务的 Oneway 队列塞满,进而影响到其他 App 的异步回调时延,造成全局性的卡顿感。
步骤三:排查锁竞争
如果你跳转到服务端的 Binder 线程,发现它在处理你的请求期间长时间处于 S(Sleeping)或 D(Disk Sleep / Uninterruptible Sleep)状态,那通常意味着它在等待某个资源——要么是在等锁,要么是在等 IO。锁竞争是 SystemServer 中非常常见的性能瓶颈来源,因为 SystemServer 里运行着大量服务,它们之间共享很多全局状态,而这些状态往往通过 synchronized 锁来保护。
Java 锁(Monitor Contention) 是最常见的情况。SystemServer 中有不少全局锁,比如 WindowManagerService 的 mGlobalLock、ActivityManagerService 的一些内部锁等。当多个线程同时需要访问被这些锁保护的资源时,就会产生竞争。在 Perfetto 中,如果你看到某个 Binder 线程状态为 S,并且 blocked_function 字段包含 futex 相关的符号(如 futex_wait),那基本可以确定是在等 Java 锁。要进一步确认是在等哪个锁、被谁持有,可以查看 Lock contention 轨道。Perfetto 会把锁竞争的关系可视化出来:用连接线标出 Owner(持有锁的线程,比如 android.display 线程)和 Waiter(等待锁的线程,比如处理你请求的 Binder:123_1)。点击 Contention Slice,还可以在 Details 面板里看到锁对象的类名(比如 com.android.server.wm.WindowManagerGlobalLock),这对于理解问题的根源非常有帮助。
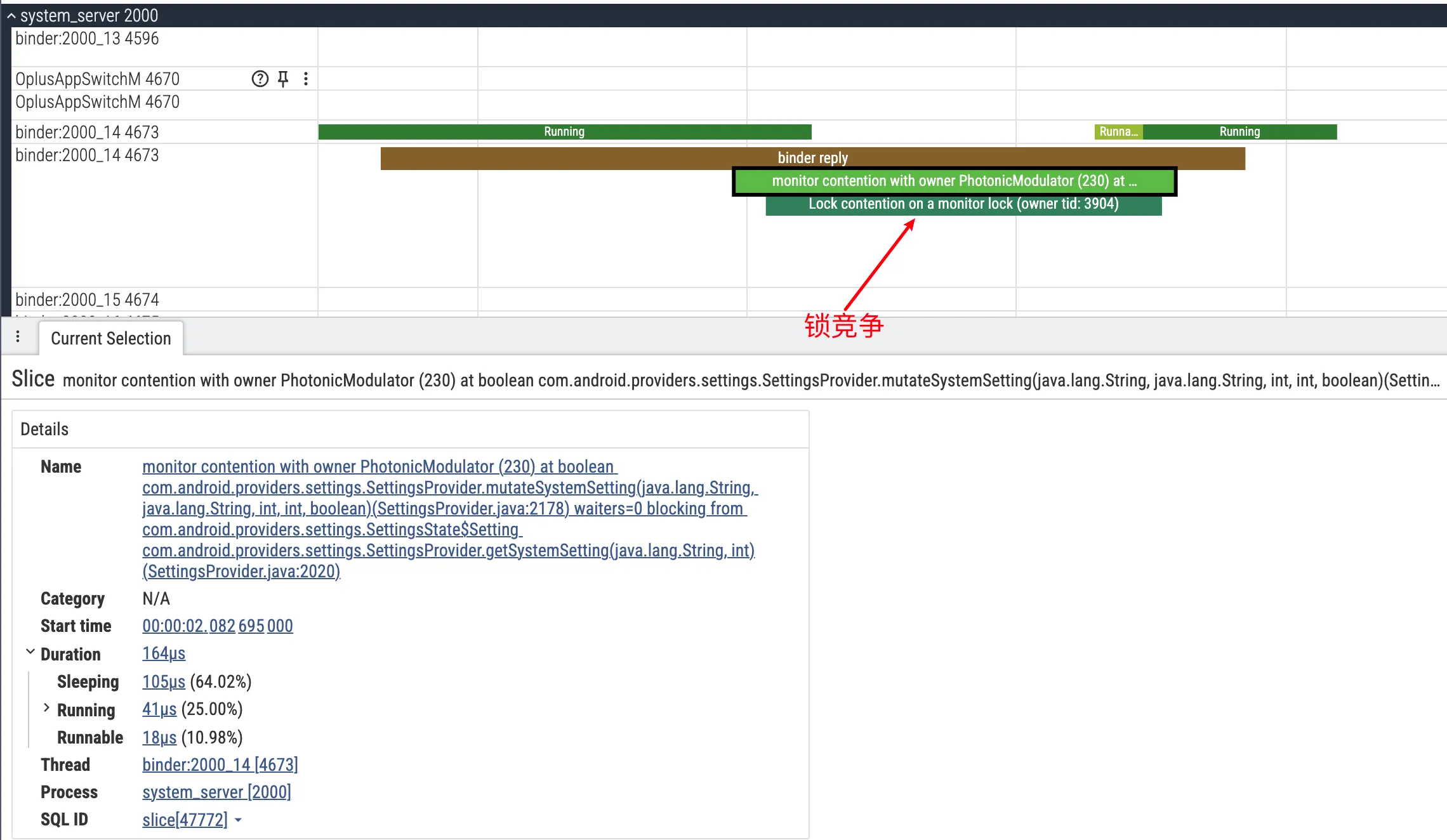
Native 锁(Mutex / RwLock) 的情况相对少见一些,但在某些场景下也会遇到。表现形式类似:线程状态为 D 或 S,但调用栈里出现的是 __mutex_lock、pthread_mutex_lock、rwsem 等 Native 层的符号,而不是 Java 的 futex_wait。分析这类问题通常需要结合 sched_blocked_reason 事件来看线程具体在等什么,属于比较进阶的内容,这里就不展开了。
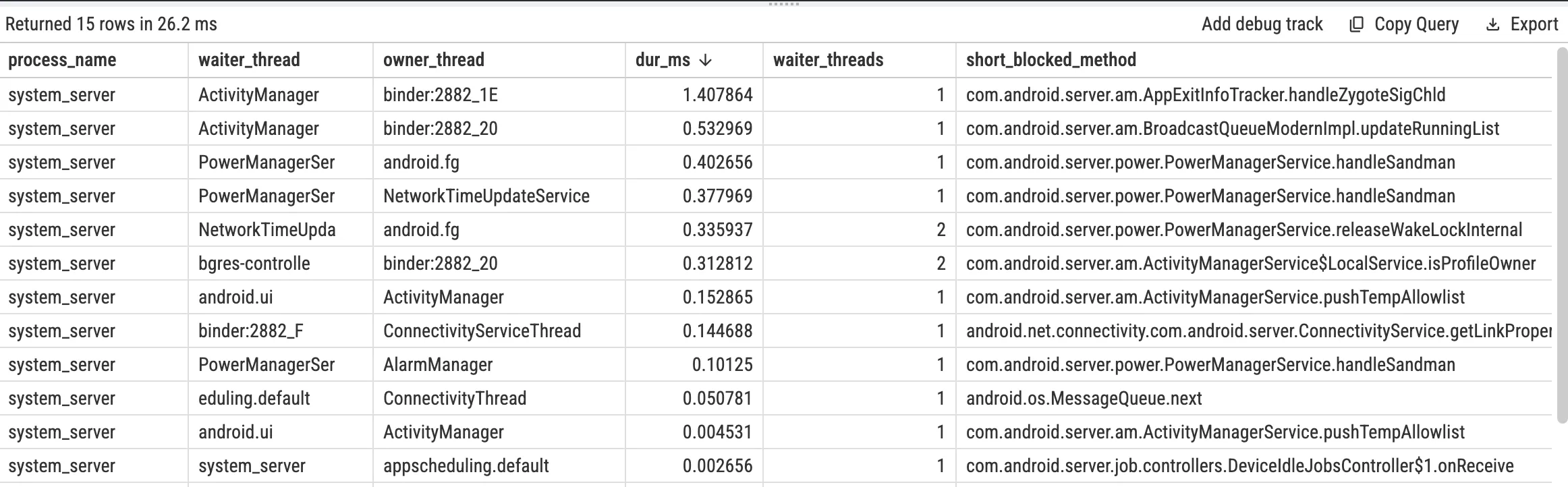
使用 SQL 统计 system_server 中的 Java Monitor Contention(可选)
PerfettoSQL 标准库已经提供了解析后的 android_monitor_contention 表(由 ART 的 monitor contention 相关 Slice 解析而来),建议优先使用它来做统计,而不是手工解析 slice 名称字符串:
1 | INCLUDE PERFETTO MODULE android.monitor_contention; |
提示:如果查不到数据,请确认抓取时
atrace_categories包含dalvik,并且问题场景中确实发生了 monitor contention。
最新平台特性与优化建议
随着 Android 版本演进,Binder 在性能与稳定性上也持续增强。理解这些机制有助于解释 Perfetto 现象并指导优化。
Binder Freeze(Android 12+):Cached 进程被冻结后几乎不获得 CPU。对其发起同步 Binder 调用会被拒绝,并可能触发目标进程终止;异步(oneway)事务通常先缓冲,待解冻后处理。
Frozen-callee 回调策略(Android 14+ 常见):可用 RemoteCallbackList 的 policy(DROP、ENQUEUE_MOST_RECENT、ENQUEUE_ALL)控制冻结期间回调堆积,降低解冻后的抖动与压力。
Binder Heavy Hitter Watcher:用于识别短时间内占比异常高的 Binder 调用热点。启用方式、阈值和输出渠道依版本与设备配置而定。
给开发者的一些建议:
关于 Oneway:只在确实不需要返回值和完成时机时使用(如日志、状态通知)。把同步调用硬改成 Oneway 往往只会把等待转移到服务端队列,并引入时序问题。
关于 大数据传输:避免直接走 Binder(尤其是 Bitmap)。单进程 Binder 缓冲区约 1MB,容易触发 TransactionTooLargeException;应改用 SharedMemory、文件或 ParcelFileDescriptor。
关于 主线程调用:不要在 UI 线程调用耗时不可控的 Binder 服务;若必须调用,请放到后台线程,完成后再回主线程更新 UI。
总结
Perfetto 是分析 Binder 问题的高效工具。核心方法是:用 linux.ftrace 抓取 binder/sched/dalvik 信号,在 UI 中沿 Flow 串联 Client 与 Server,再结合 client_dur / server_dur / dispatch_dur、线程状态和锁竞争,区分“排队慢”“处理慢”“等锁”。
遇到难解释的 UI 卡顿或 ANR 时,可按“主线程是否在等 Binder → 服务端是否排队/处理慢/等锁”的顺序排查。再结合 CPU、调度、渲染等信号,通常能更快定位根因。
参考
- 理解Android Binder机制1/3:驱动篇
- PerfettoSQL stdlib - android.binder
- Perfetto Documentation - Ftrace
- Android Source - Binder
- Android Developers - Parcel and Bundle
- binder-trace - Wireshark for Binder
- am trace-ipc 源码分析
*
关于我 && 博客
一个人可以走的更快 , 一群人可以走的更远