

Starting from Ming-Chi Kuo’s April 27, 2026 supply-chain report about an OpenAI phone, this article looks at the possible system shape after phones and AI merge, from the perspective of someone who works on Android phones.
Introduction: This Is Not Just a New Phone Problem
The most interesting part of Kuo’s report is not the 2028 mass-production window. It is not whether MediaTek, Qualcomm, or Luxshare ends up in which supplier position either.
It pushes the question into the system layer:
If the user’s primary goal shifts from opening apps to completing tasks, what should a phone operating system look like?
That sounds like a UI question. From an Android practitioner’s perspective, it touches the whole system structure: Launcher, notifications, permissions, IPC, app capability declarations, model runtime, TEE, device-cloud sync, task state machines, audit logs, payment confirmation, and developer revenue sharing all need to be reconsidered.
Over the past few years, most discussions about AI phones have stayed at the feature layer. Vendors talk about AI photo editing, AI erase, AI summaries, AI search, AI assistants, and AI briefings. All of these can fit inside today’s Android or iOS architecture.
If OpenAI really builds an AI Agent phone, it will move the question from “how many AI features can be added to a phone” to “should the phone’s first entry point still start from app icons?”
The main line is this: Agent OS looks like a structural migration of mobile OS after the graphical interface era. The foreground moves from an app grid to a task stream. The background moves from app-owned capability to authorized capability. The system moves from managing processes and windows to managing tasks, context, and responsibility.
OpenAI does not have to build on Android, but Android is the more likely path because it inherits hardware adaptation, drivers, app compatibility, and supply-chain experience. If OpenAI wants to design the first screen, permissions, and task flow completely around Agent OS, it may also choose an “Android-compatible but not quite Android” path, or even build a Linux-based system and fill the service gap with the web, cloud execution, and an app compatibility layer.
Different OS choices will change go-to-market speed. They will not change the five things Agent OS must solve:
- The phone must continuously understand the user’s current state.
- Apps must move from foreground entry points to background capability providers.
- The system must have a task runtime that is recoverable, cancellable, and auditable.
- Device-side and cloud-side execution must be split by data sensitivity and real-time needs.
- Every cross-app, cross-device, and cross-cloud action must have permission, responsibility, and rollback boundaries.
Without these five things, an AI phone is still just “a phone with an AI assistant.” Once they become system constraints, the phone starts moving toward Agent OS.
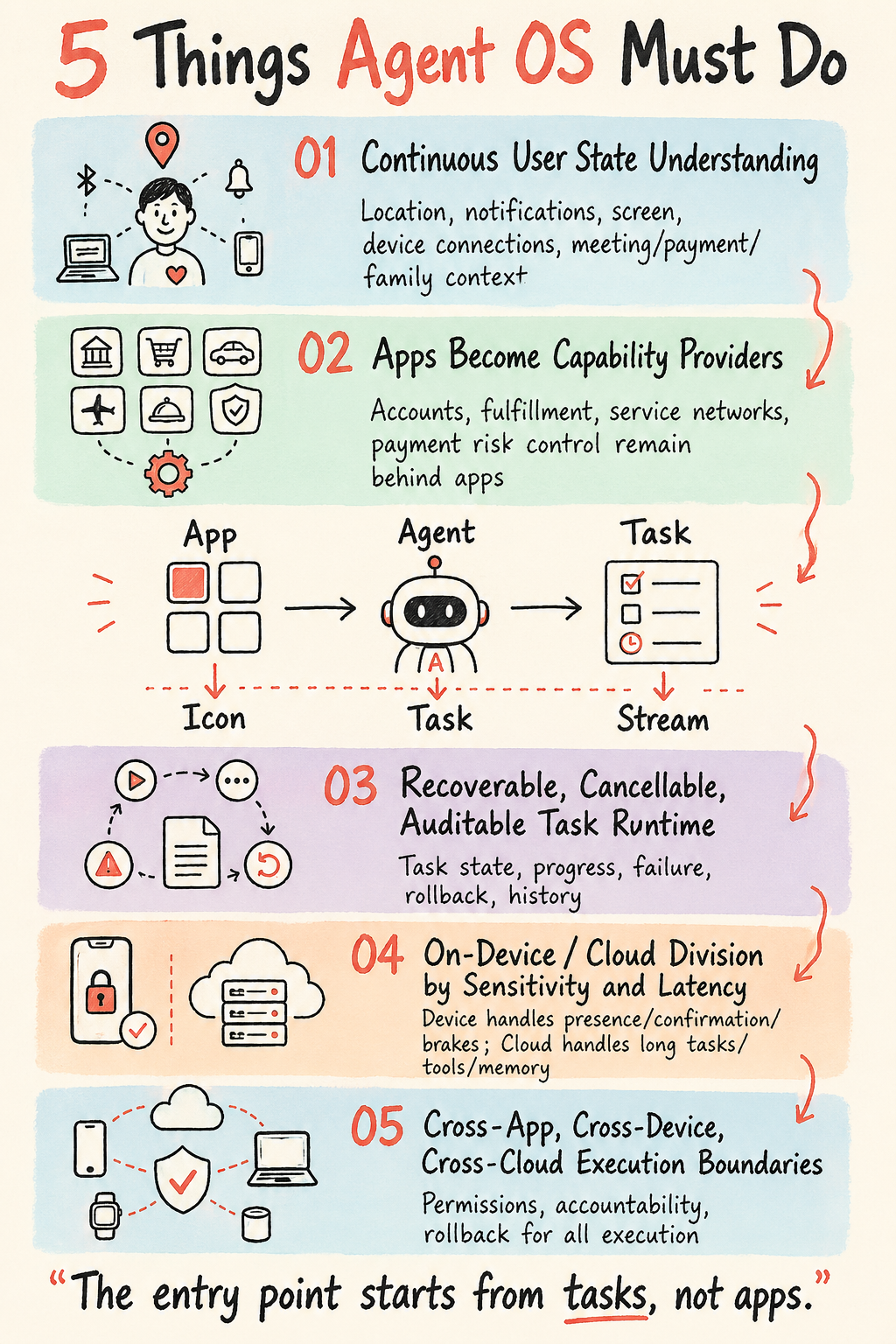
Table of Contents
The article follows six major questions.
The starting point: OpenAI’s phone does not change hardware first. We first separate several possible OS paths for an OpenAI phone, then explain why the phone is still the Agent’s state center.
Entry migration: from app grid to task stream. Apps will not disappear, but their entry role will be downgraded. The real change lands on OS objects such as Task, Capability, Context, Artifact, Grant, and Audit.
The Android path: from super app to system service. Android will not be rebuilt from scratch in the short term. Agent OS is more likely to grow out of system services, A2A, AppFunctions, GUI Agents, and a Capability Router.
OpenAI’s fork: Android-based or not Android-based. A non-Android route is cleaner, but it must rebuild apps, identity, payment, service networks, and responsibility boundaries. The Android route is faster, but easier to drag back into the old app model.
Device-cloud, hardware, industry, and timeline. Device-cloud division of labor, data classification, on-device models, SoCs, five groups of players, the supply chain, and the 2026-2032 timeline will decide whether Agent phones can move from demos into daily use.
Product shape, market split, and responsibility distribution. Finally we return to the first screen, the China market, developer relations, responsibility distribution, and what Android practitioners should watch.
1. The Starting Point: OpenAI’s Phone Does Not Change Hardware First
Kuo’s report points to several concrete directions: OpenAI is working with MediaTek and Qualcomm on phone processors; Luxshare handles assembly and system integration; hardware co-design may be involved; specifications and suppliers may converge by late 2026 or Q1 2027; the target is mass production in 2028.
If this is understood only as “OpenAI wants to build an iPhone competitor,” the analysis will go off track. Phone hardware is already a mature industry. OpenAI’s hard part is rarely bill of materials, cameras, industrial design, or finding a contract manufacturer. The hard question is: why would users hand their primary device to an AI company that has no app distribution power, no local-life service network, no payment network, no carrier channel, and no long-term phone support experience?
The answer cannot simply be “a stronger model.” A phone is not a benchmark device for models. Users handle identity, money, work, social relationships, transportation, health, family, and content consumption on phones every day. OpenAI’s opportunity is on the other side: bypass the fight for dwell time inside each app, and compete directly for task interpretation and task execution.
But “building a phone” can mean four different choices.
The first choice is standard Android. OpenAI can take the AOSP/GMS stack, deeply customize Launcher, SystemUI, permissions, notifications, and the default assistant, keep Android app compatibility, and make the Agent a system-level entry point. This is the fastest path, and it looks most like a phone. The risk is limited control. Android’s security model, background restrictions, app permissions, Play policies, and OEM customization boundaries will all limit how far OpenAI can rewrite the user experience in one step.
The second choice is a deep AOSP fork. It still runs Android apps, but OpenAI defines the framework, default entry point, capability registration, task management, and cloud sync. Overseas, it can negotiate Google services. In China, it would almost need to build a separate service system. This path is feasible in engineering terms, but commercially difficult. Android app compatibility touches APKs, Google Play, push, maps, payment, accounts, subscriptions, anti-cheat, and vendor certification.
The third choice is “Android compatibility layer plus self-built Agent OS.” The bottom layer may still be Linux. The foreground is a task-flow system. Android apps run inside an isolated container or compatibility environment, similar to how desktop systems have run mobile apps before. OpenAI gets more design freedom in this system. It can treat apps as capability containers and weaken their UI as the main subject. The cost is higher compatibility work, power consumption, background limitations, and resistance from app vendors.
The fourth choice is a new OS that is not based on Android at all, and the first-generation device may not even be a traditional phone. OpenAI’s earlier hardware direction with Jony Ive’s team has often been understood as a more AI-native device. That does not conflict with Kuo’s phone report. OpenAI can first build a portable device with a weaker screen, stronger conversation, and heavier cloud execution, or build a phone-shaped device that does not aim for full app compatibility. It is cleaner, but it is hard to become the user’s primary phone.
My leaning is this: if the goal is 2028 mass production and high-end replacement demand, OpenAI probably will not completely abandon the Android ecosystem. The more realistic path is an AOSP or Android-compatible branch, plus a heavily customized Agent OS foreground. But this is a probability judgment, not an assumption. The following sections first analyze the Android route, then the non-Android route.
Before route analysis, one concept should be separated: OpenAI may not want to “make an Android phone.” It is more likely trying to build a task entry point that makes Android and iOS feel old. If users accept that entry point, first-generation hardware sales should not be the only metric. It will force every phone vendor to answer the same question:
Why should users still search through dozens of icons instead of seeing tasks that are happening, waiting for confirmation, already done, or ready to resume?
Why the Phone Is Still the Agent’s State Center
The view that “the Agent can just live in the cloud” sees reasoning capability but misses the phone’s position in user life. Cloud models are larger, tools are richer, and costs can be centrally optimized, but the cloud lacks the user’s current state.
Completing tasks depends on language understanding, but also on the user’s immediate state. State is broader than a prompt plus static data such as contacts, calendar, and photos. It points to what is happening now, and how far the user is willing to let the system act on their behalf.
The phone is exactly the device with the most complete version of that state.
It knows where the user is, what they are looking at, what notification just arrived, which app was opened a minute ago, whether Bluetooth earbuds are connected, whether the watch detected activity, whether the screen is locked, whether payment credentials are available, whether the user just entered an airport, whether the car is parked nearby, how long until the next meeting, and whether family members are in the same location-sharing circle.
The cloud does not naturally get this state. It can have long-term memory, knowledge bases, browsers, code sandboxes, and powerful models, but it cannot see the scene in the user’s hand. It does not know whether the user can speak right now, which button on the current screen can be tapped, or whether biometric confirmation can be completed. If the cloud wants to behave as if it is present, it must get live state through the phone.
This is why OpenAI building a phone makes sense. However strong the ChatGPT app becomes, it is still an app: it appears when opened and leaves when closed. It has no system notification entry, no default right to confirm payments, no continuous semantic access to camera and screen, no cross-app task state, and no long-term permission to manage device state.
The boundary between an Agent phone and an AI app is here.
An AI app waits for the user to open it. An Agent phone observes events at the system layer, organizes tasks, waits for the right time, requests authorization, executes actions, and records results. The former is a very capable tool. The latter is a system-constrained agent.
Ordinary users will not describe it this way, but their behavior will push this change. When someone says, “Book my flight and hotel to Tokyo next Wednesday, keep it under 8,000, avoid red-eye flights, and send the itinerary to my colleagues,” the goal is to have a task decomposed, compared, confirmed, paid for, synced, and tracked. The goal is not to switch among Trip.com, Fliggy, maps, calendar, WeChat, email, and the company expense system.
When a parent says, “Check the class group and tell me what materials my child needs to submit this week,” the goal is to produce an executable checklist from group messages, the school mini-program, photos, calendar, and to-dos, then remind before the deadline. The goal is not to open WeChat and scan 200 messages, or ask a model to summarize a chat.
When a creator says, “Turn today’s footage into three short videos for Douyin, Xiaohongshu, and Channels,” they are not asking to open Jianying and tap buttons. They want material understanding, platform specs, copywriting, style selection, copyright checks, publishing plans, and metrics review.
None of these are single-app problems. They span apps, accounts, devices, cloud tools, and real-world fulfillment. The phone is the entry point because it holds state. The cloud is the amplifier because it carries long tasks. Apps are capability sources because services still sit behind apps.
So App -> Agent means the app’s foreground status declines while its capability status rises. The app itself still exists.
2. Entry Migration: From App Grid to Task Stream
Many Agent OS discussions speak too absolutely: Agents will replace apps. That judgment is too crude.
As described above, apps will not disappear. The reason is simple: apps carry account systems, business relationships, payment risk control, content rights, private-domain relationships, membership benefits, customer support responsibility, and regulatory obligations. An Agent can operate a food-delivery app for the user, but restaurant supply, delivery networks, after-sales rules, coupons, invoices, and food safety responsibility still sit with the platform. An Agent can help book a hotel, but inventory, price, cancellation policy, and credit guarantees still sit with OTAs and hotel groups.
The change happens at the entry layer.
The old phone is an app icon grid: users pick an app first, then find the function inside the app. That model fits the era of humans actively operating software. The foreground of Agent OS is more like a task stream: users express goals first, and the system chooses capabilities. Apps move from “destination” to “capability source.” Users may not know which app was finally called, but the system must know, explain, authorize, audit, and assign responsibility.
Kuo’s concept image compresses this into three lines:
- App -> Agent
- Icon -> Task
- Grid -> Stream
These three lines work as product direction, but engineering must separate them.
App -> Agent is not about wrapping every app in a chat UI. An Agent needs to understand the capabilities an app exposes, input constraints, output format, execution risk, and charging rules. For Android, this corresponds to a combination of AppFunctions, Intent, ContentProvider, ShareSheet, Shortcut including App Shortcuts and Sharing Shortcuts, Notification Action, Credential Manager, Wallet/Payment SDKs, web APIs, and vendor-private interfaces. Slice has been marked deprecated by Google, so it should not be included in new designs.
Icon -> Task is not about replacing app icons with task cards. Tasks need a state machine: created, planned, waiting for authorization, running, waiting for external response, failed, canceled, completed, rolled back. They also need Artifacts: tickets, orders, documents, calendar events, images, invoices, meeting notes, routes, code diffs. Users should not only see a spinning chat bubble.
Grid -> Stream is not about making the home screen an information feed. A task stream must be controllable, collapsible, mutable, pausable, and traceable. Otherwise it becomes an even noisier notification center. An Agent that can appear proactively will be turned off quickly if it has no budget or restraint.
The mobile OS change hides behind these three conversions.
In the past, the OS managed processes, windows, permissions, and notifications. Agent OS must also manage tasks, context, capabilities, memory, and responsibility. Apps can continue to exist, but the first interface users face each day may no longer be a display case of apps. It may become a workbench of tasks.
The OS Object Model Behind One Task
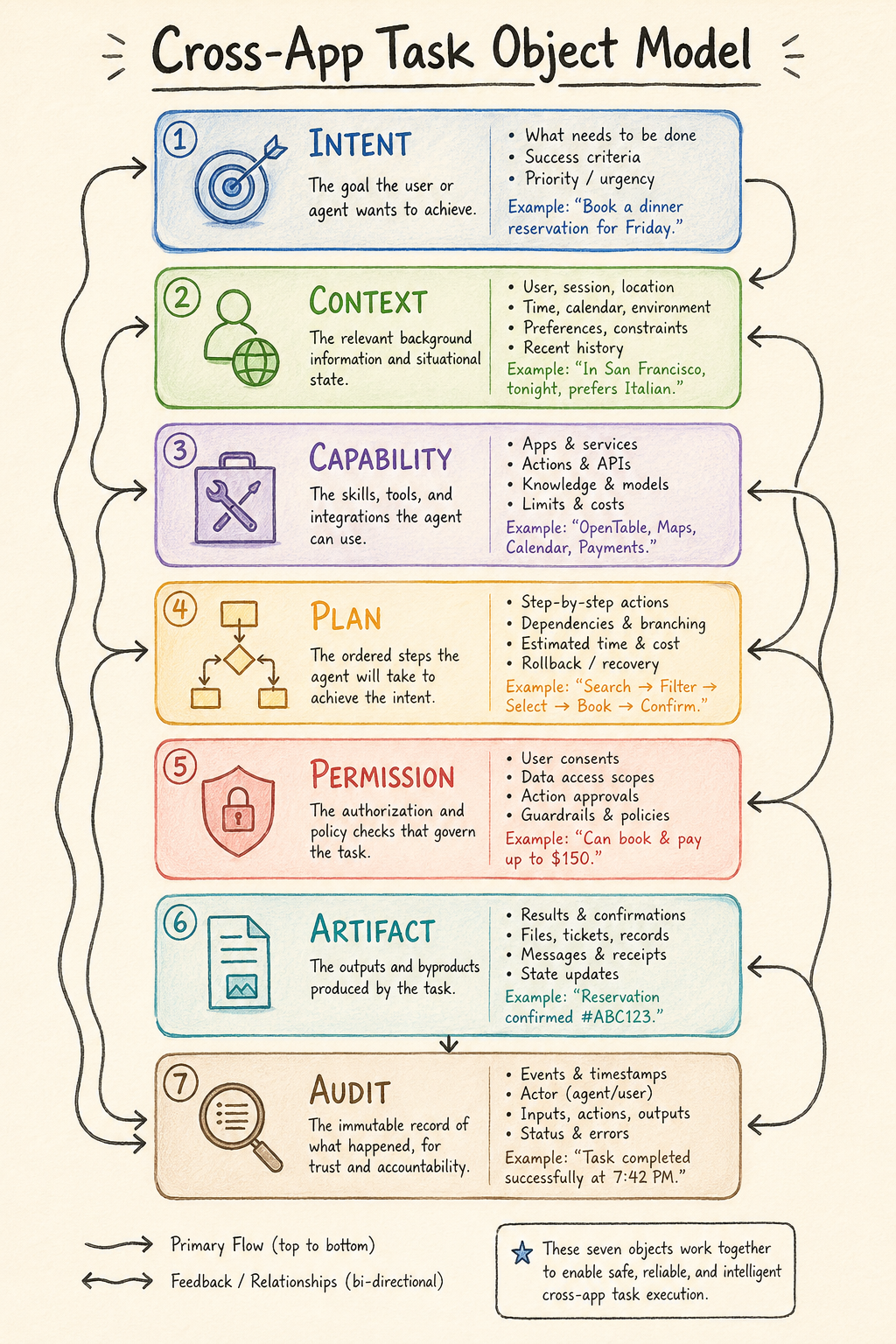
If we only say App -> Agent, it quickly becomes an abstract judgment. In Android engineering language, a cross-app task must be split into at least the following objects.
The first object is Intent. Here it means the user’s goal, not Android Intent. It can come from voice, text, screenshot, camera, notification, clipboard, or an external device. If the user says “help me reimburse this invoice,” the system cannot just throw the sentence to a model. It must first identify the task type, involved apps, required accounts, possible credentials, company policy, network needs, and whether the user must be present to confirm.
The second object is Context. Here it means the minimum scene information required by the task, not Activity Context. A reimbursement task may need the invoice image, the approval entry in WeCom or Feishu, company reimbursement rules, invoice title, user identity, and the last template used for a similar reimbursement. The system must trim this information to what is sufficient for the task, without handing the whole album, whole chat history, or all company documents to the cloud.
The third object is Capability. The system must know what capabilities can finish the task: OCR, invoice verification, the enterprise app’s reimbursement AppFunction, browser form filling, company intranet API, file upload, and message notification. Each capability has a source, permission, cost, reliability, execution duration, and risk level.
The fourth object is Plan. The Agent will break the task into steps, but the plan should not live only inside model context. It should be recorded by the system as an inspectable structure: read invoice, extract fields, verify authenticity, open reimbursement entry, fill form, upload attachment, wait for user confirmation, submit, save receipt. Then the user, system, and developer can know where the task is.
The fifth object is Permission Grant. Traditional app permission asks “can this app access the camera?” Agent permission asks “can this reimbursement task read these three photos, access this company reimbursement entry, submit the form, and must submission be confirmed first?” It is shorter, finer-grained, and more dependent on task state than app permission.
The sixth object is Artifact. Task outputs include reimbursement drafts, submission receipts, invoice fields, approval numbers, failure screenshots, and operation logs, not just an answer sentence. These Artifacts must enter history and be available to later tasks.
The seventh object is Audit. What the Agent did, whom it called, which data it used, which step the user confirmed, which step was automatic, and where failure happened must all be traceable. Without Audit, once the Agent makes a mistake, neither users nor vendors can determine responsibility.
This object model relates to existing Android objects, but cannot be fully reused.
Activity is for UI. Service is for background execution. Broadcast is for event distribution. ContentProvider is for structured data. Intent is for component invocation. They solve how apps cooperate with each other. They do not solve how a cross-app goal keeps running, waits for user confirmation, migrates between cloud and device, or recovers after failure.
Agent OS needs to add task objects above these traditional objects, wrapping Activity and Service in a higher-level task semantics.
One way to understand the relationship is:
1 | Old Android objects: |
This is also why Agent OS cannot be done by an independent app. A third-party app can maintain its own Tasks, but it has no authority to unify all apps’ capabilities, permissions, context, and audit records. Only the system layer can do that.
The Relationship Between Task Stream and Notification Center
The first thing the system layer must do is organize fragmented events into tasks. This is also the part most easily confused with the notification center.
Many vendors will start from notification center changes because notifications are natural entries for “something happened.” Directions such as Samsung Now Brief and Now Bar have value for exactly this reason. They try to reorganize fragmented events into “things the user needs to handle today,” and their value comes from reorganizing events into tasks.
But a task stream cannot simply equal a notification center.
A notification is an event an app sends to the user. A task is a goal the user or system needs to complete. Notifications can trigger tasks, and tasks can generate notifications, but they are not the same object.
For example, an airline app pushes “flight delayed by two hours.” That is a notification. After Agent OS receives it, it can generate a task: “Should pickup time, hotel check-in, meeting schedule, and colleague notification be adjusted?” This task reads calendar, maps, hotel orders, chat contacts, and company meeting arrangements, then asks the user to confirm. The notification is only the starting point. The task is the object the system must manage.
Another example: a school group sends 20 messages, and only one is about materials due tomorrow. A traditional notification center can only show app pushes. An AI summary can summarize the chat. Agent OS must go further and generate a task: “Print and fill the form before 9 p.m. tonight, and take it to school tomorrow morning.” It needs to connect files, printer, calendar, reminders, and family members.
So a task stream is more like a lightweight project manager. Its objects are life and work to-dos, not a notification list.
This brings a product constraint: the task stream must be restrained. A phone that proactively creates 30 tasks a day will be disabled quickly. The system needs reminder budgets, interruption levels, quiet hours, family/work modes, and user feedback. The difficulty of a task stream is filtering out tasks that should not appear.
3. The Android Path: From Super App to System Service
Android has natural advantages for Agent OS, and obvious burdens.
The advantages are openness, modifiability, broad hardware coverage, OEM access to system permissions, and many reusable framework components. Binder fits high-frequency IPC on the same device. PackageManager fits capability registration. PermissionController fits authorization. ActivityTaskManager and WindowManager fit foreground/background state. NotificationManager fits long-task visibility. AppSearch fits local indexing. Keystore and StrongBox fit credential protection. JobScheduler fits long-task scheduling. ContentProvider fits structured data access.
The burdens are fragmentation, historical permission baggage, the split between Google services and AOSP, too many vendor-private interfaces, complex background restrictions, and top apps’ natural suspicion toward automation. An Android Agent that wants to move from “can tap the screen” to “can reliably finish tasks” must cross three technical paths.
The first path is GUI Agent. It uses screenshots, accessibility, input injection, Virtual Display, UI hierarchy, OCR/VLM, and similar methods to simulate a human operating apps. The advantage is that it covers long-tail apps without developer cooperation. The shortcomings are also obvious: it is slow, vulnerable to UI changes, and easily touches security boundaries. Payment, social, banking, and gaming platforms will naturally guard against it.
The Doubao phone pushed this path onto real devices. It showed the industry both usability and boundaries. System-level permissions, Virtual Display, on-device visual understanding, and cloud OpenClaw/ArkClaw together can complete many cross-app actions. But third-party app restrictions also show that “tapping the screen like a human” cannot support the long-term main path.
The second path is structured capability. Android AppFunctions, Apple App Intents, vendor SDKs, MCP tools, and private APIs all fall into this category. It requires apps to actively declare “what I can do,” and provide parameters, permissions, return values, and risk levels. The advantage is stability, speed, and auditability. It fits operations such as payment, sending messages, creating calendar events, generating documents, and submitting orders. The drawback is developer cooperation, and top apps will not easily give up foreground entry.
The third path is Agent protocol. A2A solves how Agents discover each other, delegate tasks, pass messages, and deliver Artifacts. MCP solves how Agents use tools and data sources. On phones, they will not replace Android IPC, but coexist at different layers. On the same device, Binder is a better fit. Across devices and the cloud, network protocols fit better.
A more reasonable short-term Android structure looks like a router:
1 | User goal |
This is also the mistake Android vendors should avoid in the short term: turning Agent OS into a super app with all permissions. A super app can make demos, but it cannot support a system architecture. The scalable long-term approach is to split the Agent into system services, capability declarations, task state machines, data classification, and user-visible control.
Where Existing Android Components Can Migrate
Android does not start from zero. From a platform engineering perspective, many Agent OS parts can migrate from existing system abstractions.
PackageManager can continue discovering installed apps, but it needs to extend capability indexing. In the past, PackageManager cared about Activity, Service, Receiver, Provider, Permission, and Feature. Agent OS also needs to know which AppFunctions an app declares, whether it provides an AgentCard, which schemas the system can call, which capabilities need human confirmation, and which capabilities can only be used under enterprise policy.
PermissionController can continue handling authorization UI and permission records, but it needs task-level grants. Traditional permission is often “allow this app to access the camera.” Agent permission is more like “allow this task to read these three images and upload them to this service, but show a preview before upload.” This kind of grant should not be permanently attached to an app. It should bind to Task, Step, and Artifact.
ActivityTaskManager can continue providing foreground/background state, task stacks, and window information, but Agent OS needs usable semantic snapshots, not raw copying of the user’s current screen. The system should expose structured summaries: current app, page type, actionable elements, sensitive regions, whether the user is typing, and whether a payment, verification code, or privacy screen is visible. Exposing raw screen content to the cloud brings high risk.
NotificationManager can become the natural outlet for task state. A long task should not stay only inside an assistant app. It should enter system notifications, lock screen, watch, and car. But notifications also need to upgrade: not just title and body, but state, progress, next action, risk prompt, pause/cancel/confirm buttons.
AppSearch can become part of local semantic indexing. The device needs to quickly find notes, files, calendar events, contacts, historical tasks, common places, and user preferences. AppSearch fits local indexing, but sensitive data must be split by policy. The system cannot dump everything into an index that an Agent can read freely.
ContentProvider remains the base for structured data access, but its permission model needs to be finer. An app may allow the Agent to read one order status, but not the full order history. It may allow reading an attachment in one chat, but not the whole chat context.
Keystore, StrongBox, TEE, and secure elements become more important. On an Agent phone, credentials, payments, Passkeys, enterprise certificates, private memory, and sensitive vector indexes all need hardware-level protection. The Agent can prepare actions, but final signing and confirmation should happen inside a security boundary.
JobScheduler, WorkManager, AlarmManager, and push can support long-task scheduling, but Agent tasks are more complex than ordinary background tasks. A task may run in the cloud while the device only waits for callbacks. It may execute halfway on device, lose network, and resume later. It may migrate across devices. The system needs to connect task state with the scheduling system.
RoleManager and default assistant roles will become key entry-point battlegrounds. Android has used RoleManager to manage default dialer, SMS, browser, assistant, and similar roles; input method uses a separate InputMethodManager path. Agent OS may need “default Agent,” “default task manager,” and “default capability router.” This will create a new contest among platform, OEM, and third-party assistants.
Put these components together and Android can take a pragmatic short-term evolution path:
1 | SystemUI / Launcher |
This structure does not require Android to be rebuilt immediately. It is more like adding a set of high-privilege system services to the current Android stack, then gradually opening developer interfaces. OEMs will likely implement it privately in the short term. Only later might AOSP, GMS, or industry protocols absorb it.
The Right Position for A2A on Android
A2A deserves a separate explanation because it is not just another “tool-calling” protocol.
A2A stands for Agent2Agent. It was launched by Google with 50+ partners in April 2025 and transferred to Linux Foundation governance in June 2025. Its official positioning is clear: allow Agents from different vendors, frameworks, and runtime environments to discover each other, delegate tasks, exchange progress, and deliver results.
Its design assumption is that Agents are black boxes to each other. A travel Agent does not need to know which model, prompt, tool, or database a reimbursement Agent uses internally. It only needs to know what the other side can do, how to authenticate, how to submit a task, what state the task is in, and what result will be returned.
This differs from MCP. MCP solves how an Agent calls tools, resources, and data sources. For example, an Agent uses MCP to access the filesystem, database, browser, Jira, or Feishu docs. A2A solves how an Agent calls another Agent. The former is more like a tool socket. The latter is more like a task delegation language.
This distinction is useful on phones.
If the user says, “Plan my Tokyo trip next month, keep it under 8,000, avoid red-eye flights, and send the itinerary to my colleagues,” the phone-side system Agent can read calendar, location, payment-confirmation state, and contacts. But it does not have to do everything itself. It can delegate flight and hotel comparison to a travel Agent, visa material checking to a document Agent, company travel rules to an enterprise Agent, and leave final confirmation and payment on the phone.
If every Agent has a private interface, this quickly becomes unmanageable. A2A tries to provide a common vocabulary.
The first term is AgentCard. It is the Agent’s capability card: who I am, what I can do, which inputs and outputs I support, what authentication I need, whether I support streaming, and whether I support push after task completion. On Android, it resembles a Manifest for Agents. An app or system service can declare “I have a travel Agent,” “I have an image-editing Agent,” or “I have an enterprise reimbursement Agent.” The system indexes these cards.
The second term is Task. A2A Task is a stateful work unit, not a single API request. It can be submitted, working, input-required, auth-required, completed, canceled, failed, rejected, unknown, and so on. This fits phones because real tasks often span time: ticket booking waits for price, food delivery waits for rider, approval waits for manager, video export waits for processing, reimbursement waits for submission. Users need to see task state, not just a model reply.
The third set of terms is Message / Part / Artifact. Message is a conversation turn in the task process. Part can be text, file, or structured data. Artifact is the deliverable. Phone Agents need to pass images, PDFs, spreadsheets, orders, calendar events, location, credential references, and operation results. Artifact is especially suitable for Agent OS because task results must be saved, shared, audited, and referenced later. A travel task’s Artifacts can include itinerary, hotel candidate table, budget table, calendar events, and payment confirmation record.
The fourth capability is Streaming and Push. Many phone tasks do not finish in seconds. Users cannot stare at a chat window while a cloud Agent completes research, comparison, approval, or video processing. A2A’s streaming updates and asynchronous callback semantics fit the pushback of “task started,” “more information needed,” “authorization needed,” “completed,” or “failed reason” to phone notifications, lock screen, and task stream.
So A2A’s value for Agent OS is not that it adds one more network protocol. Its value is standardizing several of the hardest objects in Agent collaboration: who can do what, what state the task is in, how the process communicates, and how results are delivered.
But A2A should not be inflated into the whole answer for Android Agent OS.
First, A2A is natively aimed at cross-system, cross-network, cross-vendor Agent communication. It fits a phone-side Agent calling cloud OpenClaw, ChatGPT Agent, enterprise Agent, car Agent, or home Agent, and it fits Agent delegation between companies.
Second, on the same Android device, A2A semantics are worth borrowing, but the transport layer should not simply copy HTTP/JSON-RPC. Android’s local IPC path is Binder. Making local Agents go through loopback HTTP every time adds latency and bypasses existing UID, SELinux, permission, lifecycle, and other security models. A better direction is A2A over Binder: keep AgentCard, Task, Message, Artifact semantics, but use Binder for transport, with permissions and audit handled by system services.
Third, A2A needs a division of labor with AppFunctions. AppFunctions are structured functions for a system Agent to call local apps, such as createNote(title, content), searchPhotos(query), and sendMessage(contact, text). A2A is for one Agent delegating a task to another Agent, such as “organize this batch of photos into a travel album” or “handle reimbursement according to company rules,” where autonomy, follow-up questions, and long execution are needed.
A more reasonable Android stack looks like this:
1 | User goal |
Fourth, A2A still lacks pieces a phone OS must supply. It can describe Task state, but it does not own Android permission UI. It supports async callbacks, but does not guarantee strict event replay across all implementations. It can pass Artifacts, but it does not define data classification, device-cloud boundary, payment confirmation, or failure rollback for the system. Agent OS must add Policy, Consent, Audit, Retry, Idempotency, and user-visible control above A2A.
Therefore the better position for A2A on Android is this: it does not replace Binder, AppFunctions, or the permission system. It should become the public semantic layer for Agent collaboration. Android’s job is to translate that semantics into its own system services, IPC, task stream, and permission model.
The Three Technical Routes Will Coexist for a Long Time
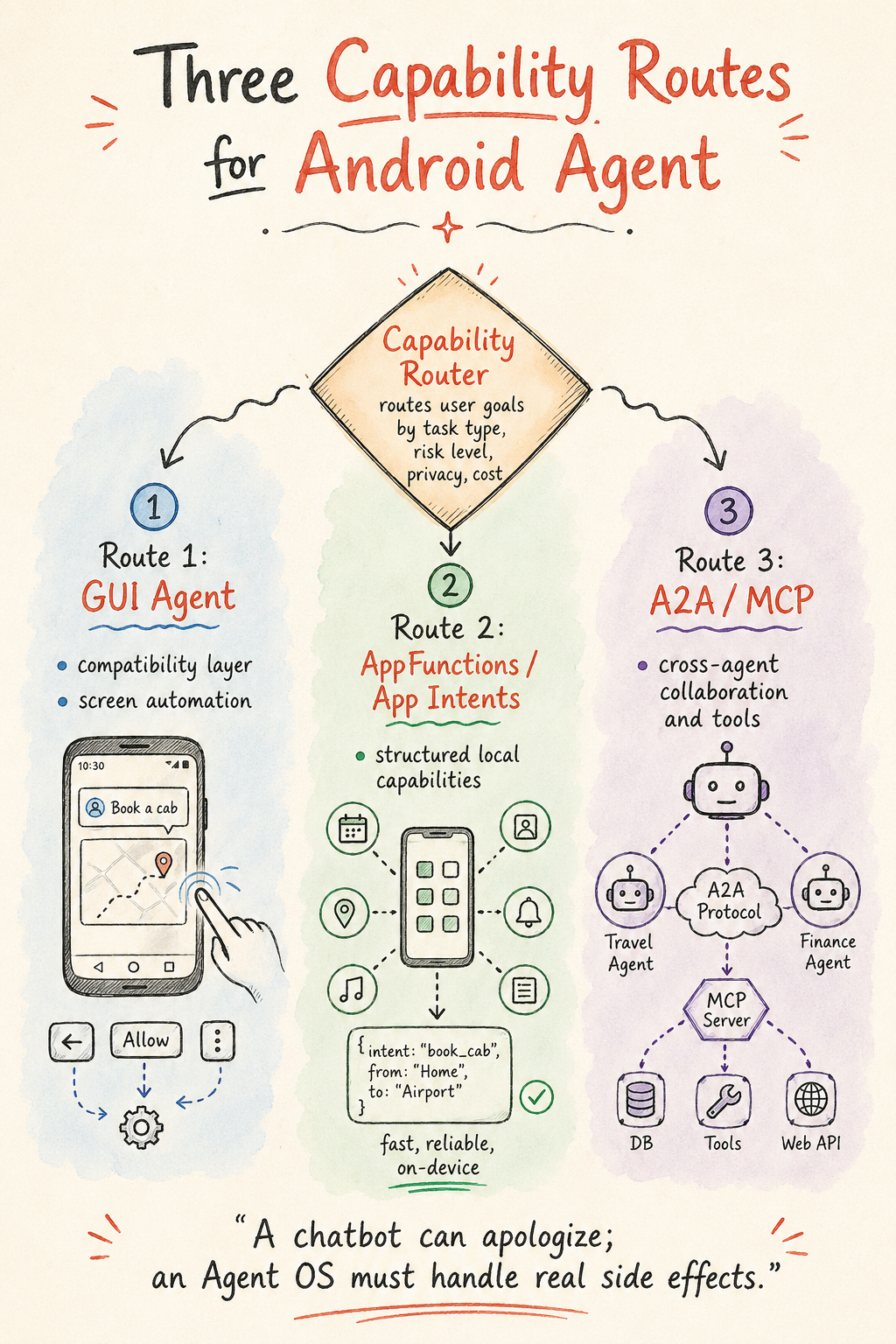
After separating GUI Agent, AppFunctions, and A2A, the conclusion is clear: all three will coexist for a long time, but they occupy different positions.
GUI Agent is the compatibility layer. It solves the problem of “developers have not cooperated, the app exposes no capability, and the user wants the task done now.” It fits long-tail apps, transition periods, and low-risk operations visible to the user. It should not be the default path for high-risk actions such as payment, messaging, settings changes, data deletion, or ordering.
AppFunctions / App Intents are the local capability layer. They let apps tell the system in a structured way: I can create notes, send messages, create events, search products, submit orders, generate images, or export videos. They need developer cooperation, but once scaled, they are more reliable, faster, and safer than GUI Agent.
A2A / MCP are the collaboration and tool layer. MCP targets tools and data sources. A2A targets discovery, delegation, and delivery among Agents. A phone-side Agent needs similar protocols to coordinate with cloud Agents, car Agents, computer Agents, and enterprise Agents. Protocols will not replace local APIs, but they make cross-device and cross-cloud tasks describable.
These three paths need a Capability Router. The user only expresses a goal. The system decides which path to use based on task type, risk level, available capabilities, network state, privacy level, and cost.
For example, “make this photo a little brighter” can be handled by an on-device model.
“Turn today’s meeting recording into minutes and send it to a Feishu group” should prefer transcription, documents, Feishu API or AppFunction, then ask the user to confirm sending.
“Compare three family trip routes for summer vacation, keep it under 20,000, and consider that the elderly cannot walk too much” can run long cloud queries and comparisons, while the phone syncs family calendar, location preferences, payment confirmation, and final choice.
“Cancel a subscription that is about to renew” is best if the app exposes structured capability. If not, GUI Agent can operate the settings page or webpage. When payment and account changes are involved, user confirmation is required.
This is why Agent OS is harder than an assistant app. An assistant app only needs to be a model entry point and apologize after failure. Once Agent OS promises execution, it faces real-world side effects. It cannot only be smart; it must be controllable, explainable, and recoverable.
Short-term Android Agent OS Architecture: System Services Are the Main Battlefield
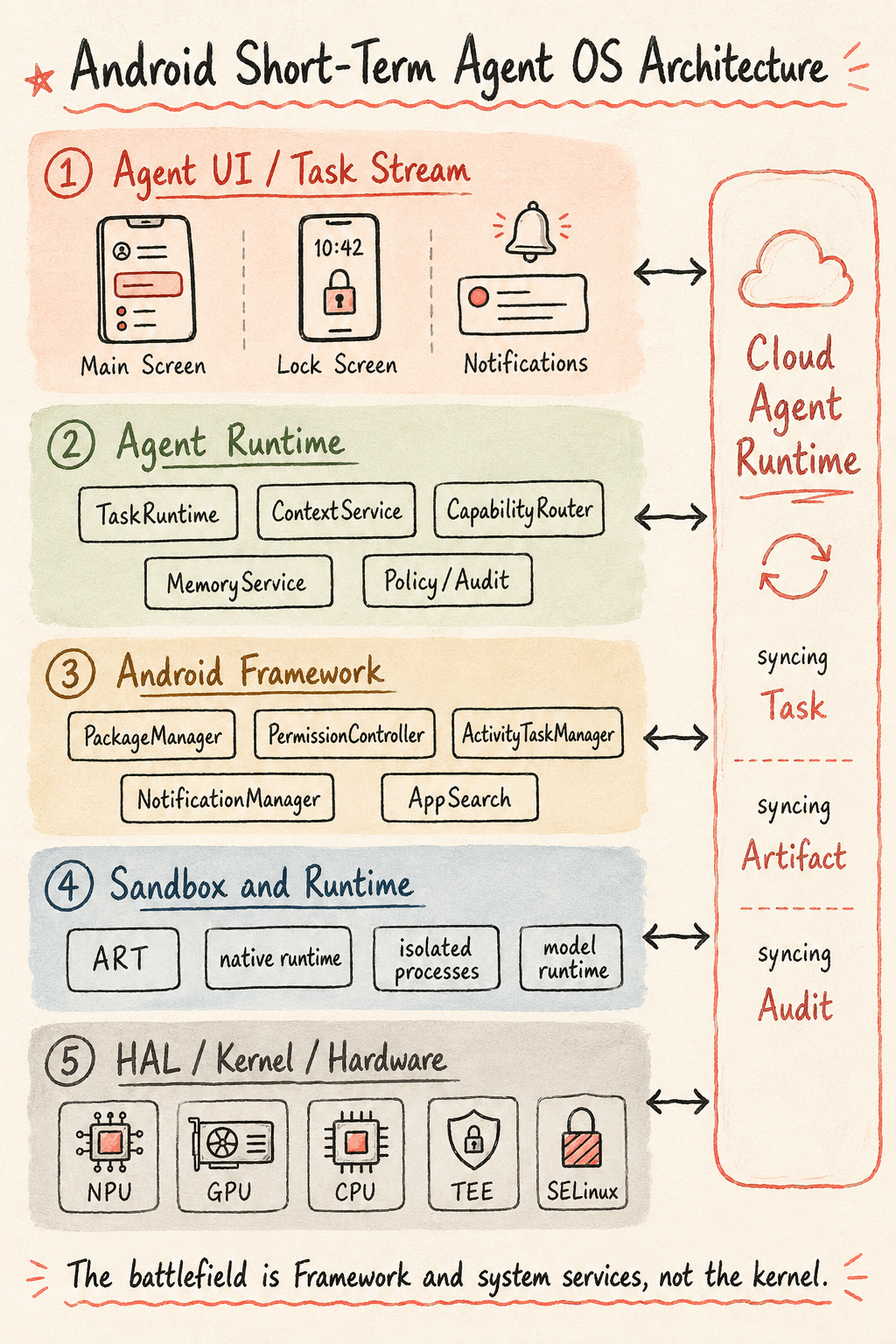
After the three Android paths, we can converge them into one system architecture.
This structure should not be treated as the final Agent OS architecture. It is more like a pragmatic Android evolution path from 2026 to 2028: keep Android and the kernel mainline, and add a group of Task-centered system services across SystemUI, Framework, permissions, notifications, on-device model runtime, and cloud Agent Runtime.
The architecture is easy to read.
The first layer is Agent UI / Task Stream. Users see task state: running, waiting for confirmation, completed, failed, recoverable. They do not see model calls. Home screen, lock screen, notifications, floating entry points, and multi-device handoff become different outlets for task state.
The second layer is Agent Runtime. This is the semantic layer Android lacks most in the short term. TaskRuntime manages the state machine, Artifacts, cancellation, recovery, and rollback. ContextService provides minimized scene snapshots. CapabilityRouter routes among AppFunctions, A2A, MCP, and GUI Agent. MemoryService manages short context, long-term preferences, and deletable memory. Policy / Consent / Audit handles authorization, consent, risk classification, and responsibility records.
The third layer is Android Framework. Android does not need to write an OS from scratch. PackageManager, PermissionController, ActivityTaskManager, NotificationManager, AppSearch, ContentProvider, Credential, Keystore, StrongBox, JobScheduler, and RoleManager can all continue to work. The change is that these old objects are wrapped by a higher-level Task semantics.
The fourth layer is Sandbox & Runtime. ART still runs Java/Kotlin apps. Native runtime still handles high-performance execution. Isolated process, Privacy Sandbox SDK Runtime, Microdroid, or similar virtualization capabilities can carry stronger isolation. On-device model runtime, embedding, VLM preprocessing, and GUI automation sandbox should also be scheduled at this layer.
The fifth layer is HAL / Kernel / Hardware. It provides NPU/GPU/CPU, memory tiers, low-power sensor hub, TEE/SE, Binder, SELinux, cgroup, seccomp, mmap CoW, TEE drivers, and other resource and security foundations. The kernel should not carry Agent task semantics. It should be responsible for resources, security, isolation, and performance.
On the right is Cloud Agent Runtime. An Agent phone must be a device-cloud organism. The cloud handles long-task sandboxing, browser, code tools, document tools, long-term memory, A2A gateway, push callbacks, and data policy. The device handles live context, privacy, confirmation, and braking. What synchronizes between them is Task, Artifact, authorization, audit, and state, not an unbounded chat transcript.
This structure contains several key choices.
First, put Task Runtime in a first-class position. The foreground of Agent OS is the task stream; the chat box is only one entry point. The system must manage task state, Artifacts, progress, failure, cancellation, rollback, and history. Without Task Runtime, Agent OS easily falls back into “assistant app plus notification.”
Second, separate Policy / Consent / Audit from Access manager. Agent operation on a phone is not ordinary permission asking. It needs to answer: is this task allowed, does this step require confirmation, is the result traceable, can the user revoke it, and who is responsible? Payment, messaging, file deletion, order submission, and external publishing all need audit and consent. The permission system can answer “can it access,” but cannot fully answer “should it execute.”
Third, distinguish Android, GMS, and vendor-built capabilities. AICore is Google’s system-app-based on-device foundation model service for Pixel and partner OEMs, hosting Gemini Nano. It is not part of AOSP, and Chinese ROMs do not naturally have it. Also note that Apple Private Cloud Compute (PCC) and Android Private Compute Core (also abbreviated PCC, hosted by Android System Intelligence) are different systems. They should not be conflated. Chinese vendors are more likely to replace them with self-built model services and local compliance clouds.
Fourth, do not describe ART as Agent Runtime. ART will continue to handle app execution, JIT/AOT, profile optimization, and part of the process model. Agent Runtime is unlikely to evolve directly from ART. A more likely structure is Agent Runtime as system services and sandbox runtime, built above ART, native runtime, isolatedProcess, SDK Runtime, and Microdroid/virtualization capabilities.
Fifth, split Memory. Agent “memory” has at least four types: current context snapshot, long-term user preferences, intermediate task state, and model KV/cache plus embedding indexes. Their security level, lifecycle, storage location, and deletion mechanism are different. Calling all of them Semantic memory hides engineering boundaries.
The basic judgment for short-term Android Agent OS is that the main battlefield is not the kernel, not Launcher alone, and not a single super-assistant app. It is between Framework/SystemUI/privileged services and cloud Agent Runtime.
At the Engineering-Service Level, at Least Four Groups Are Needed
If this architecture is further decomposed into Android engineering services, the Framework layer needs at least four groups.
The first group is Task services:
1 | TaskManagerService |
TaskManagerService creates, resumes, cancels, and schedules tasks. TaskStateStore saves task state and steps. ArtifactProvider manages task outputs. TaskHistoryProvider lets users and the system query history. TaskNotificationAdapter syncs tasks to notifications, lock screen, watch, and car.
This group decides whether Agent OS is more than a chat UI. Without it, the system cannot turn “help me do something” into a visible, controllable, recoverable object.
The second group is Capability services:
1 | CapabilityRegistryService |
CapabilityRegistryService aggregates all callable capabilities. AppFunctionIndexer handles Android AppFunctions. AgentCardRegistry handles local and remote Agent declarations. McpToolBridge connects tool services. GuiAutomationBroker manages temporary authorization and execution boundaries for GUI automation.
This group decides whether the system can find executable capability from a user goal. Without a unified index, the Agent can only guess with the model, and will fall back to unstable screen tapping.
The third group is Context and Memory services:
1 | ContextSnapshotService |
ContextSnapshotService provides the current scene’s minimum semantic snapshot. SemanticIndexService manages local indexes. PreferenceMemoryService saves long-term preferences. EphemeralTaskMemory saves intermediate state while tasks run. MemoryDeletionService provides visible deletion and verifiable deletion.
This group decides whether the Agent understands the user, and whether the user is willing to be understood. Once memory becomes a black box, trust drops quickly.
The fourth group is Policy and Security services:
1 | AgentPolicyService |
AgentPolicyService handles data classification and execution rules. ConsentManager manages each confirmation. AuditLogService records calls and side effects. RiskClassifier judges action risk. EnterprisePolicyAdapter connects to company MDM or compliance policy. SecureExecutionBroker places payment, credentials, signing, Passkey, and high-sensitivity actions inside a security boundary.
This group decides whether the system can take responsibility. Without it, every new Agent permission is another incident entry point.
These four service groups can coexist with macro modules such as Agent scheduler, Memory manager, Context manager, and Access manager. Macro architecture helps people understand layers. Engineering decomposition explains what services must actually be added to the system. Agent OS system services are a set of task-, capability-, context-, and policy-coordinated services. They should not be reduced to four big boxes.
Judgment on the Kernel Layer
Architecture diagrams can include wording such as “Linux kernel / Agent OS kernel support,” but the language must be careful.
Agent OS does not need an “Agent kernel” in the short term. It needs existing Linux/Android kernel capabilities to be used better: cgroup for resource control, SELinux for access constraints, seccomp for syscall restriction, Binder for local IPC, mmap CoW for sharing model weights, mmap + madvise or io_uring for on-demand weight loading, userfaultfd and similar mechanisms for ART GC and finer-grained memory management, and TEE drivers for secure hardware.
Agent semantics should not be pushed into the kernel. The kernel should answer resource, security, isolation, and performance questions. What a Task is, what an Artifact is, where user confirmation happens, and which data can go to the cloud should be handled in Framework, system services, and cloud policy.
Android vendors should make this clear early. Do not heavily modify the kernel mainline just for “Agent OS.” In the short term, the more valuable investment is System Server, HAL runtime, on-device model service, SystemUI, permission UI, and cloud protocols. Kernel optimization should serve model-weight sharing, low-power residency, sandbox isolation, and secure execution, not business semantics.
4. OpenAI’s Fork: Android-based or Not Android-based
After clarifying the Android route, we can return to OpenAI. We should not assume OpenAI must use Android.
If OpenAI does not build on Android, it gets a cleaner design space. The home screen can be a task stream from day one. Permissions can be designed around Agent tasks from day one. Apps are no longer the default center. Cloud long-term memory and subscriptions can be deeply bound. It does not have to compromise with Android history or force every function into the old Activity/Intent/Service/Broadcast model.
But it immediately faces a harder question: where do the services users need every day come from?
The difficulty of phone OS extends from kernel, UI, drivers, and system APIs into the app and service network. WeChat, WhatsApp, Instagram, TikTok, YouTube, Uber, DoorDash, Google Maps, Alipay, Meituan, banks, company MDM, carrier services, government apps, school apps, access-control apps, and medical apps are also real-life entry points.
A non-Android OpenAI phone that wants to become a primary device must choose several compensation paths.
First, use Web/PWA. Many services can be completed through the web. A cloud Agent can operate a browser, while the phone provides confirmation and credentials. But web still lags native apps in payment, notifications, offline use, performance, sensors, background execution, and local capability. Top platforms may also restrict automated access.
Second, use cloud app proxies. The Agent opens webpages, calls APIs, runs browsers, or simulates terminals in the cloud, while the phone only handles task entry and confirmation. This fits research, office work, shopping comparison, content processing, and lightweight services. It does not fit high-sensitivity payment, IM, banking, games, ride-hailing live location, or local device control.
Third, use an Android compatibility layer. The foreground is not Android, but it can run Android apps. This preserves service coverage, but the engineering difficulty and legal/commercial negotiation are heavy. App vendors may also restrict the environment through device certification, integrity checks, and risk-control strategies.
Fourth, start as a companion device. Let the OpenAI device be the task entry, voice entry, memory entry, and cloud Agent entry, while relying on the user’s existing iPhone/Android for sensitive actions. This avoids the pressure of replacing the primary device, but it raises the question: why not just use the ChatGPT app on the phone?
Fifth, target enterprise or high-end narrow scenarios. For example, an AI work phone for frequent business travelers, creators, developers, salespeople, doctors, lawyers, and researchers. It does not need to cover all consumer services immediately. If it wins high-value tasks, it can validate the Agent OS product form.
So the non-Android route is feasible, but it must accept a reality: without app compatibility, it is hard to become the first phone; with app compatibility, the old app model drags it back. If OpenAI wants a new OS, the more realistic path is to make task stream, cloud Agent, subscription, and a few high-value services work deeply first, then gradually expand callable capabilities.
From a system architecture perspective, the non-Android route still cannot avoid similar modules:
1 | Task Stream Shell |
It may not be called Android, but the underlying principles remain similar. An OS must manage identity, permissions, processes, storage, network, display, input, sensors, security, and developer interfaces. Agent OS raises “tasks” and “capability calls” to a higher priority. It does not eliminate the basics.
In other words, the Android versus non-Android difference is not “whether there is an Agent.” It is “how to carry the old world.” The Android route carries the old world through compatibility and adds task stream in the foreground. The non-Android route defines a new world through task stream, then fills old-world gaps with web, cloud, and compatibility layers.
The former is steadier. The latter is cleaner. The former is easier to evolve gradually. The latter is more likely to produce a paradigm sample. OpenAI’s advantage is exactly that it has no App Store, no Launcher, and no OEM legacy baggage, so it can dare to put task stream on the first screen. Its weakness also comes from here: it has none of that baggage, and none of those assets.
Three Prototype Forms for a Non-Android Route
If OpenAI really does not use Android, it probably will not start with a “complete phone OS.” Three prototype types are more likely.
The first is a task-terminal phone.
It has a screen, cellular network, camera, and voice entry. It may make calls and receive SMS, but the first screen is not an app grid at all. Its main interface is a ChatGPT Task Stream: pending tasks, running tasks, tasks waiting for confirmation, completed Artifacts. App compatibility depends on web, cloud browser, and a few native services. It looks like a phone, but does not try to fully copy an Android phone.
This device fits high-end users and high-value tasks: business travel, research writing, creative editing, sales follow-up, personal assistant work, developer workflows. It may not cover every life scenario, but it can establish a sample around “reducing cross-app operations.”
The second is a phone companion device.
It does not fight to be the first phone. It binds to the user’s existing iPhone or Android. It handles voice, memory, task initiation, cloud Agent, photo understanding, and lightweight confirmation. Actions involving payment, IM, banking, or company MDM still return to the primary phone for confirmation.
The advantage is lower entry cost and no need to solve app compatibility all at once. The disadvantage is the obvious user question: why not use the ChatGPT app on the phone? So it must be clearly better in always-on presence, low interruption, capture, and task continuity.
The third is an enterprise/professional device.
OpenAI can first target high-value professions with an Agent OS device: doctors checking information and writing records, lawyers organizing cases and contracts, salespeople following up customers, researchers collecting information, journalists organizing interviews, creators processing material, developers handling code tasks. These devices do not need every consumer app to be compatible. They need deep cooperation with professional tools, enterprise systems, browsers, and filesystems.
This route sounds less like a mass-market phone, but it fits the early economics of Agent OS better. How much ordinary users will pay for “opening fewer apps” is uncertain. How much professional users will pay for “saving one hour of high-value work every day” is easier to calculate.
The Cost of OpenAI Not Using Android
The cost of a non-Android route can be split into six categories.
First is app availability. Without Android/iOS native apps, many services can only use web or cloud proxies. The hardest things to replace in daily life are apps with payment, risk control, messaging, location, push, and local device capability, not webpages that a browser can open.
Second is accounts and identity. A phone is an identity container. Passkeys, SIM/eSIM, carriers, bank certificates, company MDM, government services, and family sharing all require long-term accumulation and certification. A new OS must rebuild these relationships.
Third is developer motivation. Why would developers expose capabilities to OpenAI Agent OS? For new users, revenue share, lower support costs, or because users will abandon apps that do not integrate? Before installed base exists, this is hard to answer.
Fourth is platform responsibility. When an Agent submits an order, sends a message, publishes content, or handles a bill on behalf of the user, who is responsible when something goes wrong: user, OpenAI, service app, or merchant? Traditional OS can say “the app is responsible.” Agent OS cannot cut responsibility that easily.
Fifth is supply chain and support. Phones are low-tolerance hardware products. Baseband, antenna, RF, thermal design, battery life, drop resistance, repair, spare parts, regional certification, and carrier testing are not AI-company strengths. System manufacturing partners such as Luxshare can help, but product responsibility remains with the brand.
Sixth is user migration. Users will not abandon iMessage, WeChat history, photo libraries, wallets, health data, membership benefits, and car keys just because of a new entry point. OpenAI must provide a path of coexistence first, migration later.
So the non-Android route is better suited to defining a sample than becoming the global primary phone on day one. It can prove the value of task stream and cloud Agent, then force Android and iOS to absorb that form.
If OpenAI Uses Android, What Must It Solve?
Using Android is not easy either.
First, it must decide its relationship with Google. Does it use GMS? Does it preload Play Store? How does the default assistant compete with Gemini? Can AppFunctions, AICore, and Android AI APIs be deeply used by OpenAI? Without GMS, overseas app availability is affected. With GMS, system entry is constrained by platform rules.
Second, it must decide the position of Android apps inside the task stream. Does it keep a traditional Launcher, or put Launcher as a secondary entry? Does it always let users return to the app grid, or aggressively push Task Stream? The first generation probably must keep a fallback; otherwise users will feel unsafe at critical moments.
Third, it must solve permission credibility. If an OpenAI system assistant asks to read screen, notifications, calendar, location, photos, and messages, users will be highly sensitive. It must provide clearer explanations than ordinary Android permissions: which data is processed on device, which goes to the cloud, which is used only for this task, which will be remembered, and which will never be remembered.
Fourth, it must negotiate with top apps. Without structured capabilities, an OpenAI phone can only rely on GUI Agent to tap screens. If it relies on GUI Agent to tap screens, top apps will restrict it quickly. OpenAI must give service providers a reason: letting the Agent call you brings more transactions, less support cost, higher conversion, and divisible responsibility.
Fifth, it must manage hardware and model power consumption. If a ChatGPT-level experience continuously uses network, NPU, microphone, camera, and screen, users will feel heat and battery drain before they feel intelligence. The first hard metric of an Agent phone may become “after a full day always on, does the user still want to keep it enabled?” Model ranking is only part of the answer.
This is the difficulty of the Android route: it can become a phone faster, but is more easily dragged back by the old phone paradigm. A non-Android route can look more like Agent OS, but is harder to make into a phone.
5. Device-Cloud, Hardware, Industry, and Timeline
Doubao phone and device-cloud combinations such as OpenClaw/ArkClaw provide a useful observation point: AI phones need device and cloud to work together. They cannot stop at on-device model plus cloud chat.
The device-side role is not to run a small model for show. The device must do five things.
First, real-time sensing. Screen, notifications, location, camera, microphone, Bluetooth, sensors, foreground Activity, clipboard, and system settings are only known on device.
Second, low-latency judgment. Wake word, intent classification, risk judgment, simple summaries, on-device embeddings, and on-device VLM preprocessing require low power and low latency. They are not suitable for cloud every time.
Third, privacy closure. Payment credentials, biometrics, health data, private IM content, sensitive photos, precise location, and company-managed data cannot be freely read by the cloud. The device needs private compute areas and minimal context trimming.
Fourth, final confirmation. The Agent can suggest and prepare, but money, messages, orders, deletion, publication, and authorization often need user confirmation on device. Confirmation carries responsibility boundaries and cannot be treated as ordinary UI detail.
Fifth, interruption and braking. Users must be able to stop tasks, revoke grants, view history, and delete memory at any time. This control should be held by the device-side system, not hidden inside a cloud conversation.
The cloud’s role is not just “a larger model” either. The cloud must carry long tasks that the device should not bear.
First, long-running execution. Booking travel, organizing research, reviewing contracts, writing reports, editing videos, running code, comparing prices, and contacting multiple services are not one-request tasks. They may last minutes, hours, or days.
Second, tool environments. Browsers, code sandboxes, filesystems, crawlers, document processing, spreadsheets, image generation, and audio/video processing can be started from device, but should not all be hosted there.
Third, long-term memory. User preferences, style, common routes, work habits, family relationships, and project context need to accumulate across devices, sessions, and years. The device can store indexes and sensitive truths. The cloud can store memory graphs filtered by policy.
Fourth, Agent collaboration. Complex tasks split into sub-tasks: research, comparison, execution, verification, writing, scheduling, notification. The cloud is better suited to running multiple isolated sub-Agents at the same time.
Fifth, cross-device continuity. The user starts a task on phone, continues editing on computer, hears progress in earbuds, confirms a route in the car. The Agent should bind to user identity and task state, not a single device.
The device-cloud boundary needs a protocol layer containing task state, messages, Artifacts, permissions, data classification, push callbacks, failure recovery, and audit identifiers. Plain HTTPS APIs are not enough. A2A’s Task, Message, Part, Artifact, streaming, and push notification designs can be references. Android local execution may not use HTTP A2A, but these abstractions fit Binder or internal system services well.
From device-cloud division of labor, future Agent-phone SoC design will also change. In the past, phone chips emphasized CPU/GPU/NPU peaks, ISP, baseband, and power. Agent phones add several persistent pressures:
- Low-power NPU use from continuous context understanding.
- Memory pressure from multi-task state, embeddings, KV cache, and indexes.
- Always-on scheduling of camera, microphone, sensors, and model preprocessing.
- TEE/StrongBox/secure element hosting of credentials, payments, and private memory.
- Network, push, resume, and background wakeups from device-cloud round trips.
This explains why OpenAI, if serious about Agent phones, would care about processor co-design rather than only buying an off-the-shelf flagship SoC. AI Agent phone processors need to reallocate budget around continuous context, memory tiers, low-power sensing, and secure execution. They cannot be understood only as “phone chips with a larger NPU.”
Data Classification Decides Device-Cloud Routing
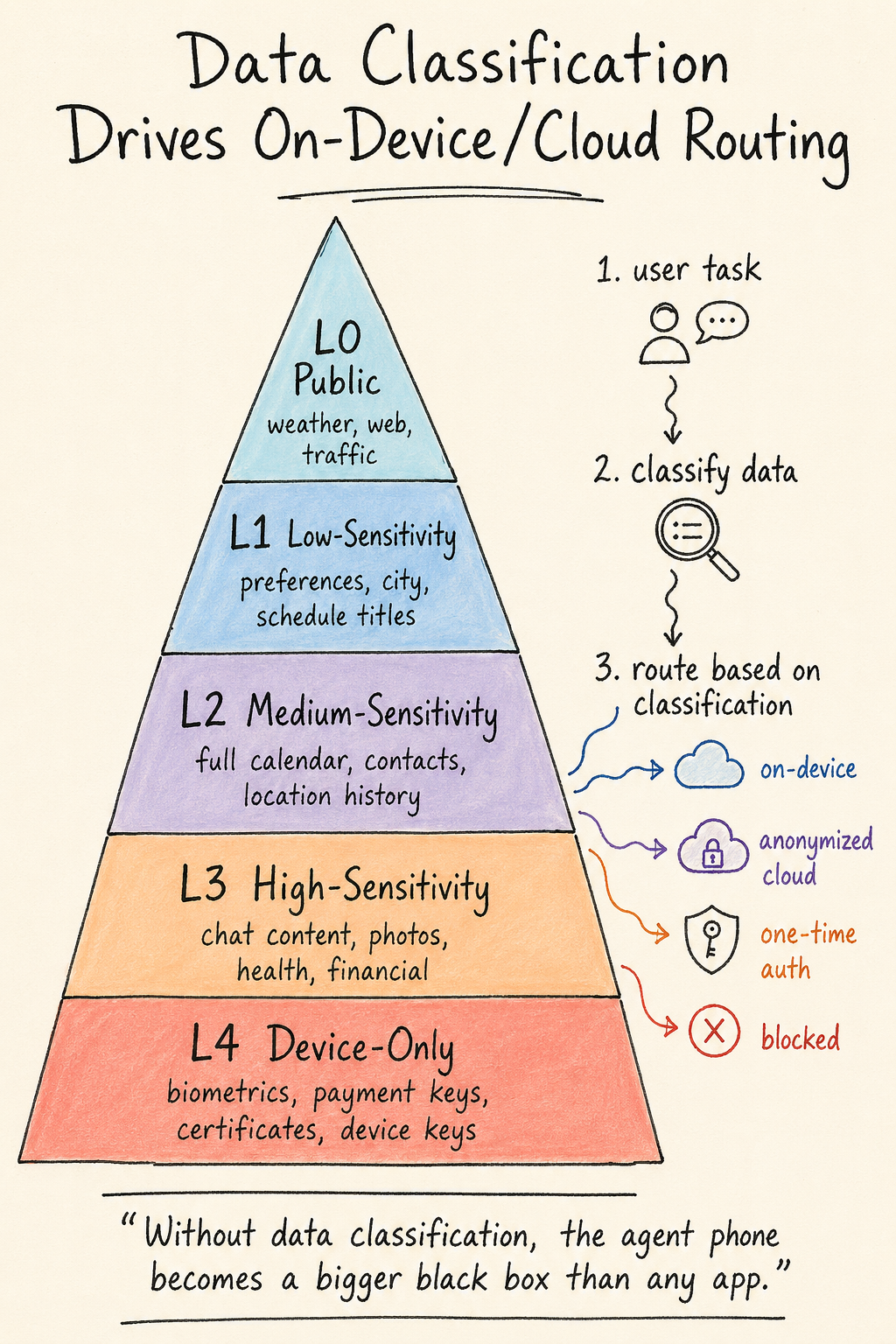
Device-cloud division should not be decided only by model size. A more reasonable method is to decide jointly by data sensitivity, real-time needs, task duration, and side-effect risk.
Phone data can be roughly split into five layers.
L0 is public data. Weather, public webpages, public product information, and public traffic information can be processed directly in the cloud.
L1 is low-sensitivity personal data. For example, a user-provided requirement, current city, preferred hotel type, or public calendar title. This can go to the cloud after authorization, but should have a purpose and expiry.
L2 is medium-sensitivity personal data. For example, full calendar, shopping history, common contacts, location history, file summaries, and work project names. This can go to the cloud, but should be trimmed, desensitized, or temporarily authorized by task.
L3 is high-sensitivity data. For example, chat content, original photos, health data, precise location, company files, family relationships, and financial information. This should be processed on device by default. Only when the user explicitly confirms and the task requires it should the minimum slice be sent.
L4 is data that must not leave the device. For example, biometrics, payment keys, Passkey private keys, bank verification codes, enterprise certificates, and device keys. This data can only be used inside the device security boundary. The cloud should receive at most “user confirmed” or “signature completed.”
Device-cloud routing should work like this:
1 | User task |
This mechanism sounds tedious, but it is the prerequisite for trust. Users already feel sensitive when authorizing an app to access the photo library. An Agent phone reads much more context. Without data classification, it becomes more black-box-like than any app.
Android vendors have an opportunity here: make data boundaries visible in system UI. For example, a task card can clearly show:
- This task used 2 images, 1 calendar event, and 3 public webpages.
- What went to the cloud was invoice fields, not the original album.
- Payment credentials did not leave the device.
- Temporary context will be deleted 24 hours after task completion.
- The user can delete Artifacts and memory in task history.
This UI does not have to be flashy, but it is more persuasive than a slogan about privacy.
Cloud Agent Is Not a Stateless API
Many phone teams are used to treating the cloud as an API: the device sends a request, the cloud returns a result. That model does not fit Agent phones.
Complex tasks need the cloud to keep state. When the user asks the Agent to research travel plans, the cloud opens webpages, records candidate hotels, compares flights, saves a budget table, waits for price changes, and generates itinerary documents. These intermediate states cannot be stuffed back into the prompt every time, and they cannot restart every time.
A cloud Agent is more like a user-specific workspace. It can be a combination of container, microVM, browser session, filesystem, vector database, task queue, and tool set. Each user’s task needs isolation. Each task’s files and credentials need isolation. When the task ends, cleanup must be possible.
This is where cloud Agent approaches such as OpenClaw/ArkClaw have value: the cloud gives the user a long-running execution environment, not just a larger model for the phone. It can run browsers, code, documents, spreadsheets, and image tools; it can continue while the user is offline; it can push back to the phone when confirmation is needed.
But this cloud shape also has three risks.
First is cost. An always-on or semi-always-on cloud Agent is much more expensive than ordinary API calls. Subscription, hardware bundling, task quotas, and enterprise payment will become part of the business model.
Second is security. The more tools a cloud Agent gets, the more it needs sandbox isolation, network access control, file access control, credential minimization, and prompt-injection defense. It cannot leak files or place orders for the user just because it read malicious instructions on a webpage.
Third is explainability. Users should not only know that “the cloud handled it for you.” They need to see task steps, call sources, generation basis, and final confirmation points. The longer the task, the less comfortable users become without explanation.
So device-cloud architecture cannot be simplified to “small device, big cloud.” The device handles scene, privacy, confirmation, and braking. The cloud handles long tasks, tools, memory, and concurrency. The protocol layer manages state, authorization, Artifacts, and audit.
Do Not Overstate or Understate the On-device Model
On-device models will not replace cloud models in the short term. Power, memory, thermal design, and cost constraints on phones mean they are not suitable for all complex reasoning. But on-device models are not supporting actors either.
They are best suited to five kinds of work.
First is wake and intent classification. When a user sentence arrives, the device first judges whether cloud is needed, whether privacy is involved, and whether the task can be handled locally.
Second is context trimming. The device trims screen, notifications, calendar, photos, and files down to the minimum slices needed by the task, then decides what can go to the cloud.
Third is privacy-sensitive understanding. Fraud-call detection, verification-code recognition, health anomaly prompts, private photo classification, and company-file summaries can be done or preprocessed on device.
Fourth is fast feedback. Translation, summaries, rewriting, simple Q&A, local image editing, and speech-to-text are latency-sensitive. On-device models have an advantage.
Fifth is failure fallback. When the network is down, weak, cloud-congested, or cloud permission is disabled, the device must provide a minimum usable capability.
This is also the value of processor co-design. Agent phones need not only high compute, but also low-power always-on models, fast cold start, model-weight sharing, embedding indexes, KV/cache management, and secure memory. NPU peak numbers only explain part of the experience. Continuous operation determines whether users keep the Agent enabled.
The Different Positions of Five Groups of Players
OpenAI’s position is the most special. It has models, consumer brand, subscription relationship, and global developer attention, with no traditional phone baggage. It can aggressively put Task Stream on the first screen, treat apps as background capabilities, bind subscription to hardware, and differentiate through cloud long tasks. Its problems are also clear: lack of local services, payments, maps, social networks, and channels; China almost certainly requires local partners; callable rights for apps need to be renegotiated; first-generation hardware reliability pressure is high.
Apple’s advantages are on-device hardware, system permissions, privacy brand, App Store, App Intents, and user trust. It does not need to radically change the home screen to weave Siri, Spotlight, notifications, Shortcuts, App Intents, and Private Cloud Compute together. Apple’s constraint is that it does not want to hurt the App Store or existing usage habits. It will be slow, but slow does not mean weak. If Apple makes task suggestions, App Intents, and system confirmation work well, user migration cost is low.
Google + Samsung is the standardization path for the Android camp. Google has Android, Gemini, AppFunctions, A2A, and cloud. Samsung has high-end hardware, Galaxy AI, Now Brief, Bixby, Now Bar, and global users. Samsung’s willingness to hand system entry to multi-Agent combinations makes it an important test bed for Android. The difficulty is dispersed interests: Google, Samsung, Qualcomm, MediaTek, OEMs, carriers, top apps, and regional regulators all influence system choices.
ByteDance Doubao is one of the most valuable samples in China. Doubao phone, system-level permissions, Virtual Display, UI-TARS, OpenClaw/ArkClaw internal directions, and the public-facing Coze Space-style cloud Agent environment push “AI operates apps for users” from slides to devices. Its value is not sales, but showing two things early: Agent phones are feasible, and third-party apps will push back. ByteDance has Chinese content, video creation, office tools, models, advertising, and e-commerce services, but no dominant mainstream phone OS. To move forward, it must go from “can tap screens” to “protocol calls, auditable authorization, and commercial distribution.”
Huawei, Xiaomi, OPPO, vivo, and Honor have system permissions, hardware, channels, local services, and compliance capability. They are well positioned to build a Chinese version of Agent OS, but are also most likely to build separate systems. If every vendor has its own skill protocol, memory format, AgentCard, payment confirmation, and task state, developers will relive adaptation hell. The Chinese Android camp should not rely only on one more AI assistant inside the ROM. It needs a relatively stable common language for capability declaration, permission authorization, task state, data classification, and audit records.
Another group cannot be ignored: top apps. They may not want to be called by Agents. For WeChat, Taobao, Alipay, Meituan, Douyin, banks, and games, the foreground entry point is a business asset. If an Agent takes the entry point away, platforms will worry that user relationships, ads, transaction share, risk control, and responsibility are all rewritten. In the next few years, the largest negotiation in Agent OS will happen among system vendors, AI vendors, and top apps. The question is how entry, data, and responsibility are redistributed.
The Real Constraints of the Five Groups
To avoid turning each company’s path into slogans, place them in one constraint table.
| Player | Strongest resource | Biggest constraint | More likely first form |
|---|---|---|---|
| OpenAI | Models, brand, subscriptions, cloud Agent | App callable rights, local services, hardware support | Task-stream-first AI phone or high-end task device |
| Apple | On-device hardware, OS, privacy, App Store | Cannot hurt App Store and existing habits | Siri + App Intents + system task suggestions |
| Google + Samsung | Android standards, Gemini, hardware, global channels | Dispersed camp interests and different OEM incentives | AppFunctions + Galaxy AI + Now Brief |
| ByteDance Doubao | Chinese content, cloud, models, video/office/e-commerce | No mainstream OS control, top-app resistance | System assistant + cloud OpenClaw + own services |
| Chinese OEMs | System permissions, channels, local compliance, hardware | Protocol fragmentation, model and service differences | ROM-level Agent + local service cooperation |
In this table, OpenAI’s advantage is the opposite of other players. Traditional phone vendors have phones but lack a strong enough Agent entry point. OpenAI has the Agent entry point but lacks the most troublesome service relationships in the phone world. It is moving from task entry toward hardware. Other vendors are moving from hardware and system permissions toward task entry.
The two sides will meet around 2028.
If OpenAI does well enough, it proves that “task stream first” is feasible. Traditional vendors will absorb its interaction and task model.
If OpenAI hardware fails, it still leaves boundary experience: which tasks users are willing to give to an Agent, which services must return to apps, which permissions users cannot accept, and which hardware forms do not fit always-on operation.
That is its disruptive value. It does not have to become the largest phone vendor to change the phone industry.
Why Supply-chain Signals Are Worth Watching
Kuo’s report puts MediaTek, Qualcomm, and Luxshare together. That is already beyond ordinary supply-chain gossip. If it is true, OpenAI’s target covers two layers: finding manufacturing partners, and participating in system design, SoC definition, and manufacturing coordination.
Agent phones will change SoC requirements.
Traditional flagship SoCs emphasize peaks: CPU single-core and multi-core, GPU, NPU TOPS, ISP, baseband. Agent phones need these too, but they care more about sustained load.
An always-on Agent will not run a big model once every ten minutes and stop. It will continuously listen for low-power events, maintain small context, frequently run embedding and rerank, occasionally call a VLM to inspect screen or camera, sync cloud tasks in the background, wait for push, and bring confirmation cards to the foreground.
This shifts pressure to several places.
First is low-power sensing. Voice, movement, location, Bluetooth, calendar, and notification events must be processed continuously without waking big cores and big models every time. Sensor hub, DSP, small NPU, and always-on island become more important.
Second is memory hierarchy. Model weights, KV cache, embedding indexes, task state, and screen semantic snapshots compete with traditional apps for memory. The difference among 8GB, 12GB, and 16GB will show up in background retention and whether multiple Agent sub-tasks can be carried at once.
Third is secure storage. Agents touch credential references, payment confirmation, private preferences, company materials, and identity tokens. StrongBox, TEE, secure elements, encrypted storage, and remote attestation move from “security specs” into user experience.
Fourth is network and push. Device-cloud tasks round-trip more often than ordinary app requests and depend more on reliable push. Task interruption, retry, weak-network recovery, roaming, and airplane-mode recovery all need design.
Fifth is heat and battery. Users will not accept a phone that heats up and drains visibly because AI is always on. Agent phone success may be decided by a plain question: if enabled by default all day, is battery life still trustworthy?
MediaTek and Qualcomm each have a position here. Qualcomm is strong in high-end Android, baseband, NPU, and global flagship cooperation. MediaTek is strong in cost, integration, and flexible cooperation with some OEMs. OpenAI contacting both can be reasonably understood as comparing different SoC definition paths, not necessarily having locked one traditional phone plan.
Luxshare’s role is also worth watching. It is not just contract manufacturing. If an AI Agent phone rewrites hardware interaction, it may involve new buttons, microphone arrays, sensor layout, thermal design, antenna space, secure-element placement, and always-on display strategy. System co-design matters more than ordinary ODM work.
But judgment should stay restrained. A supply-chain report being true does not mean the product will succeed. In hardware, prototype, EVT, DVT, PVT, mass production, channels, and support can all change direction. For Android practitioners, the more valuable observation is how OpenAI defines Agent phone SoC, permissions, entry point, and device-cloud division, rather than betting on phone sales.
2026 to 2032: What Is More Likely to Happen
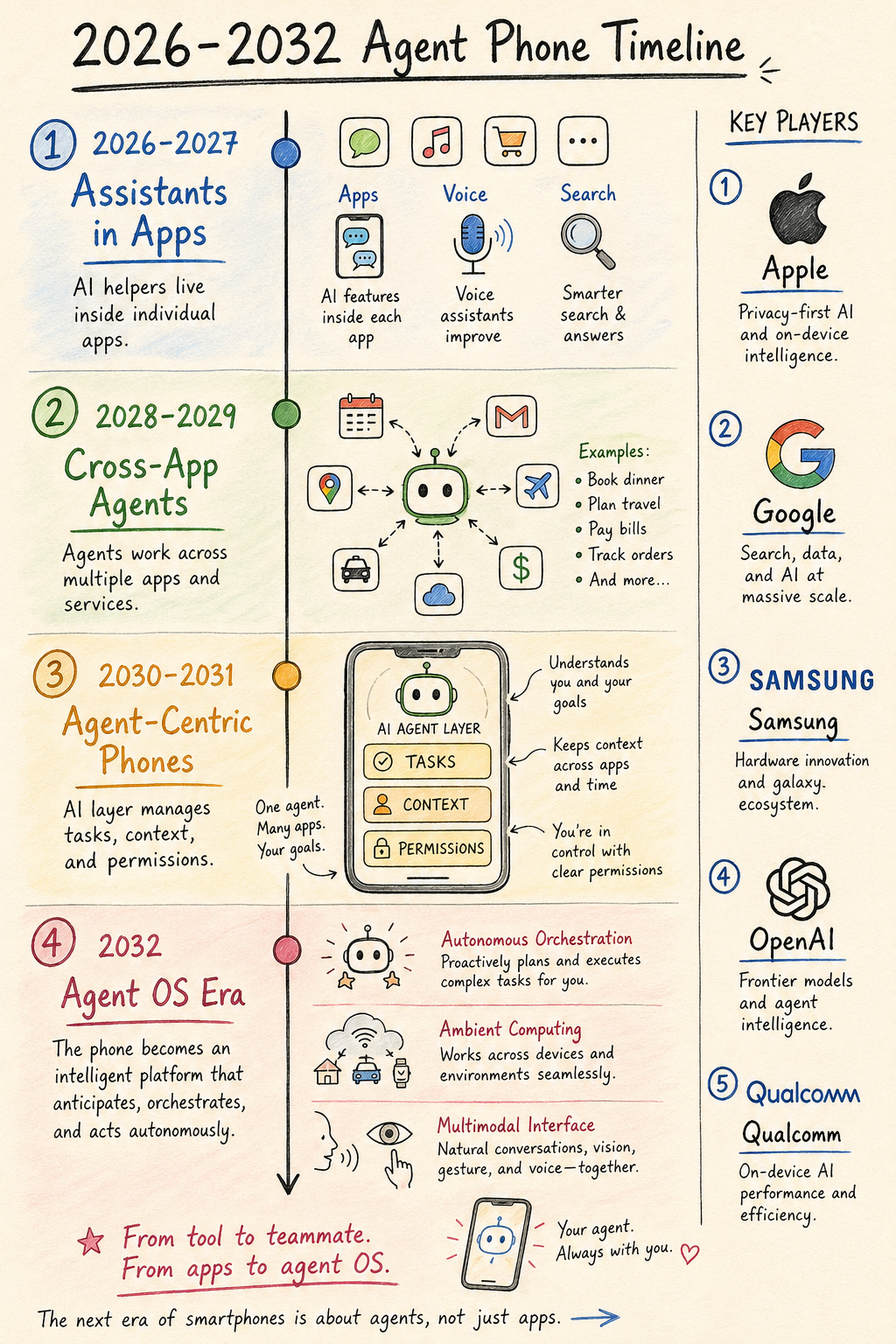
2026 to 2027 is the stage of “assistant moves forward, app grid remains.”
In this stage, vendors will hand long-press side buttons, voice, earbuds, lock screen, notifications, and floating entry points to AI assistants. Now Brief, Now Bar, system briefings, smart notifications, cross-app summaries, screen Q&A, on-device image editing, live translation, and meeting minutes will keep spreading. GUI Agents will appear in some tasks. AppFunctions / App Intents will expand from top scenarios.
The experience will be mixed. Many features will look like AI phones, but are still old OS plus assistant. Users will feel that “good tasks are amazing, bad tasks are awkward.” This stage first exposes four engineering gaps: task state, permission confirmation, capability routing, and failure recovery.
2028 may be the window for an external reference.
If an OpenAI phone enters mass production as Kuo reported, it may not immediately take mainstream share from iPhone or Galaxy. But it can provide an industry reference: can the home screen not start from apps? Can tasks become first-class OS objects? Can hardware subscription merge with cloud Agent? Can phone SoCs be designed around continuous context? Can users accept a more proactive task stream?
Even if OpenAI’s first phone has limited sales, it may play the defining-sample role that early Surface, Pixel, or Vision Pro played. It can expand review metrics from “camera, battery, screen, benchmark” to “task completion rate, confirmation design, privacy classification, long-task recovery, cross-device continuity, app callability.”
From 2029 to 2030, app entry points will begin to retreat more visibly into the background.
This does not mean app icons disappear. What is more likely is that high-frequency user operations are gradually absorbed by task streams. The home screen may have three persistent views: conversation, task, memory. Notification center becomes a task status panel. App Store gains a capability-store attribute. Developers submit not only apps, but callable functions, schemas, pricing, permissions, and result formats.
At that point, phone vendors will find that the Launcher problem has expanded from desktop layout into a task operating system. Whoever better understands user state, schedules capabilities, and controls risk owns the next entry layer.
From 2031 to 2032, multi-device Agents will begin to exceed single-phone Agents.
The phone remains central, but it is no longer the only entry. Glasses handle vision, earbuds handle voice, watches/rings handle physiological signals, cars handle travel, computers handle complex editing, TVs handle family content, and home devices handle spatial state. The phone becomes the identity, authorization, confirmation, and high-compute local node.
At that stage, the Agent OS object is no longer one device, but the user’s device group. A task starts on the phone, continues on the computer, reminds in earbuds, confirms a route in the car, and announces through the home speaker. The OS boundary expands from “device operating system” to “personal task system.”
Use Real Task Types to Test the Timeline
A timeline written only by year looks like a prediction list. A better way is to watch when different task types become stable.
The first type is information organization: meeting minutes, webpage summaries, notification organization, email drafts, travel plan comparison, information collection. These tasks do not depend heavily on high-risk actions or deep top-app interfaces. They will mature quickly in 2026-2027. They will be the first reasons users accept Agent phones.
The second type is light execution: creating calendar events, generating to-dos, saving files, sending to self, organizing albums, setting reminders, simple shopping comparison. These need system permissions and some app cooperation, but risk is low. They fit AppFunctions, App Intents, and system capabilities, and will enter high frequency around 2027.
The third type is transaction tasks: booking tickets, booking hotels, ordering food, hailing rides, buying products, canceling subscriptions, reimbursement, bill payment. These involve payment, price, after-sales, responsibility, and risk control. GUI Agent can demonstrate them first, but stable execution needs platform cooperation and structured capability. Large-scale stability may come after 2028.
The fourth type is social and content publishing: sending WeChat messages, replying to emails, posting to Weibo, Xiaohongshu, or Douyin, commenting, direct messaging. The risk here is not only technical, but also tone, relationships, and consequences. Agents can draft and suggest, but direct sending will be cautious. Before trust is built, confirmation is hard to remove.
The fifth type is high-sensitivity tasks: banking, securities, insurance, healthcare, government services, company approval, contract signing, identity authentication. These will open latest and best test Agent OS permission and audit design. Without strong confirmation, strong audit, and strong responsibility boundaries, platforms will not let them in.
The development speed of these five task types is more valuable than the question “which year will Agent OS appear?”
From 2026 to 2027, information organization and light execution mature.
From 2028 to 2030, transaction tasks begin to be stably absorbed by system-level Agents.
After 2030, social delegation and high-sensitivity tasks may open within specific boundaries.
This also explains why even if OpenAI’s first phone exists, it will not replace all apps at the beginning. It is more likely to make information organization, long tasks, research, creation, and light execution strong first, then gradually touch transactions and high-sensitivity tasks.
6. Product Shape, Market Split, and Responsibility Distribution
If the Agent OS phone from 2028 to 2032 is compressed into one product shape, it probably will not be a full-screen chatbot.
Chat must remain because natural language is a low-cost entry. But chat is not the destination. Users do not want to talk to the phone all day. They want the phone to interrupt less, switch less, forget less, and ask for repeated input less.
The more likely first screen is a task stream.
In the morning, the phone shows tasks that need confirmation today: flight-change suggestions, meeting-material summaries, children’s school materials, bill due reminders, fitness plan, and research results completed by the cloud last night. Each task has state, source, next step, risk, and confirmation button.
During the day, the user says, “Mark the contract risks in this PDF and give me a shareable version before 3 p.m.” The phone sends the file to a cloud sandbox, keeps sensitive-field indexes on device, and the cloud generates the report. When complete, it pushes back a task card. After user confirmation, the system calls an office app to send it.
At night, the user says, “Take my parents to Yunnan next month, do not make it tiring, budget 15,000.” The cloud runs routes and hotels. The device reads family calendar and weather preferences. Hours later, the system provides three plans. The user does not need to stay in the chat window.
Behind these experiences are three UI levels.
The first is Task Stream. It combines home screen, notifications, and lock screen, managing tasks that wait for confirmation, are running, are completed, or failed.
The second is Capability View. Users or developers can view which apps, services, and Agents can be called, what they can do, what permission range they have, and what price and risk they carry.
The third is Memory View. Users can see preferences, projects, relationships, common information the Agent remembers, and can edit or delete them.
These three views will gradually replace part of app-grid time. The app grid remains, just as filesystems and command lines remain. It is simply no longer the starting point for most users to complete tasks.
What the First Screen May Become

The first screen is unlikely to be only one big chat box. A pure chat entry has two problems: users must constantly express themselves, and task state is invisible.
A more reasonable first screen may have four blocks.
The first block is current tasks. It shows running, waiting-for-confirmation, and near-deadline tasks. Each task card has source, state, next step, and risk prompt.
The second block is today’s state. It summarizes calendar, weather, travel, health, messages, bills, and family matters without filling the screen with everything.
The third block is quick expression. Users can create new tasks through voice, text, screenshot, photo, or shared content.
The fourth block is app fallback. Users can still open the traditional app grid, especially when the Agent is unreliable, when the user wants to operate manually, or when the task is high-risk.
The ratio among these four blocks will vary by user. Heavy users rely more on task stream. Conservative users still center on the app grid. The system should not force everyone into Agent mode immediately.
The Position of Generative UI
Future phone interfaces will not choose only between app UI and chat UI. Generative UI will become part of task results.
When the user says, “Give me three family-trip plans for Yunnan,” the system should not only return a paragraph or jump to an app. A better result is an interactive panel: budget, route, hotel, transport, elder-friendliness, cancellation policy, weather risk, and options needing confirmation. The user can adjust preferences inside the panel, and the Agent continues execution.
When the user says, “Rewrite this report for my boss,” the system can generate a comparison view, revision suggestions, source references, risk prompts, and one-click export, instead of dumping a new paragraph into chat.
The key to Generative UI is turning intermediate task state into an operable interface, not showing off. This lets users participate in decisions instead of handing all judgment to the model.
For Android, Generative UI raises new questions for View/Compose/WebView: where does the UI come from, who is responsible for security, can it call system capabilities, can it embed third-party services, can it be screenshot-audited, and can it recover offline? Eventually it still returns to Task, Capability, Policy, and Artifact.
Memory View Becomes the Trust Entry
The smarter an AI phone becomes, the more users will ask one question: why do you know that?
This makes Memory View crucial. Users need to see what preferences, projects, contact relationships, common addresses, writing style, and travel taboos the Agent remembers. They also need to edit, delete, and pause memory.
Memory UI should not be buried like a privacy list in Settings. It should become one of Agent OS’s common interfaces. Memory is the long-term contract between user and Agent. Backend technology is only one part.
A good memory interface should support:
- Viewing by topic: travel, work, family, health, shopping, writing.
- Viewing by source: from conversation, calendar, files, or manual user input.
- Viewing by sensitivity: ordinary preference, high-sensitivity information, data that must not leave the device.
- Expiry: some preferences are valid only for this trip, project, or month.
- Correction: users can say “this is not my preference, it was a one-time situation.”
Without Memory View, the Agent gradually becomes an unexplained black box. With Memory View, users may be willing to hand it more tasks.
China Will Follow an Independent Path
After product shape, China needs a separate look. The China market will not simply copy OpenAI’s phone route.
First, OpenAI can hardly enter China’s primary-phone market directly. Model compliance, data cross-border rules, app stores, local payment, maps, IM, local-life services, government relations, and carrier relations are each complex enough.
Second, Chinese users’ high-frequency services concentrate in a small number of super apps and local platforms. An Agent that wants to finish tasks must deal with WeChat, Alipay, Taobao, Meituan, Douyin, JD, Didi, banks, and government services. This involves technical, commercial, and compliance problems at the same time.
Third, Chinese Android vendors have stronger ROM customization capability and more complex vendor fragmentation. Each can build its own AI assistant, but without common capability standards, developers and top apps will not want to adapt separately for each vendor.
Fourth, the Doubao route will remain referential. It connects system permissions, Chinese content, cloud Agent, GUI automation, and its own app network, showing that Chinese companies may build a different Agent phone from Apple/Google/OpenAI. It also reminds everyone that the right to be legally called by other apps may be scarcer than model parameters.
The China market is more likely to have multiple forces coexist:
- Huawei follows its own system and services on HarmonyOS NEXT.
- Xiaomi, OPPO, vivo, and Honor strengthen system Agents in Android/AOSP systems.
- ByteDance, Tencent, Alibaba, Meituan, and other service platforms provide their own Agent capabilities and developer tools.
- Top apps defend against GUI automation, but open structured capabilities when commercial returns are clear.
- Domestic protocols borrow from A2A/MCP/AppFunctions while adding local compliance, data classification, real-name, payment, and risk-control fields.
This path will not be as clean as OpenAI’s ideal, but it will fit Chinese service reality better. For Android phone practitioners, the more important question is whether system permissions, on-device models, domestic cloud, top apps, payment confirmation, and task audit can combine into a credible execution system, not whether another ChatGPT is rebuilt.
Three Product Lines in China
China is more likely to have three product lines at the same time, not one Agent OS.
The first is the OEM system-assistant line. Huawei, Xiaomi, OPPO, vivo, and Honor will keep moving assistants into the system layer, connecting photos, notifications, calendar, files, cars, homes, and wearables. Their advantage is system permissions and hardware entry. Their weakness is that model and service coverage may not be strongest.
The second is the service-platform Agent line. ByteDance, Tencent, Alibaba, Meituan, Baidu, JD, and others will package their content, transaction, office, and local-life capabilities into Agents or tools. Their advantage is services and user behavior. Their weakness is that they do not get full system permissions and may not become the default entry.
The third is the enterprise and vertical Agent line. Finance, healthcare, government, education, manufacturing, and retail will have their own controlled Agents. They care more about compliance, data boundaries, and audit, and will not easily integrate with consumer general assistants.
These three lines will cooperate and guard against each other. OEMs want to be the default entry. Service platforms want to protect user relationships. Industry systems want to keep data boundaries. Whether Agent OS becomes large in China depends not only on model level, but also on whether these three lines can form an acceptable cooperation model.
For users, the best experience is a system-level Agent that can call multiple platform services. For platforms, the safest method is to expose controlled capabilities, not all data and UI. For regulators, the most acceptable design is that every high-risk action has identity, authorization, audit, and responsibility. The overlap acceptable to all three parties is the viable area for China’s Agent phone.
What Doubao Phone Reminds the Industry
The biggest value of Doubao phone is not that it “built an AI phone,” but that it exposed a group of hidden problems early.
First, system-level permissions are useful. Without them, an Agent can hardly understand the screen, operate apps, receive notifications, or maintain background tasks. The capability gap between an AI app and a system Agent is large.
Second, GUI Agent is impactful. It lets users see for the first time that “the phone can really operate apps for me.” Even if unstable, it changes imagination.
Third, top apps will push back. Platforms will not unconditionally accept an external Agent entering their transaction, social, and content scenarios. They will restrict it from security, risk control, user experience, and commercial-interest angles.
Fourth, an owned service network matters. ByteDance can connect Doubao, Douyin, Jianying, Feishu, Volcano Engine, content, and ads, so it has more service support for an Agent phone than a pure hardware vendor. If other OEMs rely only on models and system permissions, service depth will be insufficient.
Fifth, user acceptance may be higher than expected, but trust building will be slower than expected. Users will be attracted by “it can help me tap apps,” while also worrying about “what did it see, will it tap randomly, will it leak data?”
These five points matter for all Android vendors. Agent phones will not stay in the smooth execution shown in promotional videos. They will repeatedly balance system permissions, third-party relationships, and user trust.
Several Boundary Judgments
After product and market, the boundaries should be put on the table.
First, Agents will not replace apps all at once. They will replace entry points first, then part of cross-app operations, and only later change app business forms. Apps remain service providers, but must accept being called by system-level Agents.
Second, GUI Agent is a necessary transition, not the long-term answer. It can prove demand and cover long-tail apps, but it should not carry high-risk actions. The long-term answer is structured capability, system-level authorization, and auditable tasks.
Third, on-device privacy becomes a brand differentiator. Users can accept smarter Agents, but not secret learning and secret execution. Which data stays on device, which goes to cloud, who can audit, how deletion works, and how errors are traced must be clear from day one.
Fourth, OpenAI’s hardware value may not come from sales. It is more like an industry pressure source. As long as it produces a daily-usable task stream, Android vendors and Apple will be forced to explain why their OS still starts from an app grid.
Fifth, Android’s opportunity is standardization. If AppFunctions, A2A, MCP, on-device model services, permission systems, task state, and notification entry points form a stable combination, Android does not need each vendor to build a private Agent OS. Conversely, if every vendor privatizes it, developers will escape back to web and top platforms.
Sixth, a non-Android route has a chance, but is hard to become a primary phone directly. It may first appear as a high-end AI device, companion device, or narrow work phone. Only after app compatibility, service coverage, and trust mechanisms are complete can it move into primary-phone position.
Seventh, Agent OS competition expands from models to systems. Models determine the ceiling of understanding and planning. OS determines whether the Agent can see state, call capabilities, obtain authorization, execute actions, recover failures, and take responsibility. A model without OS permission can only wait for the user to bring problems to it. An OS-constrained Agent can keep working inside the user’s life.
Back to OpenAI: Why Its Disruption Matters
Now return to OpenAI building a phone. The point is no longer only whether the hardware rumor is true. It puts industry questions back on the table. If the device is eventually confirmed, there are roughly two outcomes.
One outcome is an AI Agent phone based on Android or Android compatibility. Then it gives the Android camp an assignment: why can an outsider put task stream on the first screen while traditional OEMs still stuff AI features into Settings, Gallery, and assistant apps?
The other outcome is a more Agent OS-like new device without Android. Then it gives the industry another assignment: without app-grid history, how should a phone or portable device organize tasks, memory, permissions, and cloud execution?
Whichever path happens, it makes the phone industry ask the right question.
For more than ten years, phone OS competition has centered on screens, apps, imaging, performance, and services. Over the next few years, competition will gradually move toward: who can manage user state, who can organize tasks, who can make apps reliably expose capabilities, who can draw privacy boundaries between device and cloud, and who can make users trust a system that acts proactively.
From an Android phone practitioner’s perspective, Agent OS will not overturn Android or iOS overnight. More likely, Android and iOS both grow parts of Agent OS. OpenAI, ByteDance, Google, Apple, Samsung, Huawei, Xiaomi, OPPO, vivo, and Honor all start from their own resources and compete for the task entry point.
The risk is that the industry keeps understanding AI phones as a set of feature points. If the industry only builds AI summaries, AI photo editing, AI search, and AI voice assistants, then once OpenAI builds a usable Task Stream, it will push the problem into the system layer.
This pressure will not stay inside OS vendors. Once Task Stream enters the home screen, apps must answer whether they are willing to be called. Service platforms must answer how transactions and attribution are shared. The system must answer who is responsible after mistakes. So the next thing to watch is how developers, business, and responsibility are redistributed.
Developers, Business, and Responsibility Will Be Redistributed
Agent OS changes the relationship between developers and platforms.
In the app era, developers competed for install, open, dwell time, payment, and return visits. App icon was the entry. Push was recall. App stores were distribution. Ads and subscriptions were monetization.
In the Agent OS era, developers must compete for a new thing: being selected by the Agent.
When the user says “order a bouquet for me,” which service does the system choose? By price, distance, reputation, fulfillment, historical preference, platform partnership, commission, or the user’s past habit? This selection power used to belong to the user and search/app stores. It may move to Agent and system.
This will bring new developer interfaces.
Apps need to declare capabilities: I can order flowers, check inventory, book, cancel, refund, and issue invoices.
Apps need to declare constraints: which cities are available, which actions need login, which actions need user confirmation, and when cancellation is unavailable.
Apps need to declare price and share: how orders brought by Agents are attributed, whether the system or AI platform takes a commission, and whether coupons can be used.
Apps need responsibility interfaces: who is responsible for order failure, how refunds are handled, where customer support entry is, and how audit logs connect.
This is not a pure technical API. It changes the app’s business position.
Top apps will worry about losing entry, so they will require brand display, user confirmation, transaction attribution, and risk-control authority. Smaller apps may be more willing to integrate because Agents can bring new traffic. System vendors will want to build capability stores. AI vendors will want to own the task entry point.
Developer platforms also change. Future developer docs will not only teach UI writing. They will teach capability schemas, callable action definitions, Artifact returns, Agent-induced error handling, sandbox testing, and revenue sharing.
Android AppFunctions is the beginning of this direction. It lets apps expose capabilities to systems and Agents. To support full Agent OS, more complicated business and responsibility layers are needed.
The New Ranking Problem
Agent OS creates a ranking problem similar to search.
When the user says, “Find a nearby restaurant suitable for kids,” which restaurant does the Agent choose? User preference, friend recommendation, platform ranking, ads, commission, or model judgment? If Agent results affect transactions, transparency and fairness appear.
In the search era, users could see multiple links. In the app era, users could open multiple apps and compare. In the Agent era, if the system directly gives one suggestion, the selection process becomes less visible.
This creates new product requirements:
- Mark commercial recommendations.
- Allow users to see candidates.
- Allow users to specify preferences and disable platforms.
- Provide comparison basis for high-value transactions.
- Keep audit records for enterprise and regulatory scenarios.
OpenAI, Google, Apple, Android OEMs, ByteDance, Alibaba, Tencent, and Meituan will all face pressure here. Agents save users time, but cannot turn user choice into invisible commercial allocation.
Responsibility Spreads from Apps to the System
When a traditional app fails, responsibility is relatively clear. If food delivery is wrong, find the food-delivery platform. If payment fails, find the payment platform. If navigation is wrong, find the map. The OS mostly provides capabilities and security boundaries.
When Agent OS fails, responsibility becomes more complicated.
If the Agent misunderstands the user and books the wrong hotel, is the model responsible or the user?
If the Agent understands correctly but calls a more expensive service, is the system recommendation responsible or the service platform?
If GUI automation taps the wrong button, is the executor responsible, the app UI change responsible, or the system responsible for missing second confirmation?
If a cloud Agent is induced by webpage prompt injection and leaks user files, is the cloud sandbox, model, webpage, or user authorization responsible?
These questions force system design. Not every action can be automatic. Not all data can enter the model. Not every result can be submitted directly. Agent OS must treat “high-risk actions require confirmation” as a base rule, not a post-launch popup.
High-risk actions will keep user confirmation for a long time. Payment, messaging, publishing content, deleting data, signing contracts, submitting government services, financial trading, and medical advice will not become fully automatic quickly. The Agent can prepare, compare, fill forms, and explain, but the last step should return control to the user.
Keeping confirmation rights for high-risk actions with the user is a prerequisite for sustainable Agent OS.
Observations from an Android Phone Practitioner’s Perspective
This section does not need to become an action plan. Professional teams already understand side-button entry, permission UI, on-device models, cloud tasks, and developer interfaces. The more valuable move is to narrow the observation angle: in the next few years, the Android camp’s test point will shift from “is there an AI assistant” to whether AI can enter the system object model.
The first observation point is Task. If tasks still exist only inside chat history, the Agent cannot really enter the system layer. Only when tasks have state, progress, Artifacts, cancellation, recovery, and history can they enter home screen, notifications, lock screen, car, and watch.
The second observation point is Capability. GUI Agent will continue to exist, but it is more like a compatibility path. Stable experience depends on whether AppFunctions, AgentCard, MCP tools, system-private capabilities, and top-app partnership interfaces can be uniformly indexed, routed, and audited.
The third observation point is permission and memory. The stronger an Agent phone becomes, the more it must explain “what data this task used, which data went to the cloud, which stayed on device, which will be remembered, and which can be deleted.” This must land in system UI and audit records, not stay as a privacy slogan.
The fourth observation point is device-cloud state. If a cloud Agent is only a stateless chat API, it cannot carry long tasks. The device cannot be only an entry point either. It must handle scene, confirmation, braking, and sensitive-data boundaries. What syncs between device and cloud should be tasks, Artifacts, authorizations, and audit, not an ever-growing chat context.
If an OpenAI phone appears, its meaning for Android may be here: it may not answer every question well, but it will make the industry see the importance of these system objects again. For practitioners, this section is a prompt: do not only look at how many AI features a launch event adds. Look at whether task, capability, permission, memory, and device-cloud state become OS-managed objects.
Final Judgment
Return to the five things in the introduction: state understanding, capability providers, task runtime, device-cloud division, and cross-boundary execution. Compress the whole article into six sentences.
First, phones will not be replaced by Agents. Phones will become the Agent’s most important state node.
Second, apps will not disappear, but their foreground entry role will gradually decline, while capability interfaces gain weight.
Third, Android’s short-term path keeps the existing system and adds a task system across Framework/SystemUI/permissions/notifications/on-device models/cloud protocols.
Fourth, OpenAI may or may not build on Android. Without Android, it has more freedom but a harder time carrying app services. With Android, it enters the phone market faster but is constrained by the old system.
Fifth, Agent OS success depends not only on models, but on task runtime, capability routing, data classification, user confirmation, audit, device-cloud collaboration, and developer relationships.
Sixth, if an OpenAI phone appears around 2028, its greatest impact may come from the sample of a “task-stream-first phone.” Sales may not be the only metric.
For Android phone practitioners, this is not a distant concept. Every system AI entry point, permission dialog, AppFunction, on-device model service, and notification redesign being built now will decide whether the future Agent OS can be caught.
If AI phones are still understood as a collection of gallery, search, summary, and voice-assistant features, this change will be underestimated.
If they are understood as “phones starting to manage tasks,” the question becomes much clearer.
The next phone’s first screen may not immediately lose apps.
But it will look less and less like an app display case.
It will look more like a task entry point that is constrained by the system, authorized by the user, and able to keep working.
References and Sources
- Ming-Chi Kuo’s supply-chain report about OpenAI, MediaTek, Qualcomm, Luxshare, and a 2028 AI Agent phone: Frandroid, Techritual, Qore
- OpenAI and Jony Ive / io hardware background: OpenAI - A letter from Sam & Jony, NPR
- Android AppFunctions documentation: Android Developers - AppFunctions
- A2A protocol materials and Linux Foundation news: A2A Protocol, Linux Foundation A2A project
- Samsung Galaxy AI and system-entry direction: Samsung Newsroom, Samsung MWC 2026
- Doubao phone, Nubia M153, and third-party app restrictions: SCMP, TechNode, Business Standard