


5 月 17 日写上一篇 SmartPerfetto 更新时,重点已经从“Perfetto UI 里的 AI Assistant”转向“可复用的 Trace 分析平台”。到 6 月 4 日,新增内容主要集中在五块:Smart 模式、选区快问、CLI 采集、Power / ANR / Input / IO / Network 证据规则,以及四条 Agent runtime。
本文基于 2026 年 6 月 4 日的 SmartPerfetto 主分支状态,公开发布版本是 v1.0.28。读者看完应该能知道三件事:5 月 17 日之后新增了什么、现在的运行时和证据来源怎么处理、反馈问题时该给哪些信息。
项目地址:
- SmartPerfetto 主仓库:https://github.com/Gracker/SmartPerfetto
- 上一篇更新:https://www.androidperformance.com/2026/05/17/SmartPerfetto-Two-Week-Update/
2026.05.17-06.04 变化概览
上篇文章里的功能图还是 SmartPerfetto v1.0.7。当前公开版本已经到 v1.0.28,仓库里有 230 个 *.skill.yaml,去掉 _template 后是 226 个功能性 Skill 文件;backend/strategies/ 里有 20 个 .strategy.md 和 35 个 .template.md。
数量变化不算夸张,变化集中在六类用户能感知到的地方:
| 方向 | 5 月 17 日状态 | 现在的状态 |
|---|---|---|
| 分析入口 | Perfetto UI 里直接问 trace,支持 fast / full / auto | Smart 模式先做 scene inventory,选区快问可以只分析当前范围,CLI 也能复用分析核心 |
| CLI 和采集 | CLI / API 已进入文档和发布流程 | smp capture、smp analyze、compare workflow、CLI turn files 和 npm 包验证进入常规发布流程 |
| 场景覆盖 | startup、scrolling、ANR、interaction、touch、memory、power、network 等已有策略 | 新增 smart.strategy.md、io.strategy.md,Power / ANR / Input / Display / IO / Network / Observability 的证据要求被写进策略和测试 |
| 证据可靠性 | SQL guardrail、证据 ID、逐句数据引用已经成型 | 失败 SQL 不再进入前端证据;最终报告检查、claim verifier 和按场景区分的证据规则覆盖更多场景 |
| 模型接入 | Claude Agent SDK 与 OpenAI Agents SDK 是一等 runtime | claude-agent-sdk、openai-agents-sdk、pi-agent-core、opencode 四条 runtime 共用一组输出规则 |
| 发布验证 | Docker、portable、source、CLI 都已进入发布说明 | v1.0.28 发布前跑过四 runtime startup / scrolling strict E2E、6 条 canonical scene trace regression、npm / portable / Docker 验证 |
这轮更新的主线是把更多场景做成可验证的分析流程。模型仍然负责解释和排序,性能数字仍然来自 trace_processor_shell、SQL、Skill 表格和报告里的结构化证据。
当前功能地图
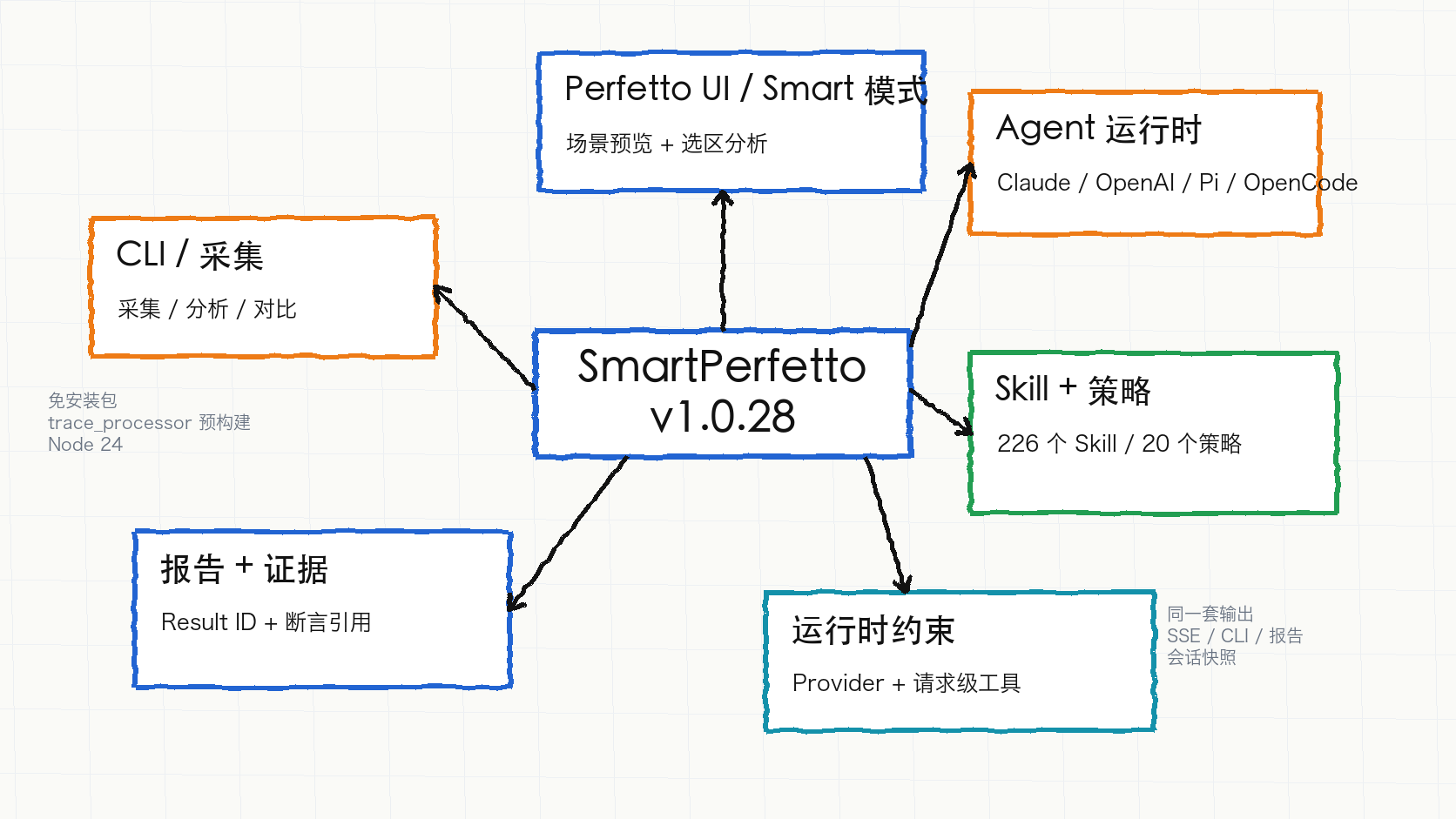
SmartPerfetto 现在可以按“入口、分析、证据、runtime、分发”五层理解。
| 功能面 | 当前能力 | 适合场景 |
|---|---|---|
| Perfetto UI / Smart Mode | 加载 .pftrace / .perfetto-trace 后可以直接提问,也可以先让 Smart 模式识别 startup、scrolling、click、navigation、ANR、device-state 等范围 |
混合 trace 里先找值得分析的片段,避免一上来把整条 trace 交给 full analysis |
| 选区快问 | Perfetto area selection / track event selection 会带上 selectionContext,后端用 bounded scope 跑 quick analysis |
只看某段时间、某一帧、某个 slice 前后发生了什么 |
| CLI / Capture | smp / smartperfetto 入口复用后端 runtime、MCP 工具、Skill、report 和 session snapshot |
在终端、脚本、CI 或远程环境里采集和分析 trace |
| Skills + Strategies | 226 个功能性 Skill 文件、20 个场景策略、35 个模板,覆盖 startup、scrolling、ANR、interaction、memory、power、network、pipeline、IO、smart 等场景 | 把自然语言问题路由到确定性的 SQL、Skill 和输出要求 |
| Reports + Evidence | HTML report、Result ID、analysis-result snapshot、claim refs、data source narration、CLI turn files 一起保留 | 把“AI 说了什么”回到“哪条 SQL / 哪个 Skill / 哪行证据” |
| Agent Runtimes | Claude、OpenAI、Pi Agent Core、OpenCode 四条 runtime 由 Provider 或 env 显式选择 | 同一条 trace 分析可以接不同 SDK / server 编排方式 |
| Runtime Guardrails | Provider Manager、request-scoped MCP tools、session snapshot、/health runtime diagnostics 共同约束 runtime 行为 |
排查“连接测试过了,但分析 runtime 没切过去”这类问题 |
| 发布方式 | Docker Hub、Windows / macOS / Linux portable、源码 ./start.sh、npm CLI 都有发布验证 |
普通用户试用、开发者调试、团队部署和脚本接入 |
这里要先写清一条规则:SmartPerfetto 没有把整条 trace 直接塞进 prompt。模型看到的是后端工具返回的 SQL 结果、Skill 输出、scene context、报告摘要和结构化证据。新增 runtime 也不能绕开这条规则。
新功能一:Smart 模式、选区快问和 CLI 入口共用分析核心
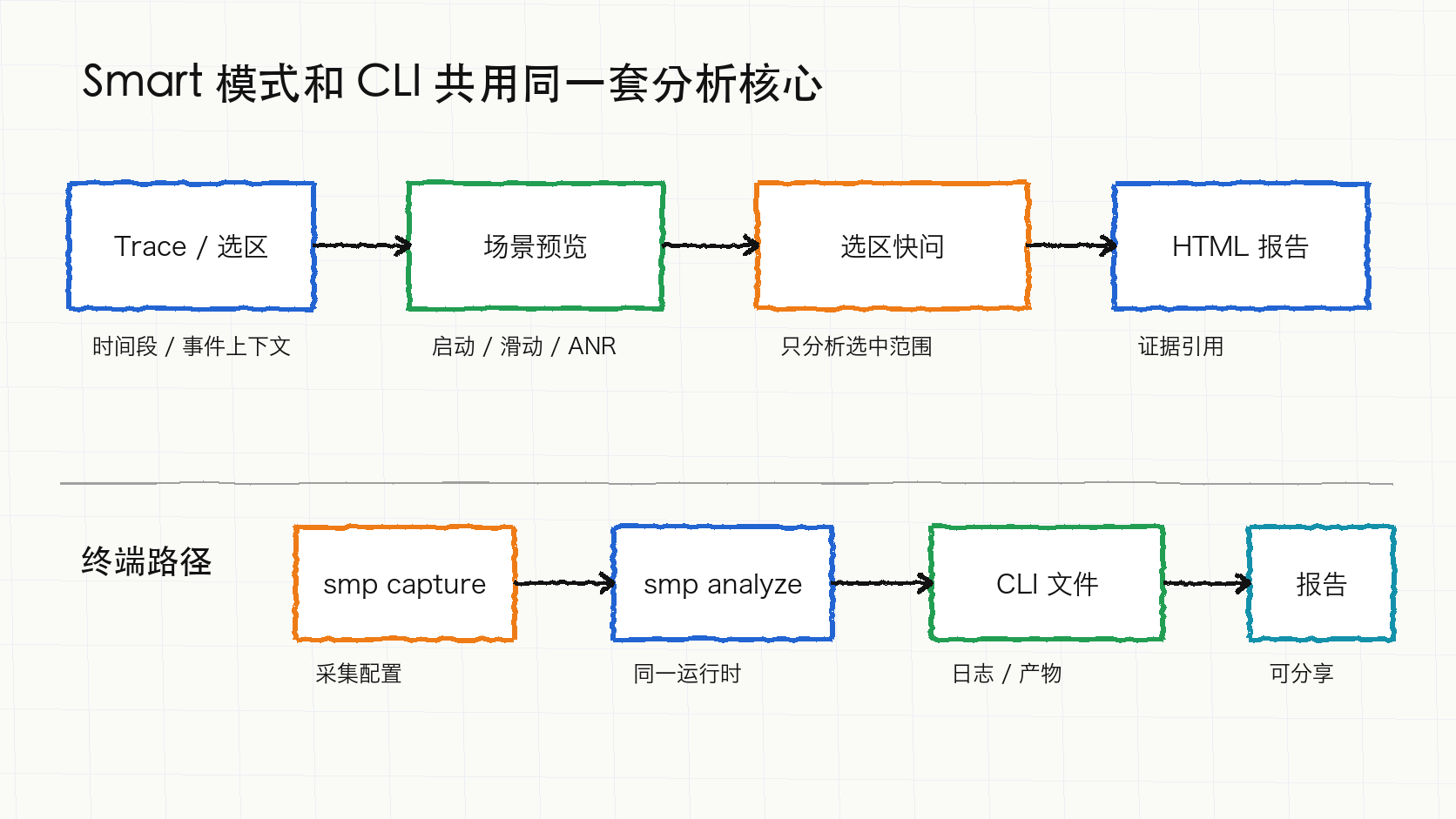
上篇文章里已经有 fast / full / auto 三种分析模式。5 月 17 日之后,SmartPerfetto 又补了两条入口:Smart scene selection 和 range-scoped quick analysis。
Smart 模式先做 scene inventory。对混合 trace 来说,启动、滑动、点击、页面跳转、ANR、设备状态变化可能混在一条文件里。SmartPerfetto 会先识别可分析范围,给出每个 scene 的 eligibility、confidence、context、verification 和 report id,再让用户选择深挖全部 scene,或者只分析 startup、scrolling、click、navigation、device-state、ANR 中的一类。
选区快问解决的是另一个问题。Perfetto UI 里选中一段时间或一个 track event 后,用户常问的是“就这段为什么慢”“这个 slice 前后发生了什么”。现在后端会把范围上下文传入分析请求,quick path 只围绕这段时间拿证据,不必把整条 trace 都走 full analysis。
CLI 入口也从“能调用后端接口”变成了独立的终端产品。smp capture 面向采集,smp analyze 面向分析,compare workflow、session 文件、报告输出和 Provider/runtime 选择规则都复用 Web 侧逻辑。CLI 不启动 Web UI,也不会另起一套分析逻辑。
用户层面的变化很直接:
| 使用场景 | 之前 | 现在 |
|---|---|---|
| 混合 trace 初筛 | 手动看 timeline,再问某个场景 | Smart 模式先列 scene,再点选深挖范围 |
| 选中一段卡顿 | 复制时间戳或手写范围 | 选区上下文进入后端,quick analysis 只看当前范围 |
| 远程机器采集 | 先靠系统工具采 trace,再搬到 UI | smp capture 负责采集,smp analyze 继续使用同一组 Skill / report |
| 回归对比 | UI 里选 reference 或 Result ID | CLI compare workflow 和 analysis result snapshot 可以接脚本 |
这也是后面四 runtime 能成立的前提。入口可以是 UI、CLI 或 API,底层都要回到 AgentAnalyzeSessionService、Skill、MCP 工具和 report 检查。
新功能二:证据规则从启动和滑动扩到更多场景
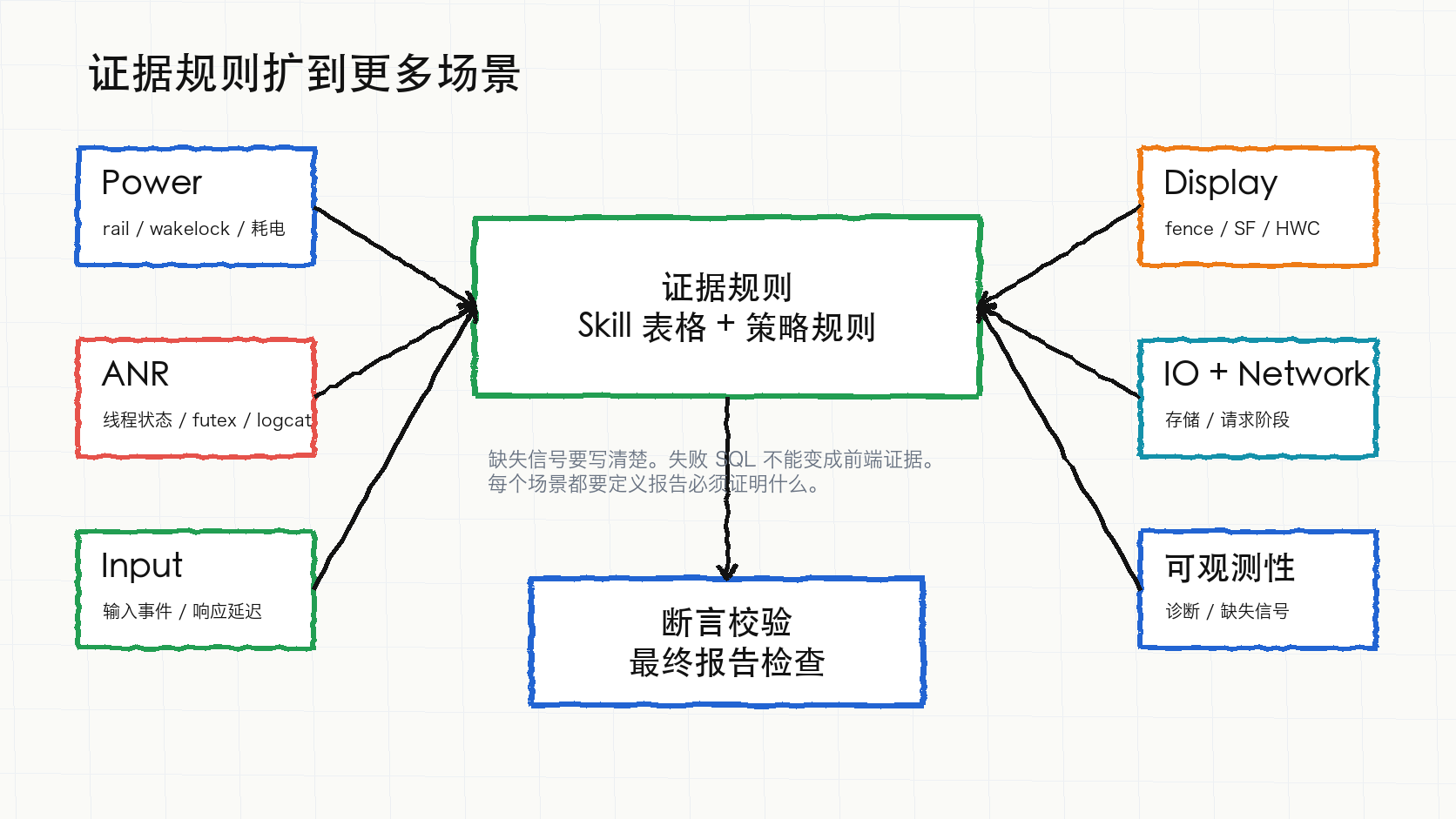
SmartPerfetto 前几轮最重的场景是 startup 和 scrolling。5 月底这轮新增的重点,是把“报告必须证明什么”写到更多策略里。
这批改动覆盖了几类场景:
| 场景 | 新增或加强的证据要求 | 用户能得到什么 |
|---|---|---|
| Power | battery drain、power rails、wakelock、CPU freq / idle、JobScheduler、modem / network 相关 Skill | 不只看 CPU 热点,还能把后台耗电、rail 能耗、唤醒频率和调度事件放到同一份报告里 |
| ANR | anr_context_in_range、main thread states / slices、futex wait、logcat、ANR detail 的要求被加强 |
区分主线程运行、等待、futex、Binder、logcat 信号,减少“看到卡住就写 ANR 根因”的误判 |
| Input / Interaction | input events、scroll response latency、click response analysis / detail 进入 Skill 和 strategy | 从触摸输入到响应延迟有独立证据,不把所有卡顿都归到渲染线程 |
| Display / Pipeline | fence wait decomposition、pipeline strategy 里的 display 证据要求 | 把 producer、SurfaceFlinger、HWC、fence 等证据和报告结论绑定 |
| IO / Network | io.strategy.md、network request-stage evidence template |
IO 等待、网络请求阶段和场景结论之间有明确证据入口 |
| Observability | diagnostics evidence template、missing signal policy、trace completeness prober | trace 缺少必要表或 category 时,报告应写缺失信号,而不是补一个确定结论 |
这里的变化比加几个 SQL 更大。以前报告质量主要靠 prompt 要求模型“引用证据”;现在策略 frontmatter、Skill 证据边界、最终报告检查和 claim verifier 一起工作。报告里出现关键数值、线程、进程、帧数、百分比时,需要能回到对应的证据来源。
这也解释了为什么“failed SQL diagnostics”不能直接进入前端证据。失败 SQL 可以帮助维护者排错,但不能被用户当作 trace 事实。现在会把已验证的数据、诊断信息、报告可见文本和 snapshot provenance 分开保存。
新功能三:四条 runtime 共用同一套输出规则
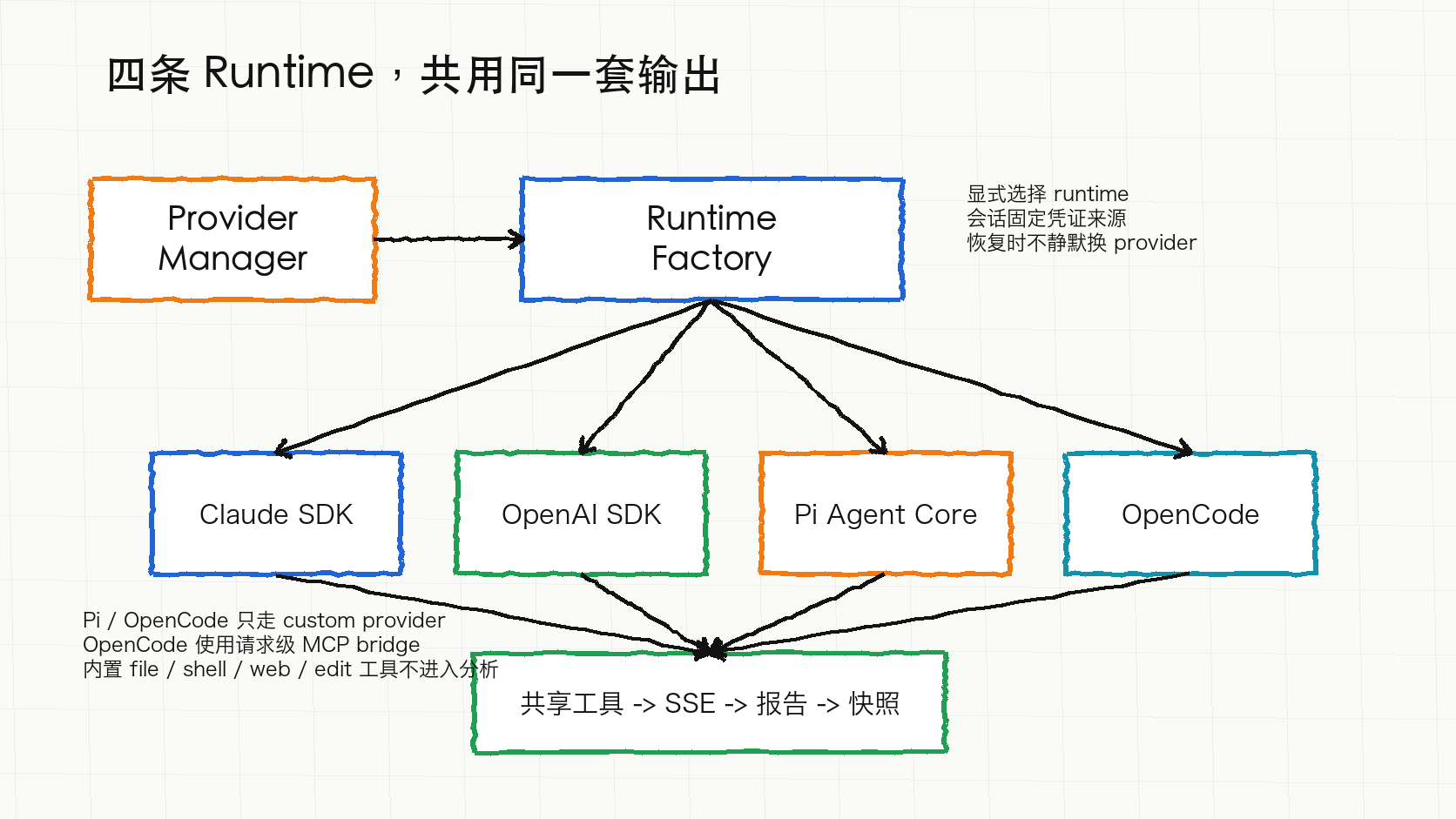
上篇文章写到 Claude Agent SDK 和 OpenAI Agents SDK。v1.0.28 之后,SmartPerfetto 有四条 runtime:
| Runtime | 适合的 Provider | 限制 |
|---|---|---|
claude-agent-sdk |
Anthropic、Bedrock、Vertex、DeepSeek、Anthropic-compatible gateway、本机 Claude Code 配置 | 默认路径,继续支持 in-process MCP server、verifier、sub-agent 和 SDK resume |
openai-agents-sdk |
OpenAI、Ollama、OpenAI-compatible gateway | 通过 function tools 复用同一份 SmartPerfetto MCP tool registry |
pi-agent-core |
custom provider | 可选 public runtime,复用 SmartPerfetto 的 prompt、tool、report 管线;不启用 .pi discovery、package extension、shell / file tools |
opencode |
custom provider 或显式 OpenAI-compatible 配置 | 使用 request-scoped SmartPerfetto MCP bridge,不读取用户自己的 OpenCode 登录态、project state,也不启用内建 file / shell / web / edit tools |
Provider Manager 和 env 不会用“哪个 key 存在”去猜 runtime。选择优先级是请求 / session 里的 providerId、Provider Manager active provider、SMARTPERFETTO_AGENT_RUNTIME,再退回默认 claude-agent-sdk。已经创建的分析 session 会固定当时的 credential source;恢复旧 session 时不会因为后来切换 active provider 就静默换模型。
四条 runtime 的内部机制差异很大。Claude runtime 暴露 in-process MCP server;OpenAI runtime 把同一份工具 descriptor 适配成 function tools;Pi Agent Core 使用 request-scoped native tools;OpenCode 通过隔离的 server 和 MCP bridge 调用当前分析请求可见的 SmartPerfetto 工具。
对外输出只有一套:
1 | runtime result |
发布前的验证也按这套输出做。v1.0.28 发布前,Claude、OpenAI、Pi Agent Core、OpenCode 四条 runtime 都跑过 startup / scrolling strict E2E;8 条 E2E 都要求 claim verifier 通过、12 个 checked claims、0 unsupported / issues、非 partial final report。除此之外,还跑了 6 条 canonical scene trace regression、前端预构建检查、CLI pack check、npm fresh install smoke、portable package、GitHub Release 和 Docker Hub manifest 验证。
这不是说四条 runtime 的输出会逐字一致。不同 SDK 的工具调用节奏、流式事件、上下文恢复、成本和超时语义都不同。SmartPerfetto 约束的是公共输出:SSE 事件、HTML report、CLI turn files、analysis-result snapshot、claim verification 和 session resume 不能因为 runtime 换了就换一套语义。
新功能四:报告质量和排错信息更具体
这三周里还有一批改动看起来不如 runtime 显眼,但对真实使用更关键。
第一类是报告完整性。ensure complete agent final reports、final report presentation hardening、evidence table readability、analysis quality rules 这些改动处理的是同一个问题:模型跑了很多工具,不等于交给用户的报告完整。现在报告需要满足场景定义的最终报告规则,结论里的断言要能通过 claim verifier,前端可见文本可以清理噪音,但不能把报告、CLI、snapshot 需要的 provenance 删掉。
第二类是 SQL 和诊断分开。raw SQL artifact、failed SQL diagnostics、trace processor startup failures 都做了更明确的处理。失败的 SQL 诊断可以进日志和调试材料,不应该混进“本次 trace 的证据表”。trace_processor_shell 启动失败、预编译产物缺失、加载 trace 出错,也要在健康检查或错误信息里直接暴露,不能让用户把它当成 AI 结论质量问题。
第三类是 codebase-aware 分析。SmartPerfetto 可以把本地代码库上下文接进分析任务,但它不能替代 trace 证据本身。代码定位只能补充解释和修复方向,性能判断仍要回到 trace 数据。
这类改动会让 bug 反馈更具体。以前用户可能只能说“AI 结论不对”;现在可以贴 Result ID、HTML report、evidenceRefId、claim ref、相关 SQL、Skill 表格和 /health 的 runtime 信息。
可用性修复
新增功能之外,最近的修复主要集中在“能不能稳定跑完第一条真实 trace”和“出了问题能不能定位”。
| 修复方向 | 用户感知 |
|---|---|
| trace processor 预编译产物 | 源码和 npm CLI 更容易拿到固定版本的 trace_processor_shell,启动失败会有更明确的错误 |
| Provider debug status | /health 里能看到实际 runtime、credential source、provider mode 和 diagnostics |
| Node 24 hardening | 源码和 CLI 要求 Node.js >=24 <25,减少 Node 版本漂移带来的构建和 runtime 问题 |
| npm CLI bin | smp / smartperfetto 作为有效 bin 发布,fresh install 后可以直接跑版本和 doctor smoke |
| service port 配置 | 支持可配置 SmartPerfetto service ports,不再把端口清理做成粗暴杀进程 |
| Docker healthcheck | Docker healthcheck 语法修正,发布流程能覆盖 runtime image smoke |
| frontend evidence table | AI Assistant 里的证据表可读性提升,报告和聊天里的表格更容易检查 |
| final SSE conclusion | SSE 结论、analysis_completed、HTML report 的终态关系更稳定 |
| raw SQL artifact | 原始 SQL、最终可执行 SQL、失败诊断和用户可见证据分开处理 |
| release verification | npm、portable、GitHub assets、Docker latest / version tag 都有发布后验证 |
这类修复不一定适合放在功能宣传里,但它们决定了工具能不能被真实 Android 性能团队使用。SmartPerfetto 的状态同时跨 Perfetto UI、Express 后端、SSE、trace processor、Provider 协议、模型 SDK、CLI、Docker 和 portable 包。任何一层状态漂移,都会被用户看成“AI 分析不可靠”。
现在怎么选运行方式
普通用户仍然优先选 Docker 或免安装包;开发者和脚本用户再考虑源码和 CLI。
| 运行方式 | 适合谁 | 说明 |
|---|---|---|
| Docker Hub | 想快速试用或部署的人 | 不依赖宿主机 Claude Code 登录态;需要用 Provider Manager 或 .env 配 provider |
| 免安装包 | 不想装 Node.js / Docker 的用户 | Windows、macOS、Linux portable 包自带 Node.js 24、后端、预构建 frontend 和固定 trace processor |
本地源码 ./start.sh |
想跟主干或改后端 / Skill / 策略的人 | 使用仓库提交的预构建 frontend,常规后端和 Skill 改动不需要构建 Perfetto UI |
Dev 模式 ./scripts/start-dev.sh |
修改 AI Assistant 插件 UI 的人 | 需要初始化 perfetto/ submodule,并用 watch 构建插件 |
npm CLI smp |
需要终端采集、分析、CI 接入的人 | 不启动 Web UI,复用同一组 runtime、MCP 工具、Skill、report 和 session snapshot |
Runtime 配置上,第一次只选一种方式:
| 你现在有什么 | 推荐选择 |
|---|---|
本地源码运行,终端里的 claude 已经能用 |
默认 claude-agent-sdk,不需要额外配置 OpenAI key |
| OpenAI、Ollama 或 OpenAI-compatible gateway | openai-agents-sdk |
| Pi Agent Core model 配置 | custom provider + pi-agent-core |
| OpenCode model 配置 | custom provider + opencode |
| Docker / portable,不想碰 env | UI Provider Manager 里创建并激活 provider profile |
不要把 provider 名称写进 SMARTPERFETTO_AGENT_RUNTIME。这个变量只接受 claude-agent-sdk、openai-agents-sdk、pi-agent-core、opencode。DeepSeek、Qwen、Kimi、MiMo、TokenHub 这类 provider 应该通过 Provider Manager 或对应协议的 env block 配置。
Bug 反馈该怎么写
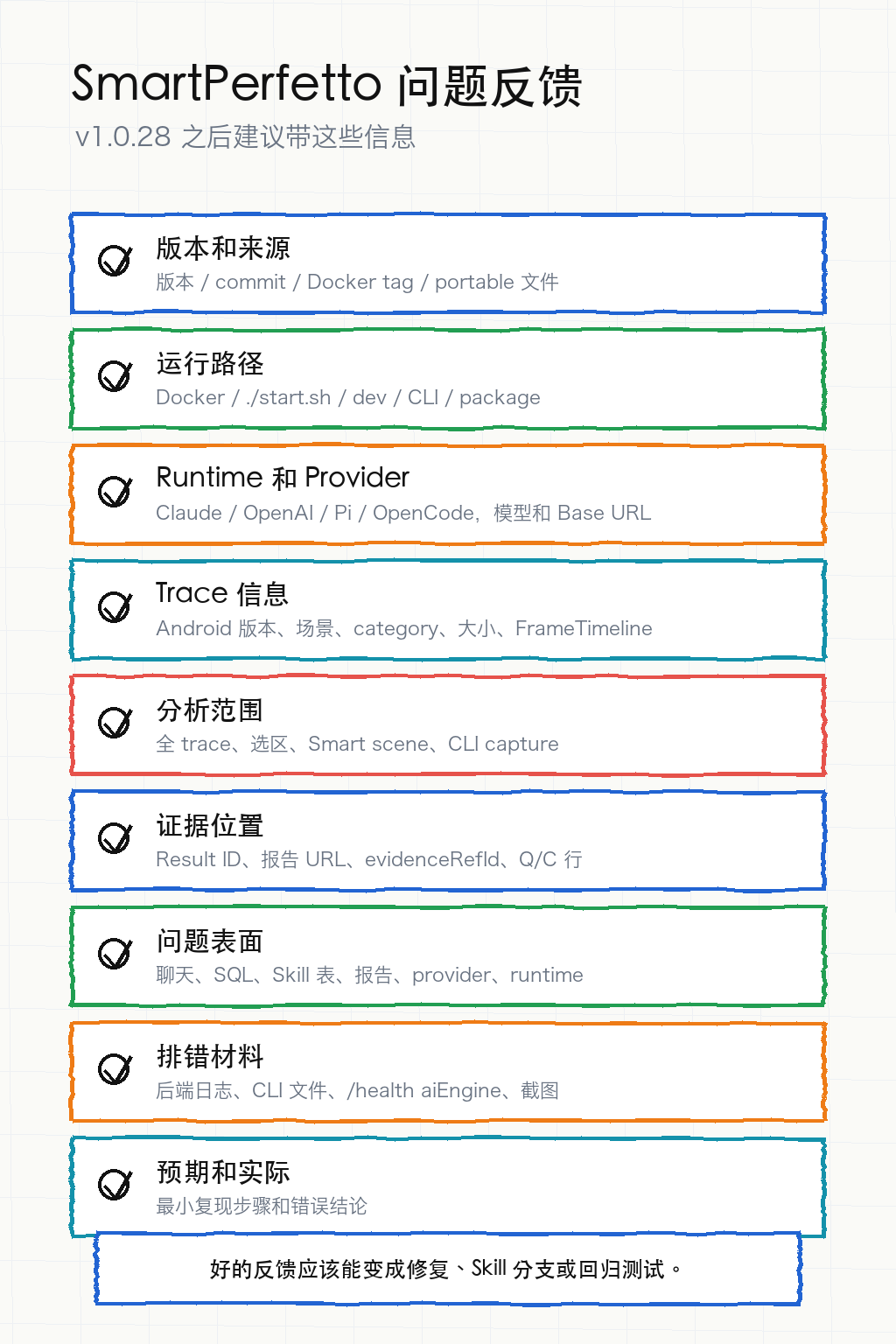
SmartPerfetto 的 bug 反馈入口仍然是 GitHub Issues。安全问题不要发公开 issue,走 GitHub private advisory 或安全邮箱。
v1.0.28 之后,一份可定位的反馈建议包含这些字段:
| 类别 | 要写什么 |
|---|---|
| SmartPerfetto 版本 | 版本号、commit、Docker image tag、portable 文件名、npm CLI 版本,至少给出一种 |
| 运行方式 | Docker、portable、源码 ./start.sh、dev 模式、npm CLI、API |
| Runtime / Provider | claude-agent-sdk、openai-agents-sdk、pi-agent-core、opencode;provider 名称、模型 ID、Base URL、协议类型 |
| Trace 信息 | 设备、Android 版本、业务场景、trace category、是否包含 FrameTimeline、trace 大小 |
| 分析范围 | 全 trace、selected range、Smart scene、CLI capture,是否多轮追问或中途切换模式 |
| 证据定位 | Result ID、HTML report、evidenceRefId、claim ref、Q/C 行、相关 SQL 或 Skill 表格 |
| 问题表面 | chat 文本、SQL、Skill 表、报告、provider 连接、runtime 选择、session resume、CLI 输出 |
| 证据材料 | 后端日志、CLI turn files、/health 的 aiEngine 片段、截图、HTML report |
| 预期与实际 | 最小复现步骤,实际输出,预期输出,以及人工判断依据 |
Provider 相关问题要把“模型能聊天”和“模型能稳定 tool / function calling”分开。SmartPerfetto 依赖流式输出、结构化工具参数、上下文恢复和长程报告生成。普通聊天正常,不代表能跑完整 trace 分析。
Trace 相关问题也要写采集条件。Android 12+ 且包含 FrameTimeline 的 trace 更适合启动、滑动和渲染分析;Power、ANR、网络、IO 各自需要不同 category。缺少数据源时,正确行为是报告缺失信号,不是补一个确定结论。
当前更需要的反馈
SmartPerfetto 现在更需要能变成代码修复、Skill 分支或回归测试的反馈。
更有价值的样本通常长这样:
- 某条 power trace 里,报告把耗电归到 CPU,但人工看是 wakelock 或 modem 活跃。请附 power rails、wakelock、CPU freq / idle 相关证据位置。
- 某条 ANR trace 里,报告说主线程被 futex 阻塞,但 logcat 或 thread state 不支持。请附 ANR 时间段、main thread state 表、futex wait 表和 logcat 片段。
- 某个 OpenAI-compatible provider 连接测试通过,但 full analysis 的 tool 参数变形。请附 runtime、provider、模型 ID、协议类型、session log 和
/health片段。 - 某个 OpenCode 或 Pi Agent Core 配置能 smoke,但 startup / scrolling E2E 质量不稳定。请附模型配置、运行命令、Result ID 和 HTML report。
- 某个 Smart scene 识别错了范围。请附 trace 时间段、scene inventory 输出、期望 scene 类型和人工判断依据。
- CLI capture 或 analyze 在远程机器失败。请附 Node 版本、平台、
smp doctor --format json、CLI turn files 和 trace processor 错误。
只有截图和一句“结果不对”,维护者很难判断问题在 trace 采集、SQL、Skill、场景策略、Provider 协议、runtime session、前端展示还是报告规则。
结尾
SmartPerfetto 在 2026 年 5 月 17 日到 6 月 4 日之间的主线很清楚:Perfetto UI 仍然是入口之一,CLI 和 API 也在复用同一套分析流程;runtime 可以不同,证据和报告规则要一致。
它仍处在快速开发阶段。Provider preset、runtime 配置、public API、报告规则和 Skill 体系都会继续调整。对普通用户来说,最稳的方式是用 Docker 或 portable 跑一条自己的 trace;对贡献者来说,最有用的输入是可复现 trace、带证据位置的错误归因、能补进 Skill / strategy 的 SQL 和回归样本。
5 月 17 日那篇文章已经不足以代表当前仓库状态。现在再试 SmartPerfetto,优先看 Smart 模式、选区快问、CLI 和四 runtime 配置。