这篇文章记录了 SmartPerfetto 从零到可用过程中的关键技术决策——为什么选这个方案而不是那个,哪些地方踩了坑,踩完之后怎么调整的。
为什么做这个工具
我做了多年 Android 性能优化。日常工作中大量时间花在 Perfetto trace 分析上——Perfetto 是 Google 开源的系统级 trace 工具,采集帧渲染、线程调度、CPU 频率、Binder 通信等数据,几乎是 Android 性能分析的标准工具。它的 trace_processor 引擎把 trace 加载到一个嵌入式 SQLite 数据库中,支持用 SQL 查询。
分析 trace 的过程是高度重复的:找到问题区间、查帧数据、看线程状态、追阻塞链、关联系统指标。每次做的事情类似,但每个 trace 的细节不同。这种「流程固定、细节变化」的工作特点很适合 AI Agent 来处理——把固定流程中的数据收集和初步归因自动化,人来做最后的判断和确认。
SmartPerfetto 就是这个尝试的产物。它在 Perfetto UI 上加了一个 AI 分析面板,用户用自然语言提问(如「分析滑动性能」),背后由 Claude Agent 通过 MCP(Model Context Protocol,Anthropic 提出的工具调用协议)调用 trace_processor 执行 SQL,自主完成多轮数据收集和分析。
写这篇文章的目的,是把构建过程中的工程决策和教训记录下来。从最初的「直接调 API」到现在的最多 20 个 MCP 工具(9 常驻 + 11 条件注入)+ 164 个 YAML Skill + 三层验证体系,中间的每个设计选择都有具体的反例在推动——试过不行才换的方案。这些踩坑记录对做 AI Agent 应用或者做 Android 性能工具的工程师可以直接借鉴。
开篇:同一个 Trace,两条分析路径
一个滑动 trace,120Hz 设备,用户反馈列表滑动偶尔卡顿。打开 Perfetto 看到惯性滑动阶段有 18 帧掉帧,其中 3 帧 Full 级(~60ms,120Hz 设备的单帧预算是 8.33ms)。
掉帧(Jank): Perfetto 的 frame_timeline track 记录每帧渲染耗时。超过 VSync 周期(120Hz 下为 8.33ms)用户会感知卡顿。
jank_type字段区分掉帧类型:App 侧超时、SurfaceFlinger 合成延迟、Buffer Stuffing(BufferQueue 队列背压)等。
路径 A:手动分析
1 | 1. 打开 Perfetto UI,拖动时间轴找到滑动区间 |
thread_state 记录线程的调度状态(Running / Runnable / Sleeping / Uninterruptible Sleep 等)。不同状态指向不同的排查方向——Runnable 通常提示 CPU 调度层面的问题,Sleeping 通常提示等待/阻塞层面的问题。
waker_utid字段记录了唤醒线程的源线程 ID,可以辅助追踪跨进程的阻塞链。
第 3-4 步是主要工作量——18 帧掉帧,每帧都需要展开 thread_state、追踪阻塞原因、关联 CPU 调度。分析过程是逐帧串行的:每帧的下钻路径可能不同(Binder? 锁? GC? IO?),全部看完再汇总。
路径 B:SmartPerfetto Agent
用户输入 "分析滑动性能",以下是 Agent 实际执行的操作(来自 session log session_agent-1774679540422):
1 | classifyScene("分析滑动性能") → scrolling (<1ms, 关键词匹配) |
Metrics 快照 (来自 logs/metrics/):16 次工具调用,0 次失败,SQL 平均 652ms。
下图展示了一次完整分析的请求生命周期——从用户输入到最终结论的每一步:
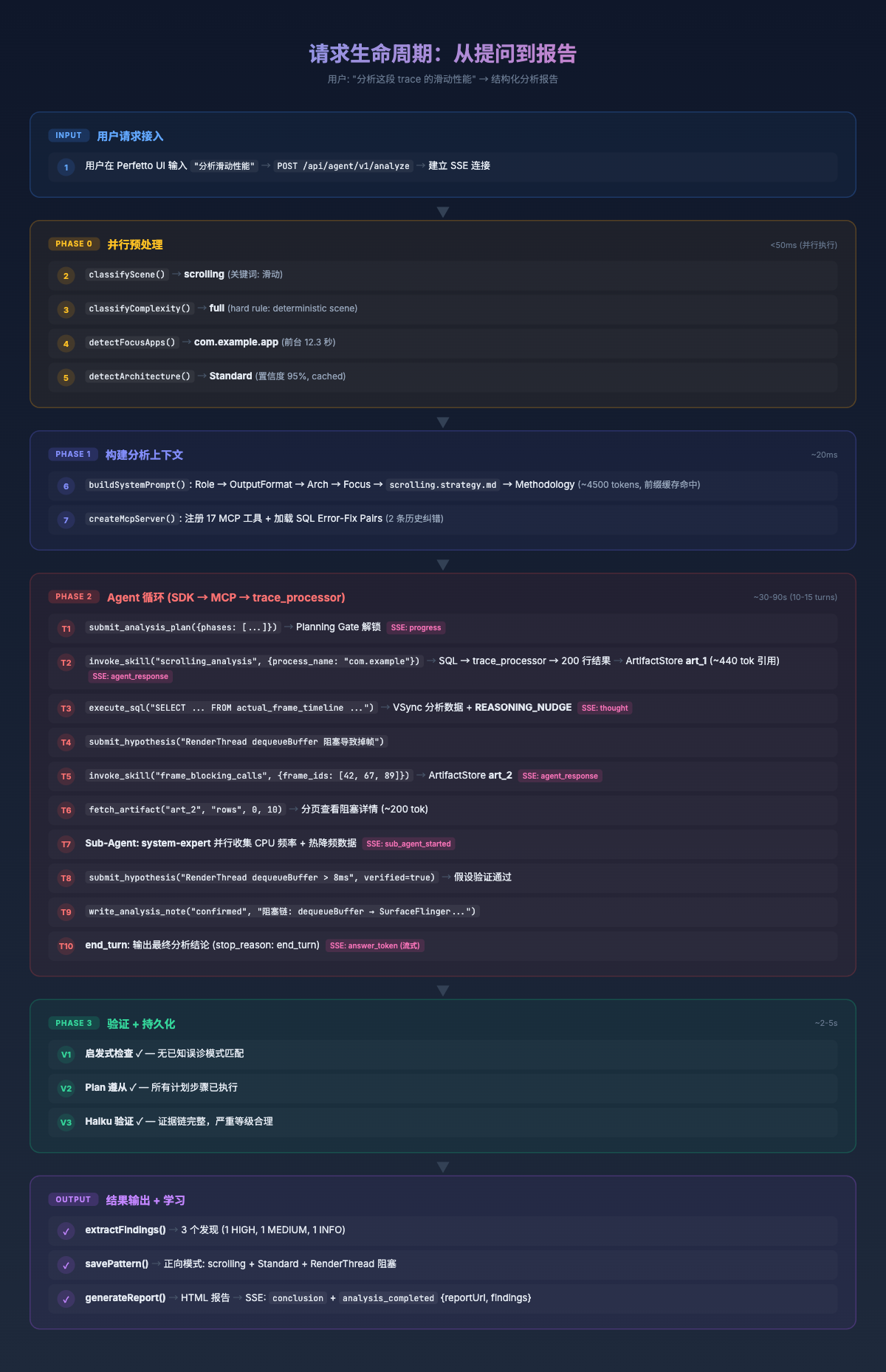
两条路径的分析步骤相同——查帧数据 → 定位 jank → 追踪阻塞链 → 关联系统状态 → 归纳结论。
差异在于:手动分析逐帧串行,每帧需要手动展开和追踪;Agent 通过 scrolling_analysis Skill 用一条 SQL 批量获取全部 18 帧的结构化数据,再选代表帧深钻阻塞链。
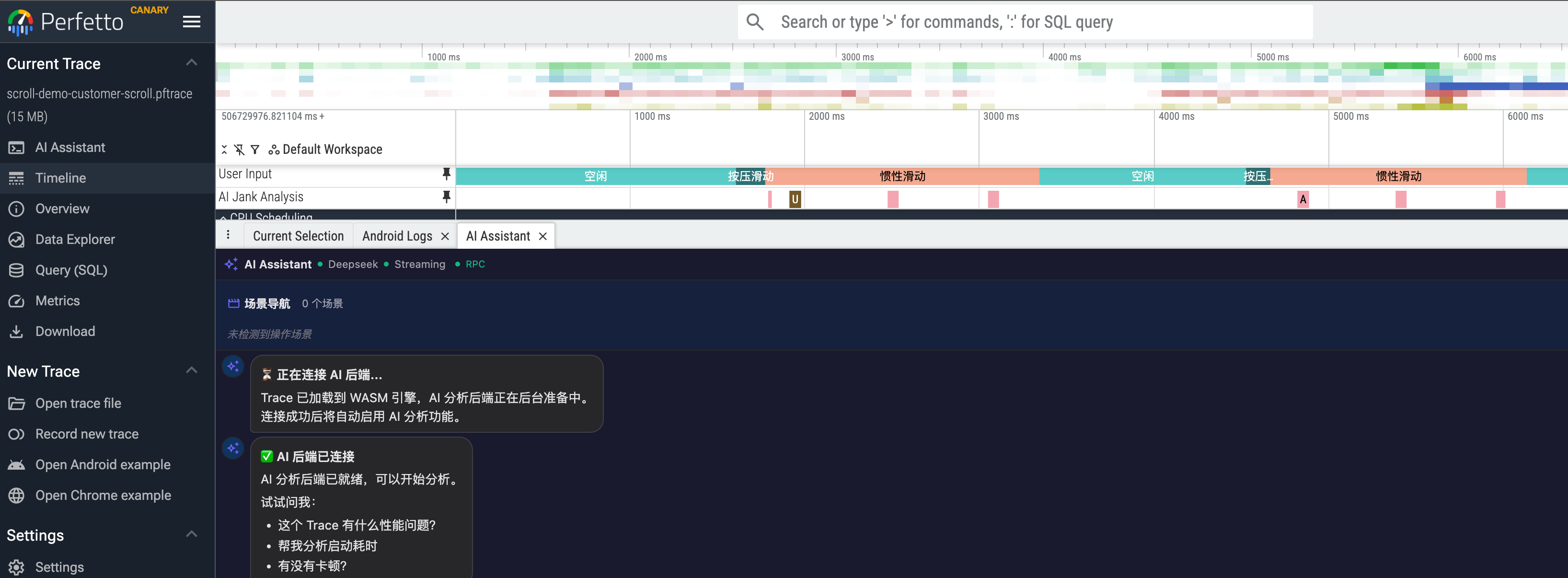
Agent 的分析结果同时落地到 Perfetto UI 上:
- Auto-Pin:Agent 提到的关键帧和 Slice 自动标记在时间线上
- 点击跳转:结论中的时间戳和帧 ID 支持点击跳转到 Perfetto 对应位置
- 数据表格:18 帧的完整性能数据以结构化格式渲染为可排序、可筛选的表格
运行截图:以 SmartPerfetto 前端以 Perfetto 插件的形式存在
运行截图:滑动分析的时候详细分析每一个掉帧的地方, 点击最左边那个剪头可以展开
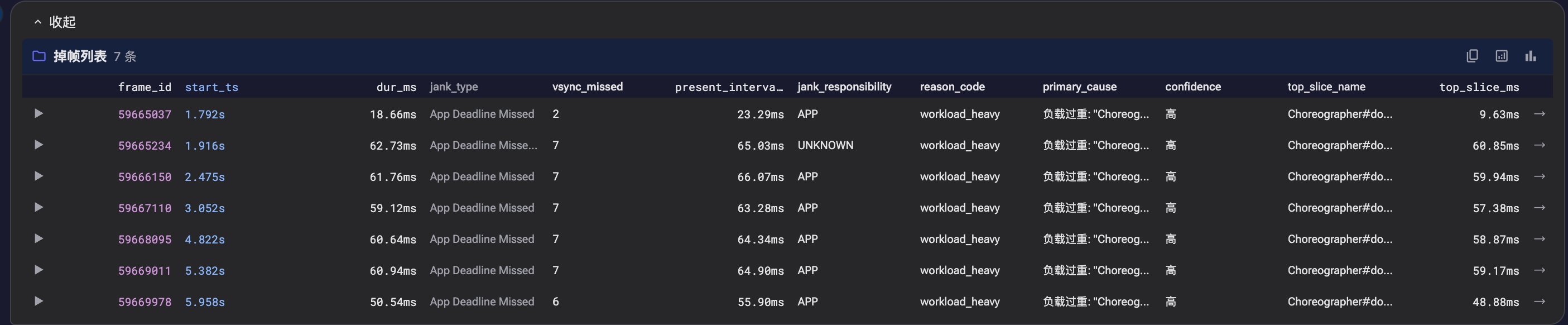
运行截图:滑动分析结论
运行截图:滑动分析结论,代表帧分析
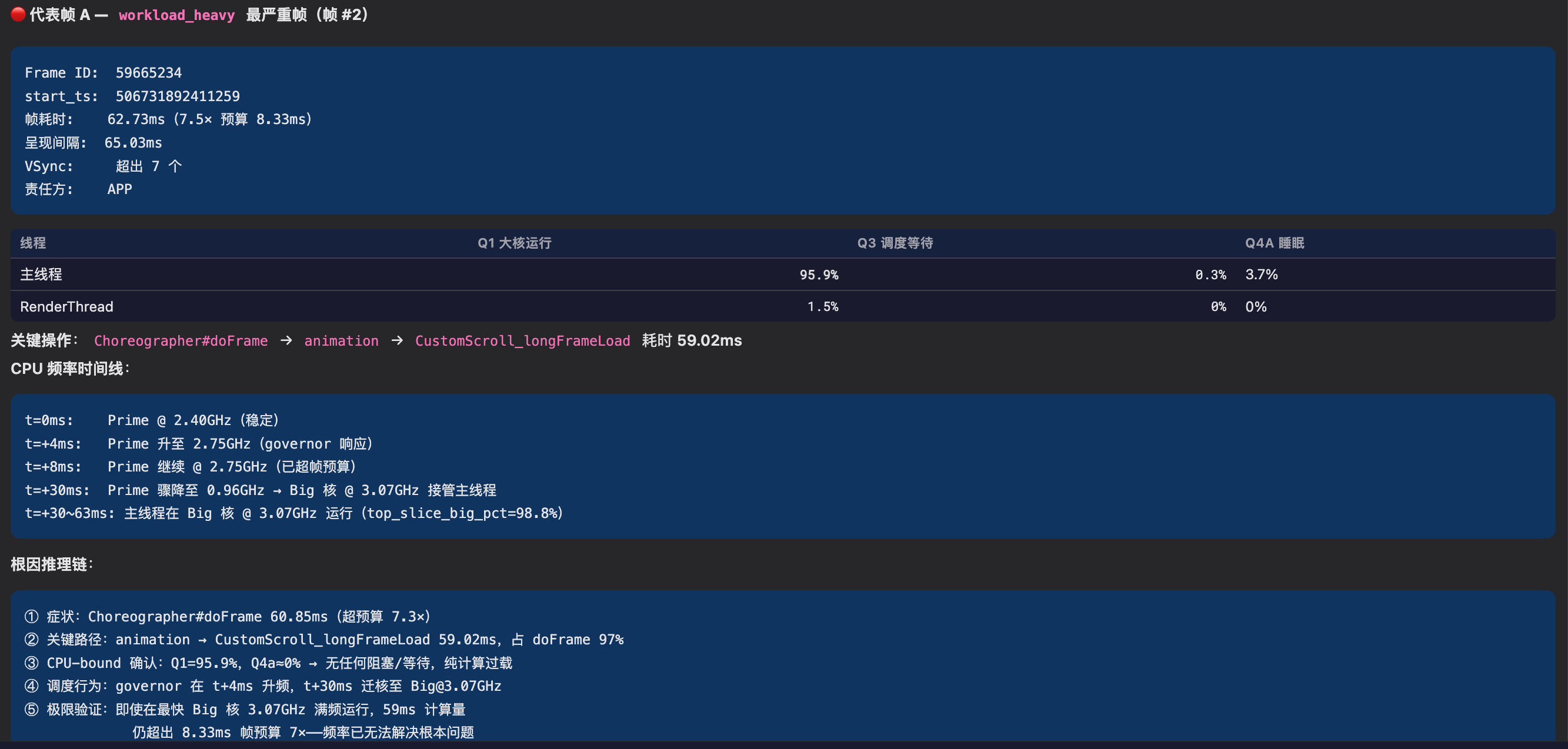
运行截图:滑动分析结论,代表帧分析
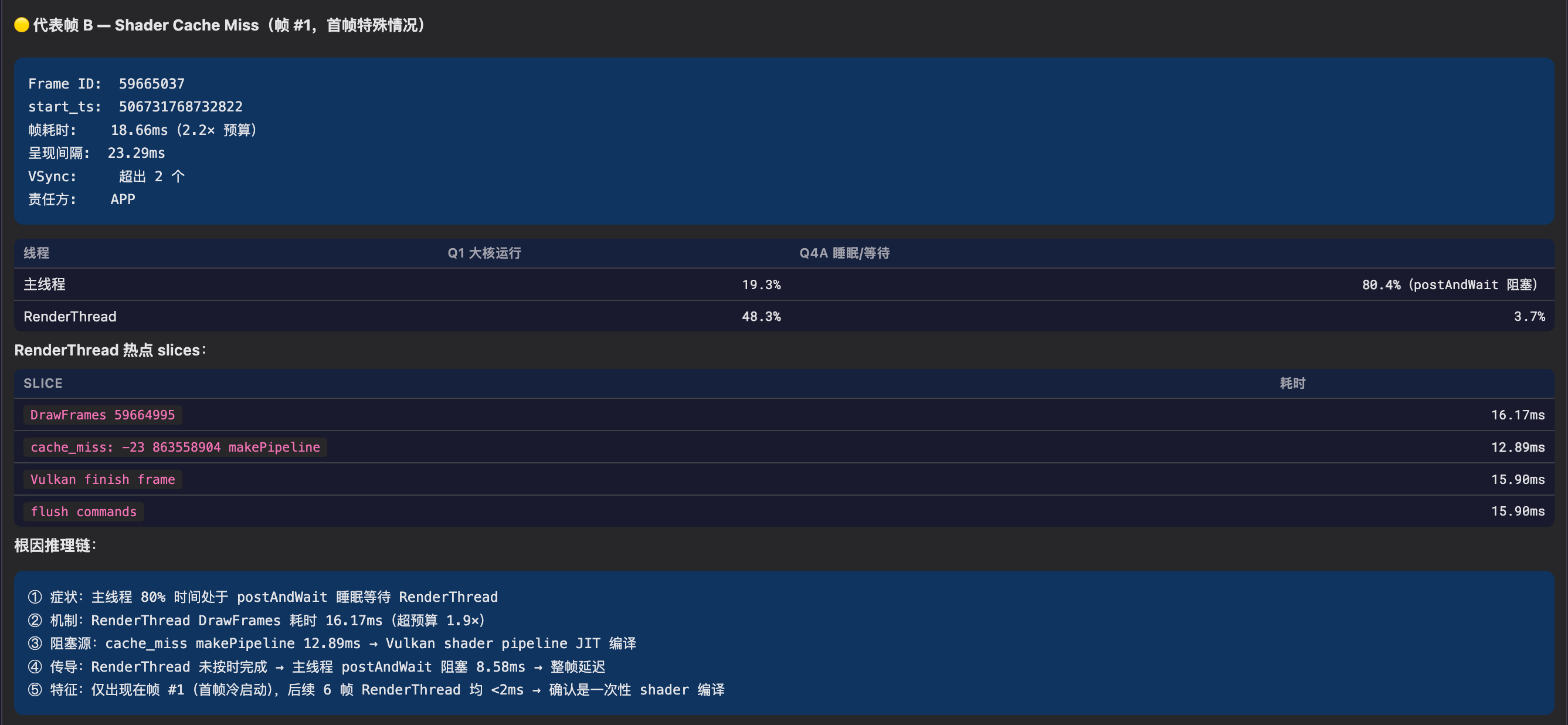
运行截图:每一轮分析都有单独的分析 report,内容与前端显示的一致(更详细一些)
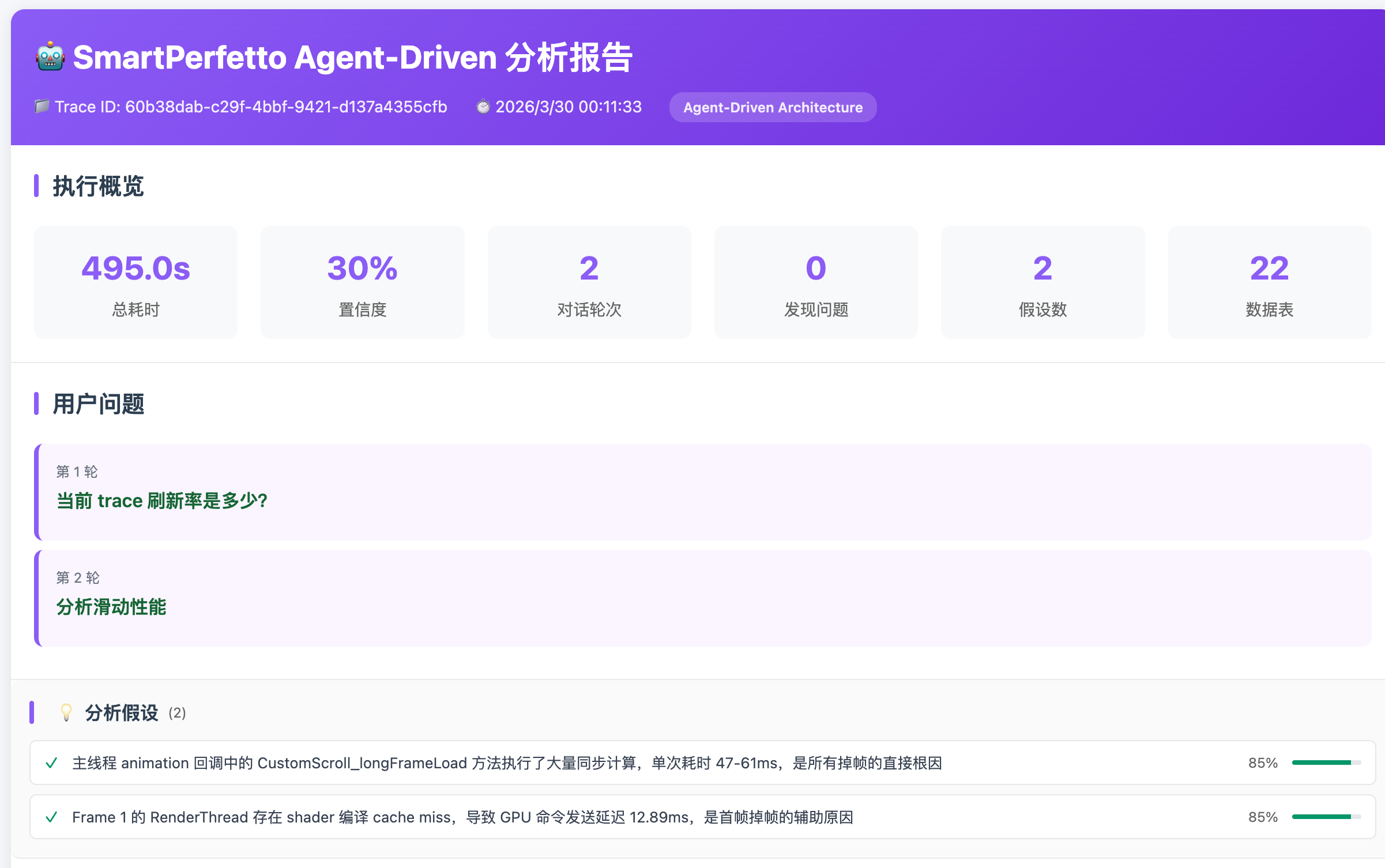
分析结论、数据表格和 Perfetto 时间线在同一个界面上。Agent 完成批量数据收集和初步归因后,工程师在 Perfetto UI 上确认关键发现。
需要说明的是,当前 Agent 在复杂边界情况下仍然需要人的判断(后文会具体讨论误诊问题)。这篇文章记录的是构建这个 Agent 背后的工程决策过程。
第一部分:为什么 LLM 不能直接分析 Trace?
在开始讨论架构之前,需要先回答一个根本问题:为什么不能直接把 trace 数据发给 LLM 让它分析?这个问题的答案决定了 SmartPerfetto 整个架构的出发点。
数据规模:trace 文件装不进上下文
一个实际的 Perfetto trace 的数据规模是这样的:
| 维度 | 典型值 |
|---|---|
| Trace 文件大小 | 50MB - 500MB |
| 事件数量 | 百万 ~ 千万级 |
| 序列化为文本后 | 数 GB |
| Claude 最大 context | ~200K tokens(约 150KB 文本) |
两者差了好几个数量级。即使是一个较小的 50MB trace,里面的 slice(函数调用记录)、counter(CPU 频率采样点)、thread_state(线程调度状态)等数据序列化后也远超 LLM 的上下文容量。
这就意味着 LLM 不可能直接「看到」trace 数据。它必须通过工具按需查询——先用 SQL 找到需要的数据子集(比如某个时间范围内某个线程的状态分布),拿到查询结果后再做分析。这个约束从根本上决定了 SmartPerfetto 必须是一个 工具驱动 的 Agent 架构,而不是把数据喂进 prompt 的简单方案。
精确计算:LLM 不擅长处理数值
性能分析的日常工作围绕精确数值展开:帧耗时的 P50 / P90 / P99 分位数、VSync 周期检测(需要对 VSYNC-sf 间隔取中位数并吸附到标准刷新率)、CPU 利用率的百分比计算、各线程状态的时间占比。
LLM 处理这类数值计算时经常出错。一个实际例子:早期测试中,Claude 把 16.7ms 的帧耗时判断为「正常,未超过 VSync 周期」——它按 60Hz(16.67ms)的帧预算来算了。但这个 trace 采集自一台 120Hz 设备,单帧预算应该是 8.33ms,16.7ms 实际上超预算了一倍。这类错误看起来很小,但在性能分析中会导致完全相反的结论。
数值计算必须由工具完成——SQL 的 AVG()、PERCENTILE() 和 YAML Skill 中预定义的统计逻辑,保证每次计算结果一致且精确。
领域知识:LLM 知道但不会用
Android 的渲染管线复杂度是很多开发者没有预期到的。最常见的三种渲染路径是:标准 HWUI 管线(HWUI 是 Android 默认的硬件加速渲染引擎,应用的 View 绘制指令在主线程生成,由 RenderThread 提交给 GPU,最终经 SurfaceFlinger 合成到屏幕)、Flutter 的双线程模型(1.ui → 1.raster,不走 RenderThread)、以及 WebView 的 Chromium 管线(CrRendererMain 线程负责渲染)。除此之外还有 Jetpack Compose、游戏引擎、相机管线等。SmartPerfetto 的架构检测系统目前识别 24+ 种渲染管线,不同管线的 jank 分析需要查看不同的线程和指标——这也是为什么架构检测是分析的第一步。
卡顿的根因可能跨线程(主线程阻塞 → 原因在 RenderThread)、跨进程(App 等待 → system_server 的 WindowManagerService 响应慢)、甚至跨硬件层(CPU 调度到小核 → 算力不足 → 帧超时)。
LLM 的训练数据中包含这些概念——它「知道」什么是 RenderThread,什么是 Binder,什么是 SurfaceFlinger。但面对一个具体的 trace,它缺乏将这些知识按场景分阶段运用的能力。比如分析滑动卡顿时,需要先检查帧级数据(哪些帧掉了、掉帧类型是什么),再针对占比最高的根因类型选择不同的深钻路径(App 侧阻塞走 blocking_chain_analysis,合成端延迟走 SurfaceFlinger 分析)。这种分步骤、有条件分支的分析流程,需要通过策略注入来引导。
可靠性:错误率在实际运行中偏高
即使解决了数据访问问题,直接让 LLM 产出性能分析结论仍然面临可靠性问题。在 SmartPerfetto 的实际运行中,我观察到几类典型的输出问题:
- 幻觉:生成 trace 中不存在的数据或指标
- 遗漏:漏掉关键检查项(比如分析启动性能时不检查 JIT 编译和类加载的影响)
- 浅层归因:停在「主线程忙」的层面,不继续追踪是忙在 futex(锁竞争)、binder_wait(跨进程等待)还是 GC pause
- 结论不一致:同一份 trace 分析两次,得到不同的严重等级判定
后文第二部分会详细讨论这个问题——agentv3 上线 18 天后的质量审查显示,约 30% 的 Agent 结论包含不同程度的误判。
SmartPerfetto 的分工设计
基于这四个问题,SmartPerfetto 的架构按以下方式分工:
1 | LLM (Claude) 负责: 工具系统负责: |
LLM 做推理和表达,工具做查询和计算。连接两者的是 MCP(Model Context Protocol,Anthropic 提出的工具调用协议)——Claude 通过标准 MCP 接口调用 trace_processor 执行 SQL、调用 YAML Skill 做结构化分析、查询 Perfetto stdlib 模块。分析结果通过 SSE(Server-Sent Events)实时推送到 Perfetto UI 前端。
支撑这个分工的工程基础设施包括:场景路由(根据用户问题注入不同的分析策略)、数据压缩(控制返回给 LLM 的数据量)、质量验证(拦截 LLM 的领域误判)。后面几个部分展开讨论每个部分的设计过程。
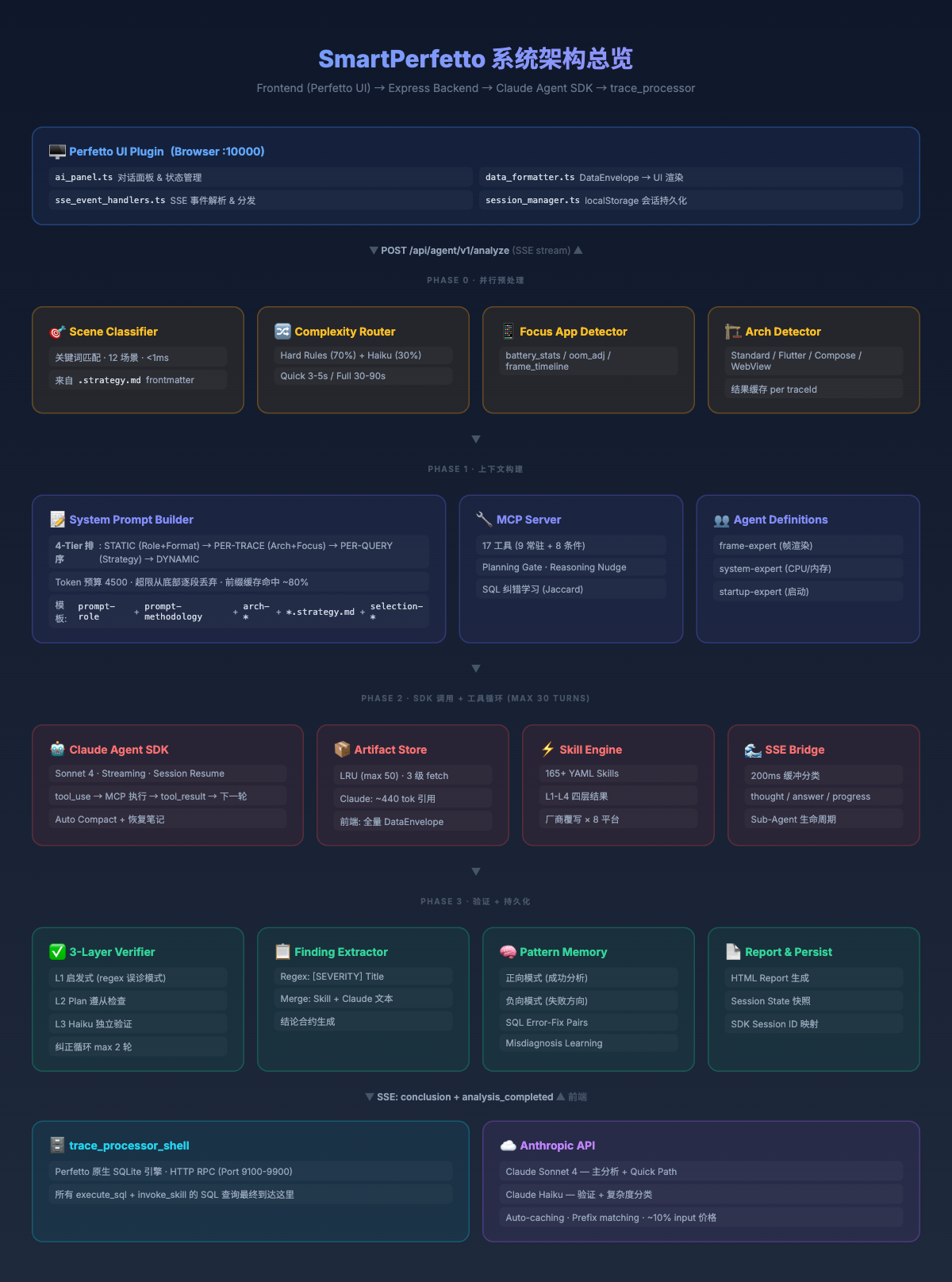
下图是完整的系统架构,展示了从用户请求到分析结论的 4 个阶段:
第二部分:从 Workflow 到 Agent
Workflow 和 Agent 的区别
Anthropic 在 2024 年 12 月发表的《Building Effective Agents》(作者 Erik Schluntz、Barry Zhang)中,将 AI 系统分为两类:
- Workflow(工作流):LLM 和工具通过预定义的代码路径进行编排。每一步做什么、下一步走哪里,都由开发者事先定义好。
- Agent(智能体):LLM 动态主导自身流程和工具使用,自主决定如何完成任务。
这个区分的实际意义在于灵活性和可控性的权衡。Workflow 提供可预测性,适合步骤固定的任务;Agent 提供灵活性,适合需要根据中间数据调整方向的开放式问题。Andrew Ng 的描述很准确:不需要二元地判断一个系统是不是 Agent,而是把它看作不同程度的 Agent 化。SmartPerfetto 的 agentv2 和 agentv3 分别对应这个光谱的两端。
为什么性能分析需要 Agent 而不是 Pipeline
性能分析不是一个「给输入得输出」的固定流程,它是一个探索性的推理过程。以一个实际的滑动分析为例:
1 | 1. 先看总览 → 发现 47 帧卡顿,P90 = 23.5ms |
每一步决策都依赖前一步的结果——无法在分析开始前就确定所有步骤。Pipeline 无法处理「这个 trace 的问题可能在 GPU,也可能在 GC,需要根据中间数据动态选择下钻方向」这种需求。
SmartPerfetto 的设计是确定性和灵活性的混合:已知场景(滑动、启动、ANR 等)用 Strategy 文件约束必检项,保证不遗漏;但每个阶段内的具体查询和深钻方向由 Claude 自主决定。未匹配的场景则完全交给 Claude 自主探索。
agentv2:一个典型的 Workflow
agentv2 使用 DeepSeek 作为后端,采用 Governance Pipeline 架构——通过 planner / executor / synthesizer 三阶段编排,本质上是预定义的多步骤工作流(历史 commit 6d80aefb: “Replace the 13-step agentv2 governance pipeline with Claude-as-orchestrator”)。
这个架构在标准 Android 应用的滑动分析上工作得不错,但遇到非标准情况就出问题了。比如 Flutter 应用的 trace 里没有标准的 frame_timeline 数据,管线拿到空结果后继续执行后续步骤,最终输出基于空数据的结论。
agentv3:迁移到 Agent 架构
2026 年 3 月 2 日(commit 6d80aefb),我切换到 Claude Agent SDK。Claude 接收工具定义和策略后,自主决定调用什么工具、按什么顺序、查什么数据。
一个 AI Agent 通常具备以下特征,agentv3 的实现对照如下:
| 特征 | SmartPerfetto 中的实现 | 代码位置 |
|---|---|---|
| 自主性 | Agent 自主决定调用哪个工具、按什么顺序 | claudeRuntime.ts |
| 推理能力 | 每次工具调用后追加 REASONING_NUDGE 触发显式反思 | claudeMcpServer.ts:84 |
| 工具使用 | 最多 20 个 MCP 工具调用 trace_processor | 9 常驻 + 11 条件 |
| 规划能力 | submit_plan + requirePlan() 门控 | 轻量模式关闭 |
| 反思能力 | 3 层 Verifier + Correction Prompt (max 2 轮) | claudeVerifier.ts |
| 错误恢复 | SQL 纠错学习 + 跨会话误判模式学习 | 跨文件 |
| 记忆 | 短期: Analysis Notes / Artifact Store;长期: Pattern Memory / SQL Fix Pairs | 7 层记忆 |
1 | agentv2 (Workflow): 固定管线 → 每步预定义 → 意外数据 = 错误结论 |
迁移后的 9 轮审查
从 3 月 2 日到 3 月 20 日,经历了 9 轮架构审查。其中影响最大的几轮:
| 轮次 | 日期 | 主要发现 |
|---|---|---|
| Round 1 | 3/2 | 初始 SDK 集成后 12 个修复——SQL 知识库没接入 System Prompt,jank_frame_detail 中 CPU 核数硬编码为 4 |
| Round 3 | 3/12 | 架构接线审计——12 处「实现了但没接上」的断连,比如验证管线在 0 findings 时被跳过 |
| Round 7 | 3/15 | Perfetto Stdlib 集成——预加载模块 4→22,Schema Index 708→761 |
| Round 9 | 3/20 | 18 天真实 trace 后的生产质量审查——3 P0 + 4 P1 + 5 P2,催生了三层验证系统 |
冷启动 4 层联动 Bug
2026 年 3 月 19 日(commit d5a1d7b3),发现冷启动被错误分类为热启动。追踪后发现这是一个跨 4 层的联动问题:
1 | Layer A (Perfetto Stdlib): bindApplication 的 ts 比 launchingActivity 早 ~98ms → 被过滤器排除 |
修复规模:重写 10 个下游 Skill,新增 4 个启动分析 Skill。这个问题说明在 Skill 依赖链中,上游的一个字段语义错误会逐层放大。
Ghost MCP Query — 异步生命周期错配
2026 年 4 月 7 日(commit a0ad63ba)抓到的另一类跨层 Bug:分析超时之后,session 已经清理、SSE 流已经收尾,但 trace_processor 的 stderr 仍然在 90 秒后陆续吐出 no such table: cpu_frequency_counters / no such column: ts 这类错误——孤儿日志,没有 owner 可以归因到任何 session,前面错误 4 的两条纠错对就是从这堆 stderr 里反查出来的。
根因在 SDK Query 的异步生命周期:
1 | Layer A (Claude Agent SDK): SDK 内部的 AsyncIterator 还在生产 message |
AsyncGenerator.return() 和 break 只对消费侧生效,不会反向通知生产侧的外部资源(SDK 子进程 + MCP 工具执行队列)。修法是把 sdkQueryWithRetry 的返回类型从单个 AsyncIterable 改成 { stream, close } 二元组,timeout / 异常 / finally 三个路径都显式调一次 close(),让 SDK 主动 abort 子进程:
1 | // claudeRuntime.ts |
这个 Bug 之所以隐蔽,是因为表面症状(孤儿 SQL 错误日志)和真实根因(异步资源生命周期错配)相隔很远——错误信息长得像「Agent 写错 SQL」,但其实是「Agent 早就停了,是 SDK 子进程没停」。在 Agent 应用中,”break 一个循环” 经常没有想象中那么干净;任何长生命周期的异步资源都需要显式的 close 通道,而不是依赖 for-await 的自动析构。
第三部分:三个关键的工程决策
决策 1:Scene Classification — 从全量注入到按需加载
一开始我把 12 个场景(scrolling / startup / ANR / interaction / pipeline / game / memory 等)的分析策略全部塞进 System Prompt,总计 15000+ tokens。逻辑是:Claude 应该知道所有场景的分析方法,这样不管用户问什么都能应对。
实际运行后发现 Claude 会混淆不同场景的术语——在分析滑动时引用了启动阶段的指标,把 VSync 间隔(帧间时序)和 bindApplication(进程初始化)搞混。根本原因是不同场景的术语存在大量重叠,「帧」在滑动场景里是渲染帧,在启动场景里是首帧显示,12 套策略同时出现时 LLM 无法区分上下文。
解决方式是做场景分类,每次只注入一套策略:
1 | // sceneClassifier.ts — 12 场景, <1ms 执行 |
关键词和优先级声明在每个 .strategy.md 的 YAML frontmatter 中,不硬编码在代码里:
1 | # scrolling.strategy.md |
添加新场景只需新建一个 .strategy.md 文件。DEV 模式下支持热加载,修改后刷新浏览器即可生效。
调整之后 System Prompt 从 ~15000 tokens 降到 ~4500 tokens,策略混淆的问题没有再出现。新增场景也从改代码变成了新建一个 .md 文件。
当多轮对话积累了较多上下文(分析笔记、历史计划、模式记忆等),System Prompt 可能重新超过 4500 token 预算。这时按优先级逐个丢弃低价值段落:SQL 知识库参考(Claude 可以用 lookup_sql_schema 工具按需查询)→ 历史分析经验 → 历史踩坑记录 → SQL 纠错对 → 子代理协作指引 → 历史分析计划。核心段落(角色、方法论、场景策略、输出格式)不会被丢弃。
决策 2:Artifact Store — 控制返回给 LLM 的数据量
决策 1 解决了 System Prompt 的膨胀问题。但即使场景策略只注入了一套,Agent 在执行过程中每次调用 Skill 仍然会产生大量数据(200+ 行帧数据),这些数据全部放进上下文带来新的问题。
早期版本把 Skill 执行结果(比如 200 行帧数据、487 行阻塞分析)完整返回给 Claude。每个 Skill 结果约 3000 tokens,一次分析调用 5-8 个 Skill,仅 Skill 数据就占 15000-24000 tokens。
token 成本是一方面,更意外的发现是:数据越多,Claude 的输出质量反而越差。面对 200 行帧数据时,它倾向于逐行描述(「帧 1 耗时 12.3ms,帧 2 耗时 15.7ms…」)而不是做模式归纳。我猜测原因是上下文中充斥大量数字后,LLM 的注意力被分散了。
解决方式是把 Skill 结果存入 ArtifactStore,返回给 Claude 的只有紧凑引用(~440 tokens)——行数、列名和摘要信息。需要详情时,Claude 通过 fetch_artifact 按需分页获取。完整数据通过独立的 SSE(Server-Sent Events)通道发送给前端渲染,不经过 LLM。
1 | invoke_skill("scrolling_analysis") 执行结果: |
fetch_artifact 的三个粒度:
| 级别 | 返回内容 | 约 tokens |
|---|---|---|
summary |
行数 + 列名 + 首行样本 | ~50 |
rows |
分页数据 (offset/limit) | ~200-500 |
full |
完整原始数据 | ~3000 |
调整后每个 Skill 的 token 成本从 ~3000 降到 ~440,8 个 Skill 从 ~24000 降到 ~3520 tokens。Claude 的输出从逐行描述变成了模式归纳,前端仍然能拿到完整数据做表格渲染。
决策 3:三层验证 — 从真实误判中学到的
agentv3 上线 18 天后,我做了一次系统性的质量审查(2026 年 3 月 20 日,commit da63eaf9)。统计结果让我意外:约 30% 的 Agent 结论包含不同程度的误判。
以下是实际遇到的误判案例:
1 | [案例 1] Agent 将 VSync 对齐偏移标记为 CRITICAL |
这些误判有一个共同特点:它们不是逻辑错误,而是 领域经验的缺失。高刷设备上 VSync 微小偏移是正常的、Buffer Stuffing 的延迟发生在管线队列层面而非 App 逻辑、单帧异常不构成模式——这些判断依赖对 Android 图形栈的深入理解,Claude 的训练数据对这些细节覆盖不足。
认识到这一点后,我建立了三层递进验证:
1 | Layer 1: 启发式检查 (无 LLM 调用) |
验证发现严重问题时,生成 Correction Prompt 让 Claude 修正结论(最多 2 轮)。
跨会话学习: 确认的误判模式被持久化到 logs/learned_misdiagnosis_patterns.json,下次分析时自动注入 System Prompt。例如系统学到了:
1 | { |
注:学习到的误判模式不会立即生效。代码中要求
occurrences >= 2才会进入有效模式集——首次记录只是标记,同一模式第二次出现时才会注入到后续分析的 System Prompt 中,避免孤立事件造成过度矫正。
第四部分:为什么不用标准的 Skill 系统?
从 SOP 到 YAML Skill 的设计选择
做性能分析的团队一般都有自己的 SOP(标准操作流程):滑动卡顿怎么查、启动慢怎么分析、ANR 怎么定位。SOP 通常是一份文档或检查清单,有经验的工程师照着做,新人跟着学。
Anthropic 的 Claude Code 有一套 Skills 系统,本质上是参数化的 Prompt 模板——注入上下文后提交给 Agent 执行。一个自然的想法是把性能分析 SOP 写成这种 Prompt 模板,让 Claude 按 SOP 执行。
我一开始也走了这条路。给 Claude 的 Prompt 是:「查询 frame_timeline 表,找出 jank 帧,分析主线程在 jank 帧期间的状态分布。」
Claude 理解意图没问题,但每次生成的 SQL 不一样。有时候 JOIN 路径写对了(slice → thread_track → thread),有时候直接写 slice.utid——这个列不存在。查出来的结果格式也不固定,有时候 3 列有时候 5 列,前端渲染没法做。
原因很简单:SOP 是给人看的,工程师看到「查 frame_timeline」知道具体该写什么 SQL。LLM 对 Perfetto 的 SQL schema 理解不完整(这些 schema 在训练数据中覆盖有限),每次从 SOP 文本到 SQL 的翻译过程都会引入方差。
SmartPerfetto 的 YAML Skill 采用了不同的思路——不是 Prompt 模板,而是声明式的 SQL 执行单元:
1 | # YAML Skill: SQL 预定义,结果格式固定 |
两种方式的核心区别在于「谁来写 SQL」。Prompt 模板让 LLM 每次动态生成 SQL,结果格式不可预测,无法做回归测试;YAML Skill 预定义了 SQL 和输出 schema,参数替换后执行,结果格式固定,可以稳定地回归测试和前端渲染。
| 维度 | Prompt 模板 (SOP 式) | YAML Skill (声明式执行) |
|---|---|---|
| SQL 来源 | LLM 每次动态生成 | YAML 预定义,参数替换 |
| 结果格式 | 每次可能不同 | 固定的列名和类型 |
| 可回归测试 | 不支持 | 6 条 trace 回归测试全通过 |
| 前端渲染 | 需要解析自由文本 | Schema-driven 表格/图表 |
| 可组合 | 不支持 | composite skill 调用 atomic skill |
| 厂商适配 | 需要写不同 Prompt | .override.yaml 覆写 SQL |
最终的分工是:Claude 负责理解意图、选择 Skill、推理归因;YAML Skill 负责精确的 SQL 查询和结构化输出。Claude 通过 invoke_skill 调用 Skill,Skill 返回结构化数据,Claude 基于数据做判断。
为什么不把每个 Skill 暴露为独立的 MCP Tool?
一个自然的问题是:为什么不直接把 87 个 atomic 分析能力注册为 87 个 MCP Tool,让 Claude 直接调用?
实际试过会发现一个问题:MCP 的 tool list 会随着工具数量线性增长。87 个工具意味着每次 API 调用都要在请求中附带 87 个工具的描述(名称、参数 schema、使用说明),这个固定开销会占据大量 token。更重要的是,当 Claude 面对 87 个工具时,它的选择准确率会下降——工具太多,它不知道该用哪个。
SmartPerfetto 的设计是 Claude 只看到 2 个和 Skill 相关的 MCP Tool:
invoke_skill(skillId, params)— 执行指定的 Skilllist_skills(category?)— 按场景类别查询可用的 Skill 列表
通过 list_skills(category="scrolling") 按需发现能力,再用 invoke_skill 调用。2 个 MCP Tool 封装了 160+ 个分析能力,工具列表的 token 开销是固定的。
另一个好处是 YAML 格式降低了贡献门槛。性能分析专家如果对某个分析场景有经验,可以直接写 YAML Skill 定义 SQL 查询和输出格式,不需要懂 TypeScript 或修改后端代码。修改后在开发模式下刷新浏览器即可生效(热加载),迭代周期在秒级。
Skill 系统的结构
Skill 数量从项目初期的十几个增长到现在的 164 个,增长的驱动力不是「尽可能多」,而是分析实践中不断遇到新的场景需要覆盖——比如最初只有标准 HWUI 的帧分析,后来遇到 Flutter 应用需要专门的 Skill,再遇到厂商差异需要 override,再遇到启动分析中 JIT、class loading、Binder pool 各自需要独立的检测逻辑。
当前的 Skill 按类型分布如下:
| 类型 | 数量 | 位置 | 说明 |
|---|---|---|---|
| Atomic | 87 | skills/atomic/ |
单一检测能力(VSync 周期、CPU 拓扑、GPU 频率、GC 事件等) |
| Composite | 29 | skills/composite/ |
多步组合分析(如 scrolling_analysis 编排多个 atomic Skill) |
| Pipeline | 28 | skills/pipelines/ |
渲染管线检测 + 教学(24+ 种 Android 渲染架构识别) |
| Module | 18 | skills/modules/ |
按模块分类的分析(app / framework / hardware / kernel) |
| Deep | 2 | skills/deep/ |
深度分析(CPU profiling、callstack 分析) |
另有 skills/vendors/ 下 8 个厂商的 .override.yaml(Pixel / Samsung / Xiaomi / Honor / OPPO / Vivo / Qualcomm / MTK),覆盖通用 Skill 中的厂商特定 SQL。
分层结果
早期 Skill 的输出是平铺的——一个 Skill 返回一张大表,200 行帧数据混在一起,用户打开就看到全量数据,没有层次感。实际使用中发现工程师的阅读习惯是:先看概要(掉帧率多少、P90 多少),再决定要不要展开看详情,再针对具体帧深钻。
现在 Skill 的输出按层级组织,前端渐进式渲染:
1 | summary — "47 帧卡顿, P90=23.5ms, SEVERE 占 12%" |
Skill 的每个 step 通过 display.level 声明自己的展示层级(实际使用最多的是 detail — 240 处、key — 170 处、summary — 81 处)。前端根据 DataEnvelope 中的列类型(timestamp、duration、percentage、bytes 等)和交互动作(navigate_timeline 跳转到 trace 位置、navigate_range 选中时间范围、copy 复制数据)自动渲染表格和图表——新增一个 Skill,前端不需要写额外的代码。这是 164 个 Skill 而前端代码量仍然可控的关键。
Step 类型
最初所有 Skill 都只有一种 step:执行一条 SQL。后来遇到需要组合多个 Skill 的场景(比如 scrolling_analysis 需要先查帧数据,再对每个 jank 帧做阻塞分析),以及需要遍历数据行的场景(逐帧诊断),逐步扩展了 step 类型:
| Step 类型 | 说明 | 使用频次 |
|---|---|---|
atomic |
单条 SQL 查询,最基础的 step 类型 | 最常用 |
skill |
引用另一个 Skill 的结果,用于组合分析中复用已有能力 | 56 处 |
iterator |
遍历数据行,对每行执行子查询 | 5 个 composite Skill 中使用 |
diagnostic |
诊断步骤,生成结构化的诊断结论 | 38 处 |
parallel |
并行执行多个 step(代码已支持,尚未在 Skill 中使用) | 0 |
conditional |
根据条件选择分支(代码已支持,尚未在 Skill 中使用) | 0 |
iterator 是逐帧分析的核心——比如对 18 个 jank 帧中最严重的 8 个,逐一执行 blocking_chain_analysis,每帧独立分析阻塞原因。parallel 和 conditional 在类型系统中已定义,目前还没有 Skill 使用——这是因为当前的分析场景用 skill 引用 + iterator 遍历已经能覆盖,后续引入更复杂的场景(如多路并行数据采集)时会用到。
领域 Skill 举例
以下几个例子说明为什么需要这么多专用 Skill——每个 Skill 背后都有一个「通用方案处理不了」的具体问题。
Consumer Jank Detection — 框架标记 ≠ 用户感知
框架的 jank_type 标记不等于用户感知的掉帧。存在 Hidden Jank——框架标记 jank_type='None' 但用户感知到卡。原因是框架的判定口径和用户的实际感知之间存在差异。
SmartPerfetto 用独立的 consumer_jank_detection Skill 做掉帧判定:通过 VSYNC-sf 间隔的中位数估算实际 VSync 周期,再用 1.5 倍 VSync 周期作为阈值,基于相邻帧的 present_ts 差值(帧实际显示到屏幕的时间戳)判断是否掉帧。不依赖框架标记。
阻塞链分析 — 跨线程、跨进程的根因追踪
一帧掉帧的根因可能涉及多层因果链:
1 | 帧 42 耗时 62ms (预算 8.33ms) |
blocking_chain_analysis Skill 用 3 步 SQL 提供这条链的关键线索:主线程状态分布(Running / Sleeping / IO 各占多少)→ 唤醒者追踪(通过 waker_utid 找到是谁唤醒了主线程)→ 阻塞函数汇总(futex / binder_wait / io_schedule 各累计多少时间)。这种跨层分析用通用 Prompt 让 Claude 自己写 SQL 很难稳定实现。
Flutter 架构分支 — 不同渲染模式需要不同分析逻辑
Flutter 的两种渲染模式涉及不同的线程,分析时需要看不同的目标:
| 模式 | Jank 分析目标线程 | 是否经过宿主 RenderThread |
|---|---|---|
| TextureView (双管线) | 1.ui + 1.raster + RenderThread | 是 |
| SurfaceView (单管线) | 1.ui + 1.raster | 否 |
如果用标准 HWUI 的分析逻辑去分析 Flutter SurfaceView 应用,会把 1.raster 线程的耗时错误归因到 RenderThread。SmartPerfetto 通过架构检测(24+ 种渲染管线)自动识别 Flutter 应用并切换到专用的 flutter_scrolling_analysis Skill。
但「自动识别 Flutter」本身也踩了坑(commit 355df8ee,4/6)。早期的 pipeline 检测器是给每种架构单独打分,分数最高的胜出——结果 Flutter TextureView 的 trace 经常被误判为 STANDARD。原因是 Flutter TextureView 的宿主侧仍然走 HWUI 管线(Choreographer#doFrame / DrawFrame / RenderThread),这些信号同时被 STANDARD 和 TEXTUREVIEW 两个分类吸收。STANDARD 的信号覆盖面更广(trace 里几乎一定有 Choreographer 帧),总分常常压过专属的 TEXTUREVIEW,把 Flutter 应用误分到 STANDARD。同样的问题也出在 WeChat Skyline(被 WEBVIEW 吸收)和游戏引擎(被 STANDARD/MIXED 吸收)上。
修法不是调权重,而是给特化 pipeline 加 exclude_if:TEXTUREVIEW 一旦看到 Flutter 1.ui / 1.raster 信号就直接屏蔽 STANDARD 分类;STANDARD_LEGACY/MIXED/SURFACEVIEW_BLAST 看到 Game Engine 信号就互斥;OPENGL_ES 看到 WebView/Game 信号就互斥。24+ 种 pipeline 不能各打各的分,需要一个「特化 → 通用」的优先级链。 这是「pipeline 多了之后必须做相互排斥」的典型例子——也是为什么 Skill 数量增长到 160+ 之后,光「正确路由到哪个 Skill」本身就成了独立的工程问题。
厂商覆写 — 同一指标在不同平台上的字段名不同
高通、联发科、Google Tensor 的 trace 中,相同指标的字段名不同(比如 GPU 频率在高通叫 gpufreq,联发科可能叫 gpu_freq_khz)。.override.yaml 让同一个 Skill 在不同平台上自动适配 SQL,不需要为每个厂商写独立 Skill。
第五部分:SQL 工程
前面讨论的 Skill 系统最终都落到 SQL 查询上——每个 Skill 的 step 执行的是预定义的 SQL。SQL 是 SmartPerfetto 的核心——所有性能数据的获取最终都通过 SQL 查询 trace_processor 完成。这部分展开讨论 SQL 层面的几个工程问题:查询模式设计、官方 stdlib 复用、Schema 索引、结果压缩和纠错学习。
SQL 查询模式:时间区间 JOIN 和递归分桶
Perfetto trace 的数据本质上是带时间戳和持续时长的事件流。性能分析中最常见的操作是判断两个事件在时间上是否重叠——比如某帧渲染期间,主线程有没有被 Binder 调用阻塞。
YAML Skill 中大量使用的核心 SQL 模式是时间区间 JOIN——判断两个事件是否在时间上重叠。下面这条 SQL 的业务含义是:对于每个掉帧,找出在这帧渲染期间同时发生的阻塞调用(如 GC、Binder、锁),并计算它们重叠了多少毫秒:
1 | -- 业务含义:掉帧帧和阻塞调用的时间重叠分析 |
这里的
MIN(end1, end2) - MAX(start1, start2)是计算两个区间重叠长度的标准公式。在 Perfetto trace 中,时间戳精度到纳秒,这种区间 JOIN 能精确到 0.001ms 的粒度。
另一个常用模式是递归 CTE 做时间分桶。比如分析启动过程中 CPU 大核/小核的使用分布变化:
1 | -- 递归生成时间桶(最多 30 个,防止递归失控) |
_cpu_topology是 Perfetto stdlib 提供的视图,把 CPU 核心分类为 prime / big / medium / little。递归 CTE 限制最多 30 个桶,防止在极长 trace 上递归失控。
这些 SQL 模式被封装在 YAML Skill 中,通过 ${param|default} 语法接受参数。Claude 不需要自己写这些复杂的时间区间 JOIN——它调用 invoke_skill 传入时间范围和进程名,Skill 负责执行预定义的 SQL 并返回结构化结果。
Perfetto Stdlib 复用
Perfetto 官方维护了一套 SQL 标准库(stdlib),提供了大量预定义的视图和函数。比如 android_frames 视图封装了帧渲染数据的多表关联逻辑,_android_critical_blocking_calls 内部表汇总了关键阻塞调用。直接使用这些官方抽象,比手写 SQL 从底层表关联要稳定得多。
SmartPerfetto 对 stdlib 的集成经历了几轮迭代——其中一次回退还把「优化的方向」整个翻了过来:
初始阶段: 只预加载了 4 个 stdlib 模块(android.frames.timeline、android.binder、android.startup.startups、android.input),大部分 Skill 的 SQL 直接查底层表。优点是启动快,缺点是 Skill 里到处自己手写多表 JOIN
Round 7 (3/15): 把预加载集扩展到 22 个模块,包括
linux.cpu.utilization、android.garbage_collection、android.oom_adjuster、slices.with_context,覆盖 CPU/GC/OOM/slice 等常用维度。当时的逻辑是:trace 加载时一次性把所有常用 stdlib 模块批量INCLUDE,后续 Skill 查询零开销回退到 lazy 加载 (4/1, commit
0afeb60f): 22 模块的 eager preload 在生产中翻车了——200MB+ 的大 trace 上,启动时并发INCLUDE22 个模块会同时占用 trace_processor_shell 的 RPC 连接,触发socket hang up。根因是 trace_processor_shell 是单线程的 SQLite 引擎,最不擅长并发 INCLUDE 这种「批量 schema mutation」负载。 最终的修法是把 eager preload 收回,只保留 3 个 Tier-0 模块,且改成首次 query 时 lazy + 串行加载 + 最多 3 次重试:1
2
3
4
5
6
7// workingTraceProcessor.ts
// Tier 0: absolute minimum stdlib modules needed for any analysis to start.
const CRITICAL_STDLIB_MODULES = [
'android.frames.timeline', // 19 个 skill 引用 — frame/jank 基础
'android.startup.startups', // 16 个 skill 引用 — startup 基础
'android.binder', // 22 个 skill 引用 — IPC/blocking 基础
];这 3 个是按「skill 引用次数」筛出来的最高频依赖。其余 stdlib 模块改由 Skill YAML 的
prerequisites段或 SQL 里显式的INCLUDE PERFETTO MODULE在第一次用到时按需声明按需发现:
perfettoStdlibScanner.ts扫描 Perfetto 源码目录自动发现所有可用模块,通过list_stdlib_modulesMCP 工具让 Claude 按需INCLUDE非预加载的模块
1 | // perfettoStdlibScanner.ts — 扫描 perfetto/src/trace_processor/perfetto_sql/stdlib/ |
这次回退的教训和文章前面的「数据越多 Claude 输出反而越差」是同一类的——「在系统启动时把所有可能用到的资源都准备好」是直觉上最优、实际上最差的策略。无论是给 LLM 的上下文还是给 trace_processor 的 stdlib,先 lazy + 按需加载,等真正出现性能瓶颈再考虑预热,几乎总是更稳的选择。
另一个独立的教训是:使用 stdlib 的 android_garbage_collection_events 视图比自己 JOIN slice + thread + process 表查 GC 事件要稳定得多——因为 GC 事件的 slice name 在不同 Android 版本中有变化(concurrent mark sweep vs young concurrent copying vs HeapTaskDaemon),stdlib 已经处理了这些兼容性问题。但 stdlib 视图自己也有坑(列名前缀、模块未自动加载),后面 SQL 纠错那一节会展开讲。
SQL Schema Index:让 Claude 知道有什么表可以查
Perfetto trace_processor 包含数百个表和视图,加上 stdlib 的模块,Claude 不可能全部记住。lookup_sql_schema MCP 工具提供了一个搜索接口,让 Claude 按关键词查找相关的表、视图和函数定义。
底层是一个从 Perfetto 源码自动生成的索引文件(perfettoSqlIndex.light.json),包含 761 个模板,每个模板记录了名称、类别、类型(table/view/function)、列定义和参数。
查询时使用分词匹配 + 评分排序:
- 名称/类别/描述中包含完整搜索词 → 高分
- 多词查询按 token 分别匹配 → 匹配 ≥50% 的 token 才算相关
- 表名的下划线分段支持前缀匹配(”frame_time” 匹配 “frame_timeline_slice”)
- 返回 top 30 结果
配合 sqlKnowledgeBase.ts 的意图映射,还支持双语查询:用户输入「卡顿」会映射到 ['jank', 'frame', 'dropped'] 等搜索词,输入「启动」会映射到 ['android_startups', 'launch', 'time_to_display']。多个意图同时命中时,分数叠加——比如查询「启动帧卡顿」同时触发 startup 和 jank 两个意图,匹配到两者交集的模板分数最高。
SQL 结果压缩
当 Claude 使用 execute_sql 直接查询时,可以传入 summary=true 参数触发结果压缩。压缩逻辑在 sqlSummarizer.ts 中实现:
数值列: 计算 min、max、avg 和分位数(P50 / P90 / P95 / P99),让 Claude 了解数据分布,不需要看原始行。
字符串列: 统计 top 5 值及其出现次数,了解数据的类别分布。
样本行选择: 从完整结果中选 10 行有代表性的样本。选择策略是:如果数据中有 dur、latency、jank、count 等和性能相关的列,按该列降序排列取 top 10(最严重的数据通常最有分析价值);如果没有明确的性能指标列,等间距采样。
1 | -- 200 行原始结果 (~3000 tokens) 压缩为: |
这和前面提到的 Artifact Store 配合使用——Artifact Store 压缩的是 Skill 结果(invoke_skill 返回的数据),SQL Summarizer 压缩的是 Claude 直接执行 SQL 时的结果。两层压缩覆盖了 Agent 获取数据的两条路径。
SQL 纠错学习
Claude 对 Perfetto 的 SQL schema 不完全熟悉,会写出有错误的查询。以下是实际记录的典型错误(来自 logs/sql_learning/error_fix_pairs.json):
错误 1:JOIN 了不存在的列
Perfetto 的 slice 表没有直接的 utid 列。要关联 slice 和 thread,需要经过 thread_track 中间表:slice.track_id → thread_track.id → thread_track.utid → thread.utid。
1 | -- 错误: no such column: s.utid |
错误 2:列名歧义
1 | -- 错误: ambiguous column name: name (slice 和 process 都有 name 列) |
错误 3:对 counter 表的数据模型理解有误
Perfetto 的 counter 表存储的是采样点(时间戳 + 值),不是区间数据,没有 dur 列。
1 | -- 错误: no such column: c.dur |
错误 4:stdlib 表名 / 列名陷阱
这两条都是 commit 05922e67 加进去的——发现源是「无主孤儿 stderr」:分析早就结束了,trace_processor 还在喷错误日志,反查回去才定位到 Agent 在 dynamic SQL 里反复踩同样的坑。
1 | -- 错误 4a: no such table: cpu_frequency_counters |
stdlib 视图作者经常会用领域前缀的列名来避开多表 JOIN 时的 ambiguous column 问题,但 Claude 默认假设的是 ts/dur 这种通用约定。这种「stdlib 自己的命名习惯 vs 通用 SQL 习惯」的冲突没法靠 schema introspection 完全自动解决——lookup_sql_schema 工具能告诉 Claude 表存在和有哪些列,但不能预测「这次 Claude 一定会想当然地写 ts」。只能靠纠错对累积来兜底。
这些错误的检测和学习机制是这样的:当 SQL 执行失败时,错误信息和 SQL 被暂存;当后续有 SQL 执行成功时,系统通过 Jaccard 相似度匹配(排除 SQL 结构关键词如 SELECT/FROM/WHERE,以及 Perfetto 通用 token 如 utid/dur/slice)判断是否是同一查询的修正版本。匹配阈值 >30%,时间窗口 60 秒。匹配成功则生成 error→fix 对并持久化到磁盘。
新分析开始时,最近 10 条纠错对加载到 System Prompt,Claude 在写 SQL 之前就能看到这些已知的坑。纠错对设置 30 天 TTL,过期自动清理——Perfetto 的 SQL schema 会随版本更新变化。
第六部分:开发过程本身的 Harness 演进
最后一个部分稍微跳出产品本身,聊一下开发过程。SmartPerfetto 是用 AI 辅助开发的——从第一行代码到现在,Claude Code 是主要的编程工具。回顾这三个月,我使用 AI 辅助开发的方式本身也经历了几次迭代,和 SmartPerfetto 从 agentv2 到 agentv3 的演进有相似的逻辑。
AI 辅助开发的几个阶段
先简要说明涉及的工具和概念:
- Claude Code:Anthropic 的 CLI 工具,可以在终端中与 Claude 对话,Claude 能直接读写文件、执行命令。我在开发中一直开启
--dangerously-skip-permissions(危险模式)和 bypass permissions,让 Claude 无需逐次确认即可自主执行文件编辑、命令运行、Git 操作等。这大幅提升了迭代速度——Claude 可以连续执行「改代码 → 跑测试 → 看结果 → 修复 → 再跑」的完整循环而不被权限弹窗打断,代价是需要开发者对 Claude 的操作有足够信任和事后审查 - Claude Agent SDK:Anthropic 提供的 Agent 开发框架,SmartPerfetto 的 agentv3 后端基于它构建。SDK 封装了多轮对话管理、MCP 工具调用循环、上下文自动压缩(auto-compact)等能力,开发者定义工具集和 System Prompt,SDK 驱动 Claude 自主完成多轮分析
- Plan Mode:Claude Code 的规划模式,AI 先输出结构化实施方案(要改哪些文件、改什么、依赖关系),人审查确认后再执行代码修改
- SuperPower:Claude Code 的第三方插件生态,通过 MCP Server 为 Claude Code 注入额外能力。SmartPerfetto 开发中使用了 Chrome DevTools Protocol 插件(直接操控浏览器截图、调试前端)、Playwright 插件(自动化 UI 测试和截图)等。这些插件让 Claude Code 的能力从代码编辑扩展到了浏览器交互和可视化验证
- Codex + Codex MCP:Codex 是 OpenAI 的代码推理模型。通过 Codex MCP Server 集成到 Claude Code 中后,Claude 可以在对话过程中直接调用 Codex 做独立审查——把实施方案发给 Codex,Codex 以只读方式访问代码库,从架构合理性、边界情况、遗漏风险三个角度给出反馈,整个过程不需要离开 Claude Code 的工作流
- Agent Team:Claude Code 支持启动多个子 Agent 并行工作,每个 Agent 可以有独立的工具集和角色定义
- Skills / Hooks:Claude Code 的扩展机制,Skills 是可复用的任务模板(如
/commit、/simplify),Hooks 是在特定事件(如工具调用前后)自动执行的脚本
我的实际演进过程
阶段 1:直接对话
最早期的开发方式是在 Claude Code 中直接描述需求,让 AI 修改代码。类似于结对编程中一个人说、一个人写。这个阶段人需要逐行审查每次修改,因为 AI 对项目上下文的理解有限,经常做出不符合整体架构的局部修改。
阶段 2:Plan Mode(SuperPower)
开始使用 Plan Mode 后,工作流变成:我描述需求 → AI 输出结构化的实施方案(要改哪些文件、每个文件改什么、改动顺序和依赖关系)→ 我审查方案 → 确认后 AI 执行。这把 review 的重心从「逐行看代码」转移到了「审查架构方案」,效率明显提升。
阶段 3:Plan Mode(SuperPower) + 引入同行 Review(Codex)
单靠一个 AI 生成方案,容易出现盲区。我开始在 Plan Mode 的方案确定后,把方案发给 Codex 做独立审查。Codex 以只读方式访问代码库,从架构合理性、边界情况、遗漏风险三个角度给反馈。这相当于在 AI 开发流程中引入了 code review 环节。
文章前面提到的 9 轮架构审查,大部分都经过了这个流程。以 Perfetto Stdlib 集成为例(Round 7,3 月 15 日),Codex 审查了 3 轮,累计提出 36 条反馈,其中涉及 stdlib 模块预加载策略、Schema Index 的缓存失效机制等我在方案中遗漏的问题。
阶段 4:Harness 化的工程流水线
到后期,开发流程变成了:
1 | 1. 我确定需求和架构方向 |
这个流程中,人的介入集中在第 1 步(需求和架构决策)和第 4 步(评估 review 反馈)。代码细节、测试执行、格式整理由工程流水线完成。
和 SmartPerfetto 架构的对应关系
回过头看,我的 AI 辅助开发流程和 SmartPerfetto 的 Agent 分析流程在结构上是相似的:
| 维度 | SmartPerfetto Agent 分析 | 我的 AI 辅助开发 |
|---|---|---|
| 意图理解 | Scene Classifier 识别场景 | 我确定需求方向 |
| 策略注入 | .strategy.md 注入分析方法论 | Plan Mode 输出实施方案 |
| 执行 | MCP 工具调用 SQL/Skill | Claude Code 执行代码修改 |
| 质量验证 | 三层 Verifier (启发式+Plan+Haiku) | 回归测试 + Codex review |
| 纠正循环 | Correction Prompt 让 Claude 修正 | 测试失败 → 分析 → 修复 → 重跑 |
| 跨会话学习 | Pattern Memory + SQL 纠错 | CLAUDE.md 规则积累 + memory 系统 |
两个系统的演进方向也一致:人的介入从执行层逐步上移到决策层。 SmartPerfetto 从固定管线(人定义每一步)到自主推理(人定义目标和约束);我的开发方式从逐行 review 到审查架构方案。
这不是偶然——Harness Engineering 的核心就是构建足够的工程基础设施(测试、验证、review),使得人可以信任 AI 的执行结果,把注意力放在更高层的决策上。
下图汇总了 SmartPerfetto 的 Harness Engineering 全景——从输入路由到跨会话学习:

结语
回顾这三个月的迭代,从 agentv2 的 13 步固定管线到 agentv3 的自主推理,从约 30% 误判率到三层验证,从 15000 tokens 的 System Prompt 到 4500 tokens 的按需加载——每一步变化都有具体的失败经历在推动。
做完这个项目之后,我对 AI Agent 应用开发有两个体会。
第一个是:主要工作量不在 LLM API 调用本身,而在围绕 LLM 的工程基础设施:
- System Prompt 怎么组织,才能让 LLM 不混淆上下文?→ 场景分类 + 按需加载 + Token 预算
- 怎么控制 LLM 的执行顺序,让它先想再做?→ Planning Gate + Hypothesis 提交
- 返回多少数据给 LLM 合适?→ Artifact Store,给摘要而不是全量
- 怎么发现和拦截 LLM 的领域误判?→ 三层验证 + Correction 循环
- 怎么保证数据查询的精度?→ YAML Skill (声明式 SQL) + SQL 纠错学习
- 怎么适配不同渲染架构和芯片平台?→ 架构检测 + 厂商覆写
第二个体会是:Agent 的「环境」比 prompt 的措辞重要得多。 agentv3 初期我花了不少时间调整 System Prompt 的用词和格式,后来发现真正影响 Agent 输出质量的不是 prompt 怎么写,而是给它什么工具、返回什么数据、施加什么约束。三个具体的例子:
- 加了
submit_plan门控后,Claude 不再没有方向地查 SQL(之前会出现连续SELECT * FROM slice→SELECT * FROM thread的无目的查询),分析路径变得有组织 - 加了 ArtifactStore 后,Claude 接收到的数据从 200 行降到摘要引用,推理的聚焦度明显提升
- 加了
lookup_knowledge工具后,根因分析的深度从「主线程阻塞」推进到「Binder 对端 system_server 因 CPU 被调度到小核导致响应延迟」
这些改进都不是通过调整 prompt 文字实现的,而是通过改变 Agent 的工具集和数据环境实现的。如果我要给做 AI Agent 应用的工程师一个建议,就是把精力放在工具设计和数据控制上,而不是 prompt engineering 上。
后续方向
当前的 SmartPerfetto 是一个交互式分析工具,还远远没有达到可以发布的程度,所以目前还是闭源的,由我个人在负责开发。后续的工程方向包括:
- 厂商深度接入 — 当前 8 个厂商的
.override.yaml只覆盖了核心 Skill。更多厂商专属指标(高通 Snapdragon Profiler 数据、联发科 MAGT 信号、三星 GameOptimizing 服务)需要逐一对接 - CI 集成 + 批处理 — 从交互式分析到 CI Pipeline 中自动分析每次构建的性能回归。包括无人值守模式、结果对比基线、自动标记 regression
- E2E 验证框架 — 当前的 6 条 trace 回归测试验证 Skill 产出数据的正确性,但不验证 Agent 的结论质量。需要建立 E2E 验证:给定 trace + 已知根因 → 检查 Agent 是否正确定位
- 代码库接入 — 将 trace 中的 slice/function 映射回源码位置,结合 git blame 定位变更引入点
在合适的时候本工具会开源处理(因为各个大厂内部都在做了,所以开源出来大家集思广益,共同开发),对进度感兴的同学可以加我微信进群聊或者私聊。
关于我 && 博客
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
- 博主个人介绍 :里面有个人的微信和微信群链接。
- 本博客内容导航 :个人博客内容的一个导航。
- 个人整理和搜集的优秀博客文章 - Android 性能优化必知必会 :欢迎大家自荐和推荐 (微信私聊即可)
- Android 性能优化知识星球 : 欢迎加入,多谢支持~
一个人可以走的更快 , 一群人可以走的更远